

Let’s say that you’re doing some marketing for a Big Data startup. As part of your campaign, you want to find the most influential tweeters who talk about Hadoop and determine where they come from. So you collect tweets, with DataSift for example. But now you have a ton of JSON objects filled with data from Twitter and no clue what to do with them.
Integrate.io can help. With Integrate.io you can load the Twitter data, analyze it and get the results that you want. We’ll show you how to find the most influential Hadoop tweeters and find out their location in the world using Integrate.io.
Dataflow

The above dataflow does the following:
-
Loads the data
-
Selects the username, followers, location and tweet content
-
Filters tweets that contain the word “hadoop” (case insensitive), have more than 100 followers and contain a “place” attribute
-
Adds more columns for the city and country while getting rid of the text
-
Aggregates the data so that we get the number of followers per user
-
Sorts the data by number of followers in descending order
-
Stores the results
Let’s see how it works in more detail.
Loading Twitter Data
The data is stored on our public Amazon S3 account and contain tweets that have the #BigData hashtag in JSON format. To load the data set, we use a cloud storage source component and auto-detect the schema (green button at the top right).

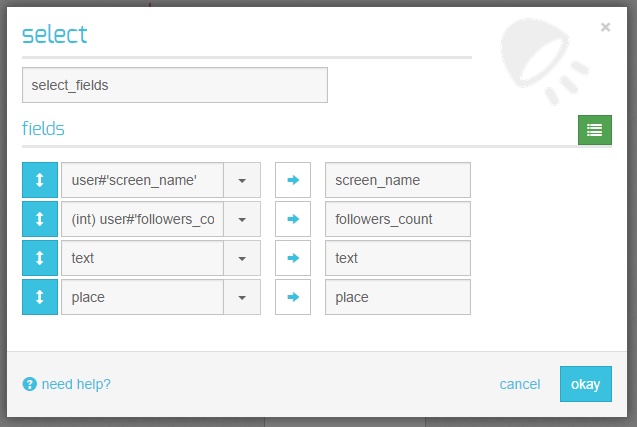
Selecting Attributes
We only need the following fields:
-
screen_name
-
followers_count
-
place
-
text
We use a select component with JSON notation where relevant. Note that the followers_count was cast to an integer so that we could compare it as a number rather than as a string.
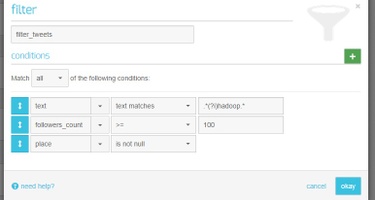
Filtering Tweets
Generally, Integrate.io provides three types of filter conditions:
-
Textual for text comparison, such as equals, matches, and empty
-
Operators like equals, greater than, smaller than, etc., usually for numeric comparison
-
Null or non-null value
There are three modes to match filters:
-
All—all conditions should be matched (logical “AND”)
-
Any—any of the conditions should be matched (logical “OR”)
-
None—no conditions should be matched (logical “NOT AND”)
In our case, we need to filter tweets that matched all of the following conditions:
-
Tweets that contain “hadoop” case insensitive
-
Users with more than 100 followers
-
Users who have location information

Another Selection
After the data passes through the filter, we get rid of the tweeted text and also extracted the name and country from the place JSON object.

Aggregating the Data
While processing the data, we found that the follower count for each tweet represented the follower count that the user had at that time. We need just one number per user, so we could grab the maximum number of followers per user-city-country combination (the screen_name is unique on Twitter, so it’s always the same user).

Sorting Tweets
To get the most influential tweeters first, we can sort the data by followers_count in descending order.

Saving the Results
Now that the data have been processed, let’s save the results on our Amazon S3 account in tab delimited format.

Results
Here are the results of running the above dataflow in Integrate.io:
If we were to continue our marketing campaign, we could now get in touch with these users and see how we could help each other to promote Big Data. You can do the same with your tweets, social data, or any other data—just sign up to Integrate.io.





