
- What is a Data Pipeline?
- Benefits of Modern Data Pipelines
- 5 Data Pipeline Tools to Help You Build Modern Data Pipelines
- Harness the Unlimited Power of No-Code Data Pipelines
Data pipelines are the backbone of modern data-driven businesses. These pipelines are responsible for extracting, transforming, and loading data from various sources into data warehouses or data lakes. Building a data pipeline that is efficient, reliable, and scalable can be a challenging task, especially for those without a technical background.
Fortunately, there are now several user-friendly tools available that can help businesses build and maintain robust data pipelines without requiring a team of data engineers. With the right tools in hand, data analysts can quickly build resilient data pipelines for your analytics infrastructure. From orchestration to monitoring, these tools can march your business towards advanced levels of automation, as well as improved transparency into how your pipeline functions along every step of its journey.
The key takeaways from this article are:
- The process of collecting, transporting, transforming, and storing data makes a data pipeline.
- Data pipelines are critical for modern data-driven organizations.
- Modern data pipelines offer continuous data processing, cloud elasticity, isolated and independent resources, democratized data access, self-service management, and high availability.
- Modern data pipelines can optimize workflows, from basic ETL to advanced event processing or machine learning.
- Modern data pipelines can quickly adapt to changing requirements, accommodate new sources of big data or data transformations without extensive re-engineering, and easily leverage emerging cloud technologies.
In this article, we explore how modern data pipeline tools can help organizations achieve improved scalability, flexibility, and adaptability in their data processing.
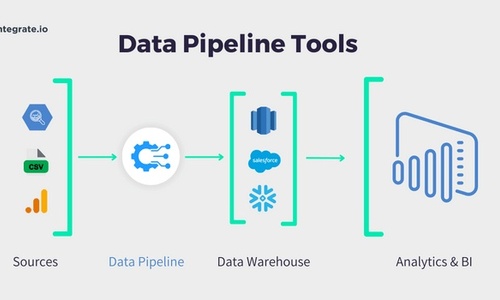
What is a Data Pipeline?
The process of collecting, transporting, transforming, and storing data is what makes a data pipeline. From web APIs to centralized cloud-based repositories or databases, raw data is extracted from multiple sources before being transported across different locations. Here, the data undergoes several transformations so that it's suitable for analytics.
This metamorphosis includes sorting and categorizing the data into acceptable formats, enriching it with applicable metadata, and removing duplicate entries or invalid records. Once the process is complete, the transformed data can be loaded into a data warehouse, data lake, or other analytical platforms, where analysts can use it to produce insights that drive business decisions.
Modern ETL (extract, transform, load) pipelines aim to ensure scalability, flexibility, and robustness that traditional pipelines could not provide. This includes streamlining the process of data ingestion, validation check building, and assuring data accuracy with strong tracking mechanisms. Also designed to be agile, modern pipelines can quickly adapt to changing requirements; accommodate new sources of big data or data transformations without extensive re-engineering; and easily leverage emerging cloud technologies.
Benefits of Modern Data Pipelines
Modern data pipelines offer a range of benefits for businesses and organizations. The most notable are:
- Continuous data processing
- The elasticity and agility of the Cloud
- Isolated and independent resources for data processing
- Democratized data access and self-service management
- High availability and disaster recovery
In the ever-evolving world of business decisions, continuous data processing is a key factor for success. With data pipelines, you can tailor almost any workflow to accelerate and optimize your work, from basic ETL and ELT (extract, load, transform) jobs to advanced event stream processing or machine learning training tasks. By configuring each operation independently, your pipeline will stay agile enough so that any future amendments won't require significant modifications. Integrate.io provides an efficient, cost-effective way to set up and maintain your ETL or ELT data pipelines.
Modern data pipelines draw from the elasticity and agility offered by cloud computing. Companies can effortlessly scale their resources up or down, ensuring optimal efficiency regardless of how much data is being processed. With cloud technologies, organizations have access to real-time analytics for rapid insights into their operations.
These pipelines also offer individualized, separate assets for each job in the pipeline. This segregation guarantees that one process won't negatively affect another and that all of them will remain operational without interruption, even when issues arise with a single task. Moreover, this lets firms maintain authority over which tasks are allowed to access particular resources, leading to extra security and confidentiality. It’s easy to prepare and transform your data — no coding knowledge required — with Integrate.io.
With modern data pipeline architecture and ETL pipelines, democratized access and self-service management capabilities are now within reach. Thanks to cloud technologies, businesses have the autonomy to establish their own systems and control who has permission to view certain sets of information or complete specific assignments. Furthermore, with self-service management devices, users can manage and adjust their jobs without external IT assistance.
5 Data Pipeline Tools to Help You Build Modern Data Pipelines
A modern data pipeline solution is an essential part of any business’s architecture. It allows for the collection, transformation, and storage of large volume of batch data in a secure and reliable manner. Below, we explore the top five no-code data pipeline tools.

