


- Understanding Data Lake Architecture and Data Structure
- Benefits of Data Lake Design
- Building a Secure Data Lake
- Data Lake vs. Traditional Databases vs. Cloud Data Lakes
- Best Practices in Data Lake Design
- Enhancing Your Data Lake with Business Intelligence
- Elevate Your Data Strategy with a No-Code Data Pipeline Platform
The importance of a well-structured data lake architecture cannot be overstated. As businesses work with an ever-increasing influx of data, the need for a robust, scalable, and efficient data storage solution becomes crucial. Let’s explore Data Lake Architecture Design—a concept revolutionizing how enterprises store, access, analyze, and compute their data.
[Key Takeaways] Dive into Data Lake Architecture Design and discover:
The essence of modern data lake design and data architecture.
The transformative advantages of a well-architected data lake.
Key components and best practices for building a resilient data lake.
The stark contrast between data lakes, cloud data lakes, and traditional databases.
How automation and a no-code data pipeline platform empowers businesses with state-of-the-art data lake solutions.
Understanding Data Lake Architecture and Data Structure
Creating data lakes, especially cloud data lakes like those on AWS, has revolutionized how businesses store, process, and analyze large amounts of information. Unlike traditional databases that require structured data, a data lake is a dynamic reservoir capable of storing diverse types of data, from structured datasets to unstructured social media chatter and semi-structured files. This versatility is underpinned by its unique architecture and data structure.
The architecture of a data lake is multi-faceted. The storage layer is foundational, often leveraging object storage solutions like AWS for scalability and cost-efficiency. Next, the processing layer comes into play, using data integration tools to transform raw data into a more usable format. The analytical layer integrates with various platforms, enabling in-depth data analysis, while the consumption layer ensures that insights are easily accessible to business users through dashboards and visualization solutions.
A pivotal aspect of data lakes is the schema-on-read approach. Instead of confining data to a predetermined structure upon data ingestion, data lakes store it in its raw form in a flexible file system. It fits into a schema only when accessed, offering unparalleled flexibility and adaptability. This approach, combined with robust security protocols and the strategic use of metadata to guide users, positions data lakes as indispensable tools for businesses aiming to harness the full potential of their data for decision-making.
Benefits of Data Lake Design
In data management, the rise of data lakes has changed how businesses store, access, and analyze their data types. As digital transformations continue to sweep across industries, the importance of a well-structured Data Lake Architecture Design becomes increasingly evident. What exactly are the benefits of adopting such a design? Let's dive deep into the advantages that a meticulously designed data lake brings to the table.
Centralized Data Storage
One of the most significant challenges businesses face today is data silos. From spreadsheets on local servers to cloud-based CRM systems, data is everywhere. A data lake centralizes this data, offering a single repository for all business data, regardless of source or native format.
Benefit: Centralization simplifies data management, reduces storage costs, and ensures that data from various departments and systems can "talk" to each other, paving the way for holistic insights.
Unparalleled Flexibility
Traditional databases often require data to fit into predefined schemas, which can be restrictive. Data lakes, on the other hand, are schema-less. They can store structured data like databases and unstructured data like emails, videos, or social media files.
Benefit: This flexibility ensures that businesses can store any data today without worrying about potential use-cases in the future. The data lake can effortlessly accommodate new data types as business needs evolve.
Scalability at its Best
A well-designed Data Lake Architecture ensures scalability, allowing businesses to store petabytes of data without performance hiccups.
Benefit: As businesses grow, their data needs grow. Data lakes ensure that scalability is never an issue, allowing companies to focus on deriving value from their data rather than managing heavy data workloads.
Advanced Analytics and Business Intelligence
Data lakes are built for big data analytics and business intelligence. Their design facilitates using advanced analytics tools and machine learning algorithms directly on the stored data without needing data movement.
Benefit: This opens the door for predictive analytics, customer behavior analysis, and AI-driven insights, ensuring businesses stay ahead of the curve and can make data-driven decisions in real-time.
Real-time Data Processing
In today's always-on business environment, real-time insights can be game-changers. Data lakes support real-time data processing, allowing businesses to analyze data as it comes in.
Benefit: Whether real-time stock market data or live social media sentiment analysis, businesses can react instantly, capitalizing on opportunities or mitigating challenges.
