


What is Redshift’s pricing model and how much will Redshift cost me?
While Redshift is arguably the best data warehouse on the market, it can come with a hefty price tag. We’ve created this Redshift pricing guide to help you evaluate Redshift cheaply, create a budget for full implementation, and optimize your Redshift set up so that you’re getting the most bang for your data buck.
Ready to get started? Think of this blog post as a “choose your own adventure” guide. Based on where you are in your journey, some parts may be more relevant to you than others, so please use the links above to jump to the sections that you’re most interested in. If you have any questions, leave a comment, and one of our support team members will get back to you.
Table of Contents
Just getting started with Redshift?
Redshift Reserved Instance Pricing
How to Keep Your Redshift Costs Low
Just getting started with Redshift?
If you’re just getting started with Redshift, here’s our recommended path to get the most out of using Redshift while spending the least:
- Take advantage of their free trial. Why pay if you don’t have to?
- See if Redshift is right for you by using Redshift’s On-Demand pricing.
- When you’re ready to commit, use Redshift’s reserved instances to prepay for a one-year minimum contract and save some serious $$.
- Once you’re on a reserved instance, optimize your Redshift instance to save money without sacrificing performance.
Redshift Free Trial
Only applicable for first-time users
If you’ve never used Redshift before, you are eligible for a two-month free trial. It’s a great way to see if Redshift will work for your needs.
In this free trial, you’ve given 750 free node-hours per month for two months of their DC2.Large node (learn more about node types here). This is enough to run one node continuously for 2 months, but you can also add extra nodes to your cluster (if you want to test larger data sets), which means your free hours will be consumed at a faster rate.
Note: Unused hours in either month do NOT rollover. They are lost forever.
Once your 2-month free trial period is up, you can either shut down your Redshift cluster to avoid any charges or keep it running on Redshift’s On-Demand pricing.
Here’s what you need to do to take advantage of the free trial:
- Create an AWS account or sign in to your Amazon console.
- Launch an Amazon Redshift cluster and set the node type to DC2. Large. If you pick the right node type and it’s your first time using Redshift, it will automatically set you on the free trial.
- Set a calendar reminder for 2 months from now to delete your Redshift cluster (if needed).
- If you use more than one node, keep track of your node hours so you don’t get charged during your free trial.
Redshift Pricing: The Basics
On-Demand Pricing vs. Reserved Instance Pricing
Redshift has two different pricing models. The first is called “On-Demand Pricing”, and the second is called “Reserved Instance Pricing”. Let’s start with On-Demand Pricing, as the Reserved pricing is really just the On-demand pricing structure with some nice discounts.
Redshift On-Demand Pricing
Fast, flexible, pay by the hour
On-Demand pricing has no up-front costs or commitments. You pay by the hour for each node and you can spin up and tear down nodes almost instantly. It’s an extremely flexible plan, which makes it great for testing and development. If you can estimate the number of hours you’ll need to complete your tests, and you know what region you’ll be in, you can quickly estimate your costs.
Amazon’s Redshift pricing varies widely based on node type and region. Since Amazon Redshift’s own pricing page only allows you to see pricing one region at a time, and there are simply too many pricing points to fit into this blog post, we created this massive spreadsheet that allows you to quickly see the hourly, daily, monthly, and yearly price of any Redshift node type in any region.
A few things to note:
- This spreadsheet was last updated on June 28th, 2018. We’ll be updating it periodically to make sure it’s current with any pricing changes.
- To play around with it yourself, select “File”, then click “Make a copy” and save it in your own Google Drive account OR select “File”, then “Download as” to download it as an Excel Sheet to your local hard drive.
If you’re already familiar with AWS regions, click here to learn more about Redshift node types, or click here to learn how you can save with Redshift’s Reserved Instance Pricing.
AWS Redshift Regions
How AWS Regions affects Redshift’s cost
The AWS Region is the physical location where your data will be stored, and as you can see in the chart below, Redshift’s pricing varies widely across regions. Since transit and data center costs can be higher for Amazon in a more expensive region, Amazon passes these differences in costs on to the customer.
While it can be tempting to choose the cheapest region, that is rarely a good idea. As a decision-maker for your company, you need to factor in not only much your data warehouse will cost, but also latency (how long it will take to send and receive data from where you are located), as well as that region’s other available services if you’re using more AWS Services than just Redshift.
A best practice is to evaluate your full range of DevOps needs, consulting with other members of your team as necessary, and then pick the region that has the capabilities you’re looking for, and is closest to either you or your customers.
If you’re new to AWS, we know that discussing regions can get overwhelmingly fast, so if you have any concerns, please don’t hesitate to leave a comment, and we’ll get back to you ASAP.
AWS Redshift Node Types
How node types affect Redshift cost
When you launch a Redshift cluster, you’ll be asked to choose between two different types of Redshift nodes that your Redshift instance will be hosted on: Dense Storage and Dense Compute.
Simply put, Dense Compute nodes are between 30% and 60% cheaper than Dense Storage, are optimized for faster queries, and are generally considered best for data sizes less than 500GB.
Meanwhile, Dense Storage nodes are more expensive than Dense Compute, but are better optimized for storing large amounts of data, and are generally considered to be the best choice for data sizes greater than 500GB.
Please note that you cannot mix and match node types.
