
Papertrail is a cloud-hosted log management service. We use it internally for debugging and eat our own dogfood by processing the logs on Integrate.io, our data integration platform on the cloud. You too can use Integrate.io to analyze and aggregate Papertrail logs.
In the following example we'll analyze Heroku logs as collected by Papertrail to return various run-time metrics such as file sizes and the number of log pages:
-
If you don't use Papertrail yet, sign up and configure your account.
-
Papertrail automatically stores the logs on Amazon S3. Please refer to Papertrail's documentation on how to setup the connection.
-
Login to your Integrate.io account. If you don't have one, sign up for free.
-
Click My Packages at the top menu.
-
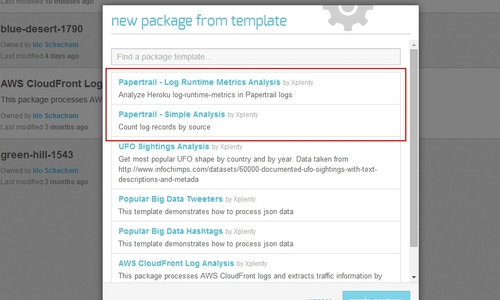
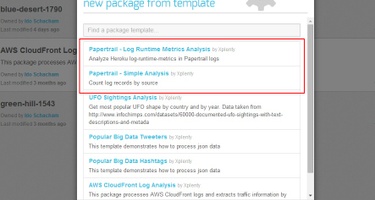
Click the little arrow next to the New Package dropdown on the top right and choose From Template. Select the desired Papertrail template from the two available (you will be able to modify it once the package is created):
-
Papertrail Log Runtime Metrics Analysis - We'll use this template.
-
Papertrail Simple Analysis - counts log records by source.
-
-
After the package has been created, click the source component named Events:
-
Under Source Location, choose the cloud storage connection on the left. If it isn't available, create a new connection to your Amazon S3 account.
-
Enter the bucket and path for your logs on Amazon S3.
-
Click the green test connection button above to make sure it works. If it doesn't, please review the connection, bucket, and path details.
-
Auto-detect the schema by clicking the green button on the top right. Once again, if it doesn't work then the source location details are probably not set correctly. Also try clicking the data preview button next to it to see that the log data is OK.
-
-
Back in the package screen, change any of the components according to your data processing needs. For example, open the filter component called GetRuntimeMetrics_Only and change the regular expression to match logs that contain the keyword done by entering .done. (more info on using packages is available in the help section).
-
Open the destination component called Results and set the relevant connection, bucket, and path to where the results should be saved.
-
All done! To run the job, you'll need to setup a cluster. See the documentation for further details.