Cost-effective Data Management
Storing large amounts of data can be expensive, especially with heavy volumes. Data lakes, especially those based on cloud solutions like AWS, offer a cost-effective way to store massive amounts of data. They often operate on a pay-as-you-go model, ensuring businesses only pay for the storage they use.
Benefit: Storage cost savings can be redirected to more value-driven initiatives, ensuring a higher ROI on data investments.
Enhanced Data Quality and Governance
A well-architected data lake has built-in tools for data cleansing, quality checks, and data governance. This ensures that the data within the lake is always of high quality and ready for analysis.
Benefit: High-quality data leads to accurate insights. With robust governance protocols, businesses can ensure compliance with regulations, further enhancing the trustworthiness of their data.
The benefits of a well-designed Data Lake Architecture are manifold. From centralized storage and unparalleled flexibility to cost savings and advanced analytics capabilities, data lakes transform how businesses view and handle their data. As data continues to grow at an exponential rate, investing in a robust Data Lake Architecture Design is not just a tech decision; it's a strategic business move.
Building a Secure Data Lake
Data lakes have become invaluable assets, storing vast amounts of structured and unstructured data. However, their immense value also makes them prime targets for cyber threats. Ensuring robust security for a data lake involves a multi-layered approach:
- Network Security: Protecting the infrastructure and network against unauthorized access using surveillance, biometric controls, firewalls, and intrusion detection systems.
- Data Encryption: Using advanced protocols to encrypt data at rest and during transit, ensuring data remains inaccessible even if it is breached.
- Access Control: Implementing Role-based Access Control (RBAC) to ensure users access only data relevant to their roles, safeguarding sensitive information.
- Data Masking and Tokenization: Replacing sensitive data with fictitious or tokenized data, preserving utility while enhancing security.
- Audits and Monitoring: Regularly checking security adherence and using tools to detect anomalies or unauthorized access attempts.
- Backup and Recovery: Having strategies to recover data in case of breaches, ensuring minimal data loss and downtime.
- Continuous Updates: Staying ahead of evolving cyber threats by updating security protocols and adopting newer methods.
- Training: Educating users on best security practices, reducing human errors, and ensuring swift breach responses.
A secure data lake requires a holistic, ever-evolving approach, balancing technical measures with user education and ensuring data remains accessible and protected.
Data Lake vs. Traditional Databases vs. Cloud Data Lakes
Data management, Data Lakes, Traditional Databases, and Data Warehouses each offer unique advantages:
- Data Lake: A flexible reservoir storing structured and unstructured data in its raw form. It's scalable and adaptable, ideal for diverse data types, but requires robust processing for analysis.
- Traditional Databases: These structured systems, like SQL, have been business mainstays for decades. They're optimized for transactional processing but can be less agile when handling vast, varied data.
- Data Warehouses: Large-scale storage facilities designed for analysis. They efficiently handle structured data from various sources and are optimized for complex queries and reporting.
While data lakes offer unparalleled flexibility, traditional databases excel in transactional processing, and data warehouses are analytical powerhouses. The choice between them depends on specific business needs and the nature of the data in question.
Recommended Reading: Data lake vs Data Warehouse
Best Practices in Data Lake Design
When working with big data, the significance of data lakes has skyrocketed. As businesses engage with ever-increasing volumes of data, the allure of a centralized repository that can store diverse data types is undeniable. However, the success of a data lake hinges on its design. A poorly designed data lake can quickly devolve into a data swamp, a chaotic and unmanageable mess. To ensure that your data lake remains a valuable asset, it's crucial to adhere to best practices in its design and implementation. Let's explore the key strategies that underpin an effective Data Lake Architecture Design.
