

Table of Contents
Looker is a powerful tool for self-service data analytics. A lot of companies use Looker together with Amazon Redshift for powerful business intelligence and insights. By making it easy for users to create custom reports and dashboards, Looker helps companies derive more value from their data.
Unfortunately, “slow Looker dashboards” is one of the most frequent issues we hear with Amazon Redshift. Some of our customers who use Looker tell us that queries that should take seconds to execute instead take minutes, while dashboards seem to “hang”.
The good news is that we can probably help: the issue is likely a mismatch between your Looker workloads and your Amazon Redshift configuration. In this post, we’ll explain the causes of slow Looker dashboards, and how to fine-tune Amazon Redshift to get blazing-fast performance from Looker.
The Problem: Slow Looker Dashboards
Analytics stacks often grow out of a simple experiment. Somebody spins up an Amazon Redshift cluster, builds a few data pipelines, and then connects a Looker dashboard to it. The data is popular, so you set more people up with dashboards—and at some point, the problems start.
Looker performance issues can range from slow dashboards to long execution times for persistent derived tables (PDTs). In some cases, these problems can even appear at the very start of the journey. Consider this post on the Looker forum, which complains that “first-run query performance is terrible”:

The key to solving bottlenecks lies in balancing your Looker workloads with your Redshift setup. First, let’s discuss how Amazon Redshift processes queries, and then we’ll look closer at how Looker generates workloads.
Amazon Redshift Workload Management and Query Queues
A key feature in Amazon Redshift is the workload management (WLM) console. Redshift operates in a queuing model. The WLM console allows you to set up different query queues, and then assign a specific group of queries to each queue.
For example, you can assign data loads to one queue, and your ad-hoc queries to another. By separating your workloads, you ensure that they don’t block each other. You can also assign the right amount of concurrency, a.k.a. “slot count,” to each queue.The default configuration for Redshift is one queue with a concurrency of 5.
It’s easy to overlook WLM and queuing when getting started with Redshift. But as your query volumes grow and you run more than 5 concurrent queries, your queries will start to get stuck in the queue as they wait for other queries to finish. When that happens, you’re experiencing the “slow Looker dashboards” phenomenon.
Slow Looker Dashboards: Understanding LookML and Persistent Derived Tables
There are two components of the Looker platform, LookML and persistent derived tables (“PDTs”), that make it easy for a company to explore its data.
But we’ll see how they can also generate high query volumes with heavy workloads that can slow down your Redshift clusters.
LookML – Abstracting Query Structure from Content
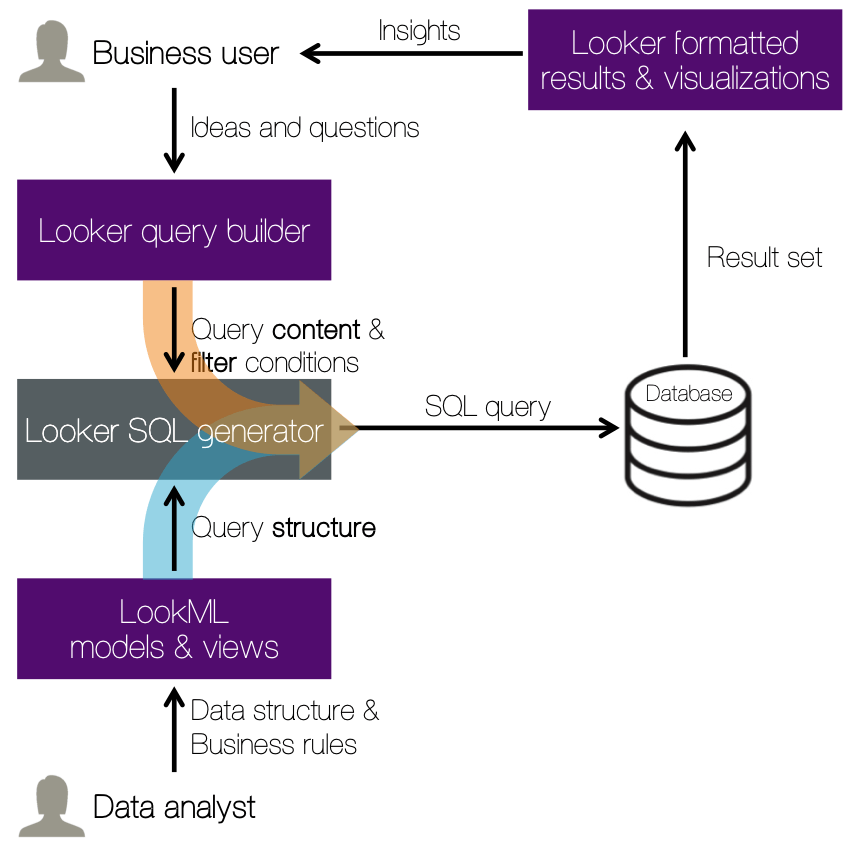
LookML is a data modeling language that separates query structure from content. In other words, the query structure (e.g. how to join tables) is independent of the query content (e.g. what columns to access, or which functions to compute). A LookML project represents a specific collection of models, views and dashboards. The Looker app uses a LookML model to construct SQL queries and run them against Redshift.
The benefit of separating structure from content is that business users can run queries without having to write SQL. That abstraction makes a huge difference. Analysts with SQL skills only define the data structure once in a single place (a LookML project), and business users then leverage that data structure to focus on the content they need.Looker uses the LookML project to generate ad-hoc queries on the fly. The below image illustrates the process behind LookML:
Persistent Derived Tables
Some Looks create complex queries that need to create temporary tables, e.g. to store an intermediate result of a query. These tables are ephemeral, and the queries to create the table run every time a user requests the data. It’s essential for these derived tables to perform well, so that they don’t put excessive strain on a cluster.
In some cases where a query takes a long time to run, creating a so-called PDT (“persistent derived table”) is the better option. Looker writes PDTs into a scratch Redshift schema, and refreshes the PDT on a set schedule. Compared to temporary tables, PDTs reduce query time and database load, because when a user requests the data from the PDT, it has already been created.
There’s a natural progression from single queries to PDTs when doing LookML modeling. When you’re starting out, you connect all tables into a LookML model to get basic analytics. To get new metrics or roll-ups and to iterate quickly, you start using derived tables. Finally, you leverage PDTs to manage the performance implications.
Slow Looker Dashboards: The Impact of LookML and PDTs on Query Volume
The separation of structure from content via LookML can have dramatic implications for query volume. The SQL structure of one productive analyst can be reused by countless other users.
A Simple Math Example
Consider a simplified scenario with a single-node Amazon Redshift cluster, 5 business users, and a single LookML project. Each user has 10 dashboards with 20 Looks (i.e. a specific chart). Behind each Look is a single query. With each refresh, they will trigger a total of 5 (users) * 10 (dashboards) * 20 (looks) = 1,000 queries.
With a single-node Amazon Redshift cluster and a default WLM setup, you will process 5 queries at a time. You’ll need 1,000/5 = 200 cycles to process all of these queries. While 5 of these queries process, all of the other ones will have to wait in the queue. The below image shows a screenshot from the Integrate.io dashboards that shows what your queue wait times can look like.

