


- Airflow Concepts
- Installation
- User Interface
- DAG Code
- Automation
- Sensors
- Connectors
- Final Thoughts
- Integrating Airflow with Integrate.io
Apache Airflow is a platform defined in code that is used to schedule, monitor, and organize complex workflows and data pipelines. Today’s world has more automated tasks, data integration, and process streams than ever. a powerful and flexible tool that computes the scheduling and monitoring of your jobs is essential.
It doesn't matter what industry you're in, you'll encounter a growing set of tasks that need to happen in a certain order, monitored during their execution, and set up to alert you when they're complete or encounter errors. It's also helpful to learn how your processes change through metrics. Do they take more time or encounter failures? This information allows you to create an iterable approach.
Sometimes complex processes consist of a set of multiple tasks that have plenty of dependencies. It’s quite easy to list as a parent-child set, but a long list can be difficult to analyze. The right tool offers a method to make this easier.
Airflow helps with these challenges and can leverage Google Cloud Platform, AWS, Azure, PostgreSQL, and more. In this article, we are going to introduce the concepts of this platform and give you a step-by-step tutorial and examples of how to make it work better for your needs.
Airflow Concepts
DAGs
Let’s talk about the concepts Airflow is based on. When you set up several tasks to be executed in a particular order, you’re creating a Directed Acyclic Graph (or DAG). Directed means the tasks are executed in some order. Acyclic means you can’t create loops, such as cycles. You view the process with a convenient graph. Here's a simple sample, including a task to print the date followed by two tasks run in parallel. Here’s a look in tree form:

It’s a bit hard to read at first in the backend. The leaves of the tree indicate the very first task to start with, followed by branches that form a trunk.
You can also render graphs in a top-down or bottom-up form. These options are directed graphs. The platform allows you to choose whichever layout you prefer.

The DAGs describe how to run tasks. They are defined in Python files that are placed in Airflow’s DAG_FOLDER. You can have as many as you need. Each one can mention multiple tasks, but it’s better to keep one logical workflow in one file. Task instances can exchange metadata.
Operators
The Operators tell what is there to be done. The Operator should be atomic, describing a single task in a workflow that doesn’t need to share anything with other operators.
Airflow makes it possible for a single DAG to use separate machines, so it’s best for the operators to be independent.
The basic operators provided by this platform include:
- BashOperator: for executing a bash command
- PythonOperator: to call Python functions
- EmailOperator: for sending emails
- SimpleHttpOperator: for calling HTTP requests and receiving the response-text
- DB operators (e.g.: MySqlOperator, SqlliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, etc.): for executing SQL commands
- Sensor: to wait for a certain event (like a file or a row in the database) or time
Tasks
Operators refer to tasks that they execute. A task is the instance of the operator, like:
energy_operator = PythonOperator(task_id='report_blackouts', python_callable=enea_check, dag=dag)
In this example, the energy_operator is an instance of PythonOperator that has been assigned a task_id, a python_callable function, and some DAG.
Installation
Airflow installation on Windows is not smooth. Use the following instructions to use Ubuntu WSL to successfully manage this process:
- Get Ubuntu WSL from Windows Store.
- Install Ubuntu.
- Run bash.
- Verify it comes with python 3.6.8 or so ("python3 -version").
-
Add these packages to successfully install PIP:
- sudo apt-get install software-properties-common
- sudo apt-add-repository universe
- sudo apt-get update
-
Install pip with:
- sudo apt install python3 python3-pip ipython3
- sudo apt install virtualenv
-
Create venv
- virtualenv -p path_to_python/bin/python3 env_name
-
Run the following 2 commands to install airflow:
- export SLUGIFY_USES_TEXT_UNICODE=yes
- pip3 install apache-airflow
- Open a new terminal.
-
Init the airflow DB:
- airflow initdb
You can now invoke the Airflow version.
(airflow) vic@DESKTOP-I5D2O6C:/mnt/c/airflow$ airflow version
[2019-06-27 14:21:26,307] {__init__.py:51} INFO - Using executor SequentialExecutor
____________ _____________
____ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/ v1.10.3
And here’s the folder structure it creates:
(airflow) vic@DESKTOP-I5D2O6C:/mnt/c/airflow/workspace/airflow_home$ tree
.
├── airflow.cfg
├── airflow.db
├── logs
│ └── scheduler
│ ├── 2019-06-27
│ └── latest ->
└── unittests.cfg
User Interface
While interfaces aren't the core feature of any integration tool, the Airflow UI offers an excellent user experience. Run the airflow webserver command to access the admin console at localhost:8080/admin.