Adding more nodes to your Redshift cluster will increase storage space and query performance. For testing purposes, it’s probably enough to start off with only one node, but as your data grows, the number of nodes you use will scale with it, and as Amazon charges by node-hour, your costs will as well. If you have any questions about which node type is right for you and how many nodes you’ll need for your dataset, let us know in the comments, and our experienced support engineers will help you out.
Large Nodes vs Extra Large Nodes
Redshift also breaks down node type one step further by allowing you to select between a “large” node or an “extra-large” node. This brings us to four total node types: Dense Compute Large, Dense Compute Extra Large, Dense Storage Large, and Dense Storage Extra Large.
Large and Extra Large nodes are extremely different in terms of Storage, Memory, Speed, and Price. We’ve included a full breakdown in the second tab of our massive spreadsheet on Redshift’s pricing by node type, which I highly encourage you to check out, but simply put, Extra Large nodes offer more storage, use HDD storage instead of SSD storage, and on average cost roughly between 8x and 20x more than Large nodes.
Note: The computing power and storage capacity of node types do NOT vary by region. Only the price does.
If you take a look at the spreadsheet, you’ll see that the average hourly price per TB of storage capacity varies greatly between node types. Based purely on the cost of storage capacity, the Dense Compute Large node is usually a better deal than the Dense Compute Extra Large node, and the Dense Storage Extra Large node is a better deal than the Dense Storage Large node.
However, you can’t make your purchasing decision based on price per TB alone. You also have to factor in query performance, and things like disk I/O requests.
If you're working with an old Redshift cluster, you may see DS1 or DS2 instances. DS1 instances, Redshift's first generation of nodes, are no longer available for new clusters. DS2 instances are the same price and provide about 50% better performance over DS1. If you're still running a cluster with DS1 instances, it's a no-brainer to switch them to DS2.
You can learn more about Redshift node types and the nitty-gritty of the computing power underneath each node type by reading Amazon's documentation, but we know this can be a lot to try to understand, so if you have any questions, let us know, and we’ll do our best to help out.
Redshift Reserved Instance Pricing
Once you know what you want to do, you’ve tested it out, and you’re confident you’re going to be using Redshift continuously for at least the next year, it’s time to save some money by moving to Redshift’s Reserved Instance Pricing, where you commit to a contract for between 1 and 3 years. Based on how much you want to pay upfront for your Redshift instance, you have three different options with escalating levels of savings:
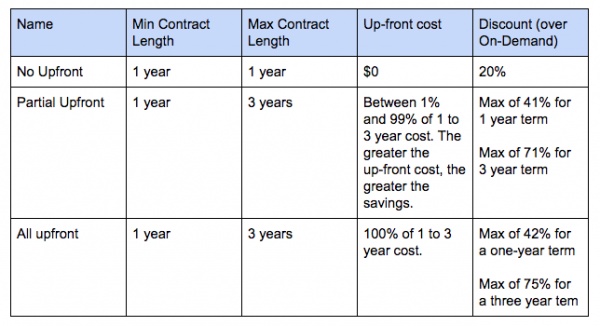
If you’re confident you’re going to use Redshift for the next year and you have some capital to put towards this project, taking advantage of Redshift’s Reserved Instance Pricing can bring some meaningful savings to your business.
How to Purchase a Redshift Reserved Instance
You can purchase a Reserved Instance “reservation” in the AWS Console by clicking here. The steps are pretty straightforward, but there is one important catch that you need to be aware of: Reserving a Redshift node does not actually create any nodes for you.
After you purchase your reservation, you’ll have to specify which node(s) you want the reservation to apply to. If you don’t specify a node or nodes, you’ll be charged for the Redshift Reserved Instance from the moment of purchase, regardless of the fact that it’s not being utilized.
After your Reserved Instance contract ends, your Redshift clusters will continue to run, but you will be billed at the On-Demand rate.
How to Keep Your Redshift Costs Low
Tips & tricks from the experts
Here at Integrate.io, we’ve helped hundreds of companies make the most out of Redshift, and over the past decade, we’ve learned that there are two things you need to do to make sure you’re not paying more than you have to: Encode your columns and vacuum your tables. Let’s start with encoding your columns.
Encode Your Redshift Columns
Encoding your columns properly means that the data will be compressed according to the data type, which saves you space, improves query performance, and helps you reduce the number of nodes you need to run. Amazon recommends that you use Redshift’s COPY command to automatically compress your columns according to their guide. We’re working on a blog post about Redshift’s COPY command, but in the meantime, if you have any questions about Redshift encoding, let us know in the comments!
Vacuum Your Redshift Tables
We’ve also written a separate blog post on vacuuming your Redshift tables, but the general idea is that since Redshift does not automatically “reclaim” the space of a deleted or updated row, you need to periodically run Redshift’s VACUUM command to resort your tables and clear out any unused space. This optimizes performance and can reduce the number of nodes you need to host your data. You can learn more about this process and how it works here.
Optimize Your Data Replication
Setting up your pipeline to load your data into Redshift smoothly and easily can be quite a project, costing your organization valuable time and resources. This is especially true if you want your data to be replicated in near real-time, which is usually the case for tracking important business metrics. This is where Integrate.io comes in. Integrate.io's data replication provides continuous, real-time replication into Redshift and Snowflake from your transactional databases, such as MySQL, PostgreSQL, Amazon Aurora, and more. With an easy, one-time setup, our robust system ensures 100% accuracy with each load. Your data is always up to date. For more information on Integrate.io's data replication, visit our product pages or solutions pages here.