Let’s assume each query takes 15 seconds to run. For all queries to run, we’re looking at a total of 200 * 15 = 3,000 seconds (50 minutes). In other words, your last 15-second query will finish running after 50 minutes.
Even if you add a node now, i.e. you double the amount of queries you can process, you’re only cutting that total wait time in half—that’s still 25 minutes.
Now let’s also add PDTs into the mix. Our PDTs will generate more workloads, often with complex, memory-intensive and long-running queries. The PDTs then compete with the already slow ad-hoc queries for resources.
There are a few possible remedies: for example, throttling the number of per-user queries, reducing the row limit for queries, or allowing fewer data points. But the whole point of using Looker is to derive meaningful conclusions from huge amounts of data. Imposing query and row limits, or using fewer data points, doesn’t make sense.
3 Steps to Configure your Amazon Redshift Cluster for Faster Looker Dashboards
The good news is that there are only 3 steps to getting faster Looker dashboards:
- Optimize your Amazon Redshift WLM for your Looker workloads.
- Optimize your Looker workloads.
- Optimize your Amazon Redshift node count.
By following these 3 steps, you’ll also be able to optimize your query speeds, your node count, and your Redshift spend.
Step 1: Optimize the Amazon Redshift WLM for Looker Workloads
We’ve written before about “4 Simple Steps To Set-up Your WLM in Amazon Redshift For Better Workload Scalability.” The 4 steps, in summary, are:
- Set up individual logins for each user.
- Define the workload type for each user (e.g. load, transform, ad-hoc).
- Group users by their workload type.
- Create one queue per workload type, and define the appropriate slot count and memory percentage for each queue.
The same logic applies for your Looker queries. Have your Looker queries run in a queue that’s separate from your loads and transforms. This will allow you to define the right concurrency and memory configuration for that queue. Having enough concurrency means each Looker query will run, while having enough memory means that you’ll minimize the volume of disk-based queries.
During peak times, Concurrency Scaling for Amazon Redshift gives your Redshift clusters additional capacity to handle any bursts in query load. Concurrency scaling works by off-loading queries to new, “parallel” clusters in the background. Queries are routed based on their WLM configuration and rules.
In your intermix.io dashboard, you can see the high watermark/peak concurrency for your Looker queries. You’ll also see how much memory they consume, telling you what memory percentage you should assign to each slot.
By using the right settings, you can balance your Redshift usage with your Looker workloads. Doing this step alone will give you much faster dashboards.
Step 2: Optimize Your Looker Workloads
What is a redundant Looker workload? It’s a query that’s running but doesn’t need to be (for example, if users are refreshing their dashboards more frequently than they need). By reducing that refresh rate, your Redshift cluster will have to process less queries, which in turn drives down concurrency.

With intermix.io’s app tracing feature, you can see which of your Looker users are driving most of the query volume, down to the single Look. Below, you can see feedback from one of our customers during our private beta for app tracing:

Step 3: Optimize Your Amazon Redshift Node Count
Once you’ve squeezed all the juice out of your WLM, it’s time to adjust your Redshift node count. If you’re still encountering concurrency issues or disk-based queries, it may be time to add more nodes. In most cases, though, there’s an opportunity to reduce node count and save on your Redshift spend.
Consider the case of our customer Remind, a messaging app for schools. By configuring their workload management, they managed to reduce their Amazon Redshift spend by 25 percent.
That’s it! There are a few more tweaks you can do that will improve performance. Examples are setting your dist/sort keys for your PDTs, or moving some PDTs into your ELT process. But the 3 steps in this post will give you the biggest immediate return on your Looker investment.
Ready to scale, get fast dashboards, and handle more data and users with Looker?
Sign up today for a free trial of intermix.io. As your company grows, you can be confident that your Looker dashboards will always be lightning fast.