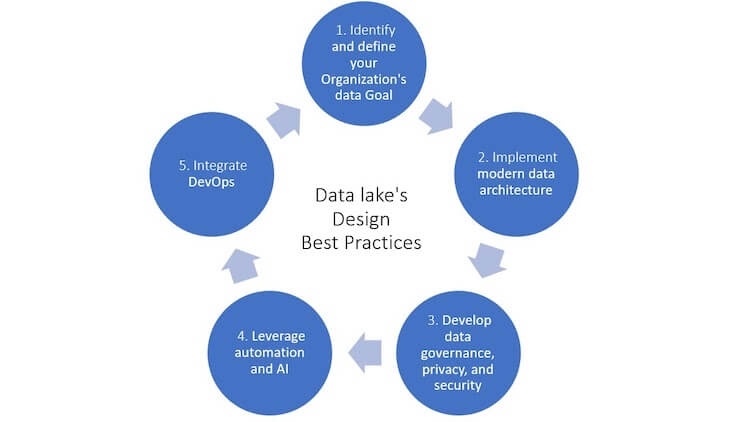
1. Define Clear Objectives
Before diving into the technicalities, having a clear vision is essential. Why are you building a data lake? What business problems will it address? Whether it's to enhance real-time analytics, foster machine learning initiatives, or streamline data integration, having well-defined objectives will guide the design process.
2. Prioritize Data Quality
A data lake is only as valuable as the data it houses. Ensuring data quality is a priority. This involves:
- Data Cleansing: Regularly remove duplicates, correct inaccuracies, and fill in missing values.
- Data Validation: Implement validation rules to ensure incoming data meets predefined quality standards.
- Metadata Management: Using metadata to provide context makes data retrieval efficient and user-friendly.
3. Implement Robust Security Measures
Security isn't an afterthought; it's foundational. Given the sensitive nature of data, implementing multi-layered security protocols is non-negotiable. This includes:
- Data Encryption: Both at rest and in transit.
- Access Controls: Define user roles and permissions, ensuring that users can only access data relevant to their roles.
- Audit Trails: Maintain logs of all data access and modifications, providing transparency and accountability.
4. Optimize for Scalability
Data volumes will inevitably grow. Designing a data lake that can scale seamlessly is crucial. Leveraging cloud-based solutions, like Amazon S3, Azure Blob Storage, or Google Cloud, can offer the scalability required without significant infrastructural investments.
5. Foster Interoperability
Data lakes often coexist with other systems, be it traditional databases, data warehouses, or BI tools. Ensuring interoperability through standardized data formats and APIs enhances the utility of the data lake, allowing for seamless data flow across systems.
6. Embrace a Multi-tiered Storage Strategy
Not all data is accessed equally. Implementing a multi-tiered storage strategy, where frequently accessed data is stored in high-performance storage while less frequently accessed data is archived, can optimize performance and reduce costs.
7. Monitor and Maintain
A data lake isn't a set-it-and-forget-it solution. Regular monitoring, maintenance, and optimization are essential. This involves:
- Performance Monitoring: Regularly check query performances and optimize as needed.
- Data Pruning: Periodically remove obsolete or redundant data.
- Update Protocols: As business needs evolve, so should the data lake. Regularly update schemas, workflows, and tools to align with business objectives.
8. Foster Collaboration
A data lake serves diverse user groups, from data scientists to business analysts. Fostering collaboration through shared workspaces and collaborative tools can maximize the value derived from the data lake.
A well-designed data lake is a potent tool in the modern data landscape. However, its efficacy hinges on its design. By adhering to best practices, businesses can ensure their data lake remains navigable, secure, and aligned with business objectives. As the volume and diversity of data continue to grow, the importance of robust Data Lake Architecture Design will only amplify, positioning data lakes as indispensable assets in data-driven businesses.
Recommended Reading: Building a Successful Data lake Architecture
Enhancing Your Data Lake with Business Intelligence
Integrate.io stands at the forefront of no-code ETL & ELT, offering solutions that simplify and enhance data lake management. With its intuitive interface, powerful data transformations, and many connectors, Integrate.io ensures that your data lake is a strategic asset, driving business growth and innovation.
Elevate Your Data Strategy with a No-Code Data Pipeline Platform
Integrate.io's out-of-the-box data transformations will save you time and effort while maintaining control over any flowing data, from simple replication to complex data preparation and transformation tasks with a drag-and-drop interface. Integrate.io offers an easy configuration to pull or push data from the most popular data sources on the public cloud, private cloud, or on-premise infrastructure using Integrate.io’s native connectors at a low cost. Applications, databases, files, and data warehouses are all supported. Learn more about Integrate.io's automated data pipelines and ingestion solutions, or contact our team to schedule a demo and get the most out of your data lake.