You'll see a list of available DAGs and some examples. You can disable the examples in airflow.cfg:
# Whether to load the examples that ship with Airflow. It's good to
# get started, but you probably want to set this to False in a production
# environment
load_examples = True
This DAG list gives basic information, like:
- Id
- Schedule
- Owner
- Status and counts of tasks for active runs
- Last execution time
- Status and counts of DAG runs
- Links to details
The list also allows conveniently enabling and disabling DAGs. It’s clear which are active. Choosing any of the IDs switches to details with Tree View as default:

The list mentions all the operators in a tree view with run statuses across time. Filters make it possible to view statuses for any time span. Hovering over shows additional details in a popup:

Task duration shows a useful graph for performance analysis:

You can check the details that mention concurrency setting, file name, and task IDs.

You can trigger, refresh, or delete DAG from this screen.
DAG Code
On the DAG detail screen, you can check the source code. Let’s review it using the simple example below:
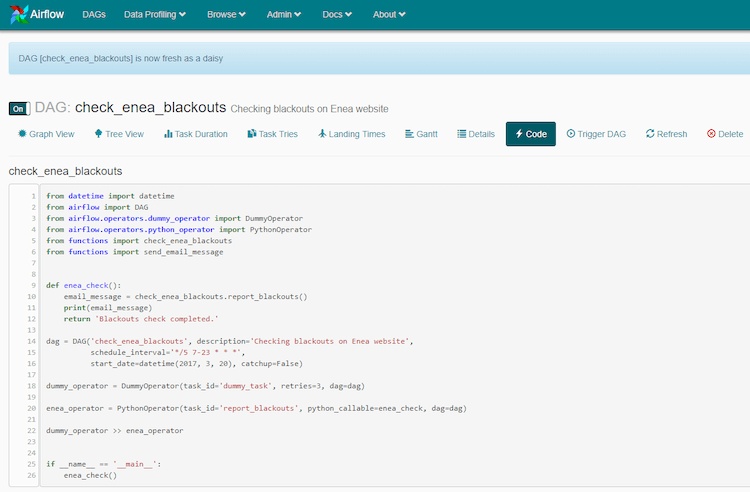
This import section is responsible for including the Airflow library as well as any other used within this DAG:
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from functions import check_enea_blackouts
from functions import send_email_message
Next, there’s a function definition:
def enea_check():
email_message = check_enea_blackouts.report_blackouts()
print(email_message)
return 'Blackouts check completed.'
It's a simple function (not fully included in this example, as it's being imported) to check the blackouts mentioned on the energy operator’s web page. The content of the email is printed in logs.
Next, you have DAG instance created with schedule running every 5 minutes between 7 AM and 11 PM. date is set in the past, but Airflow is told not to catch up, as it would be quite a few runs.You can set this to true if you need to load a data set on a daily basis. However, as part of the go-live, it’s needed to load past data day-by-day. dag = DAG('check_enea_blackouts', description='Checking blackouts on Enea website',
schedule_interval='*/5 7-23 * * *',
start_date=datetime(2017, 3, 20), catchup=False)
Then you create the tasks (Operator instances). In this case, Dummy and Python operators are used.
dummy_operator = DummyOperator(task_id='dummy_task', retries=3, dag=dag)
enea_operator = PythonOperator(task_id='report_blackouts', python_callable=enea_check, dag=dag)
Move to the dependency section. It’s simple in this example and indicates that dummy_operator should be followed by my enea_operator. dummy_operator >> enea_operator
You use the last two lines for testing. Prepare your DAGs in a way that would allow unit testing before scheduling them in the platform.
if __name__ == '__main__':
enea_check()
Automation
Creating complex examples by script
It's easy to automate DAG creation on Airflow. This example shows the ease of DAG scripting and shows how the platform works with complex workflows.
For this exercise, we made a script that uses Python site-packages to create a task for each file mentioned in this location. The first step is creating a set containing all the file names (with dashes replaced by underscores). Next, we print the header containing imports, DAG instance definition with schedule, and the dummy operator to start with. A task definition template in a loop creates tasks for every file. Finally, I need to add dependencies. Finally, for every file we randomly add up to 5 upstream dependencies. Here’s the full script used for creating the DAG:
from os import listdir
from random import randint
root_path = r"/mnt/c/venv/airflow/lib/python3.6/site-packages"
file_set = set()
for filename in listdir(root_path):
filename = filename.split('.')[0]
file_set.add(filename.replace("-", "_"))
common_part = """
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from functions import check_enea_blackouts
from functions import send_email_message
dag = DAG('filechecker_complex_dag_example', description='Taks for file operations.',
schedule_interval='*/15 7,11,16 * * *',
start_date=datetime(2017, 3, 20), catchup=False)
dummy_operator = DummyOperator(task_id='dummy_task', retries=3, dag=dag)"""
DAG_task_definition = """
def {0}():
print('{0} invoked.')
return '{0} check completed.'
{0}_operator = PythonOperator(task_id='{0}_operator', python_callable={0}, dag=dag)
dummy_operator >> {0}_operator"""
print(common_part)
files_in_dag = []
for filename in file_set:
print (DAG_task_definition.format(filename))
for i in range(randint(0, min(6, len(files_in_dag)))):
print ('{0}_operator >> {1}_operator'.format(files_in_dag[randint(0, len(files_in_dag)-1)], filename))
files_in_dag += [filename]
Monitoring a Complex Workflow
Here’s the graph overview:

You can't get all the details at once in this graph. When you hover over the status names, you get a better view. For example, by hovering over ‘success’ it’s possible to quickly check what part of the DAG is completed:

It’s convenient to manipulate the graph, zoom in and out, check task details, or move it around on any zoom level quickly. The Gantt chart works well for complex workflows:

Sensors
Sensors are a special type of Operators used to do the monitoring of other resources. A Sensor is a subclass of the BaseSensorOperator. Its poke function gets called in a loop until:
- it returns True
- it raises an AirflowSkipException, at which point, the instance status will be set to Skipped
- It raises another exception, and is then retried according to the value of the retries For example FileSensor, which uses the BaseSensorOperator (as mentioned in the docs), can be defined as follows:
from airflow.contrib.sensors.file_sensor import FileSensor
from airflow.operators.dummy_operator import DummyOperator
import datetime
import airflow
default_args = {
"depends_on_past" : False,
"start_date" : airflow.utils.dates.days_ago( 1 ),
"retries" : 1,
"retry_delay" : datetime.timedelta( hours= 5 ),
}
with airflow.DAG( "file_sensor_test_v1", default_args= default_args, schedule_interval= "*/5 * * * *", ) as dag:
start_task = DummyOperator( task_id= "start" )
stop_task = DummyOperator( task_id= "stop" )
sensor_task = FileSensor( task_id= "my_file_sensor_task", poke_interval= 30, fs_conn_id= <path>, filepath= <file or directory name> )
start_task >> sensor_task >> stop_task
Connectors
AirFlow allows defining a variety of connections and supports many scheme types. Go to Admin > Connections tab to see a default, very extensive list:

Final Thoughts
Airflow's open-source platform provides the functionality for data engineers to author, monitor, and create complex enterprise grade workflows. While this platform is not an ETL tool, it can integrate with one through its API. Many data teams are adopting this platform, including some of Integrate.io's larger customers.
Integrating Airflow with Integrate.io
Airflow with Integrate.io enables enterprise-wide workflows that seamlessly integrate ETL steps. Integrate.io is a cloud-based ETL Tool that provides simple, visualized data pipelines for automated data flows across a wide range of sources and destinations. To learn more about using Integrate.io in combination with this powerful platform, contact us here!