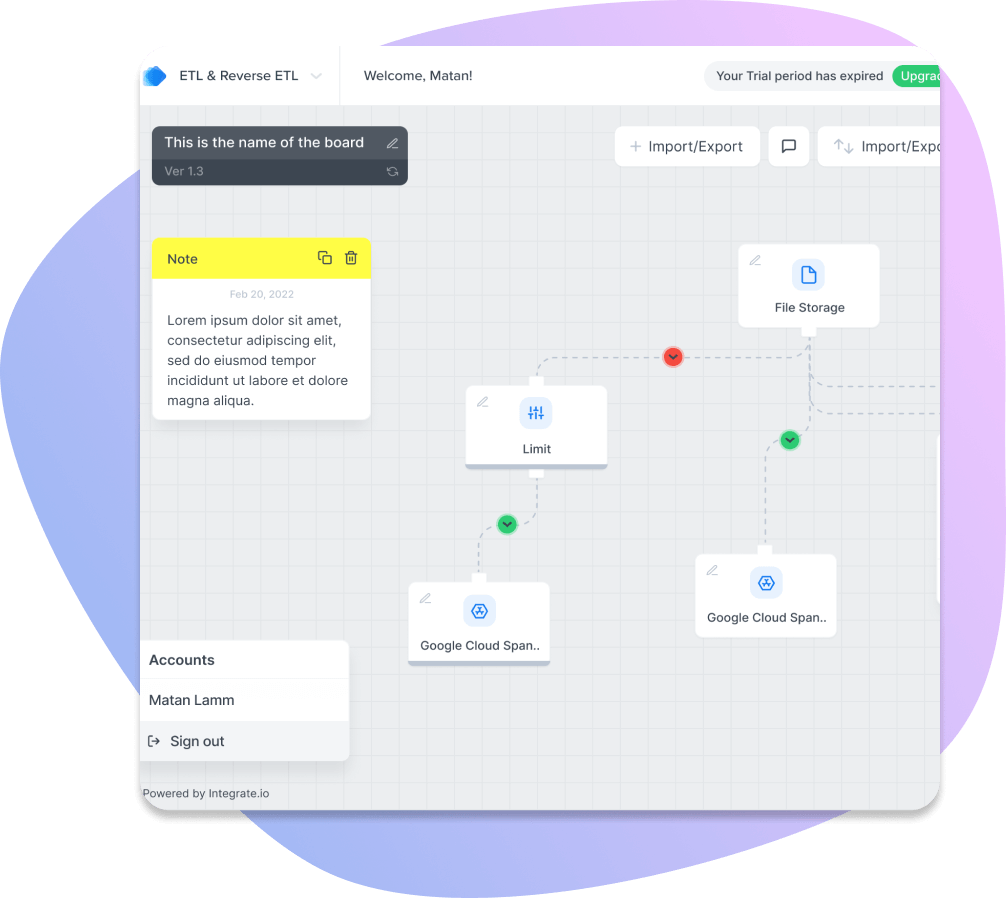
Integrate.io
Integrate.io is the most powerful end-to-end, no-code data pipeline tool available for modern businesses. With its simple visualized data pipelines, automated data flows across multiple sources. You can use this effective platform to develop sophisticated ETL solutions without the need to customize complex scripts or code.
Each of the components within Integrate.io’s integrated cloud ETL tools helps users build efficient and well-connected data pipelines quickly:
- The intuitive, graphic, drag-and-drop interface enables the creation of mapping between different source systems. Users can also conduct data management transformations — such as merging columns, applying conditional logic, etc. — thus eliminating manual coding for every step of the ETL process.
- Integrate.io’s CDC (Change Data Capture/Data Replication) feature helps to quickly unify data from multiple sources into a single source for reporting truth. This ensures that users have the most up-to-date and accurate data available within minutes, rather than hours or days.
- In addition to its unified data integration features, Integrate.io provides users with unparalleled data observability monitoring and alerting capabilities. Users can define customized alerts that proactively warn when data within their various source systems deviate from established benchmarks. This allows them to take immediate corrective action to ensure the data remains reliable and accurate at all times.
Integrate.io can also be used for a variety of data integration tasks, including:
- Centralizing a company’s data from all its data stores (databases, third-party apps, CRMs) in a data warehouse (BigQuery, Redshift, etc.)
- Moving and transforming data internally among a company’s different data stores (e.g., moving data from MySQL database to PostgreSQL database).
- Enriching Salesforce with additional external datasets. Data teams can load data directly to Salesforce or into an intermediary like Big Query for further processing.
- Connecting the centralized/enriched dataset to business intelligence (BI) tools like Tableau, Looker, and the like for visual analytics.
Price:
Integrate.io pricing is tailored exactly to each client's needs and requirements with a usage-based component couple with features and functionality. Clients choose which level of platform usage they will require and then which features and functionality to create a custom plan to fit their use case.
G2 Customer Rating: 4.3/5
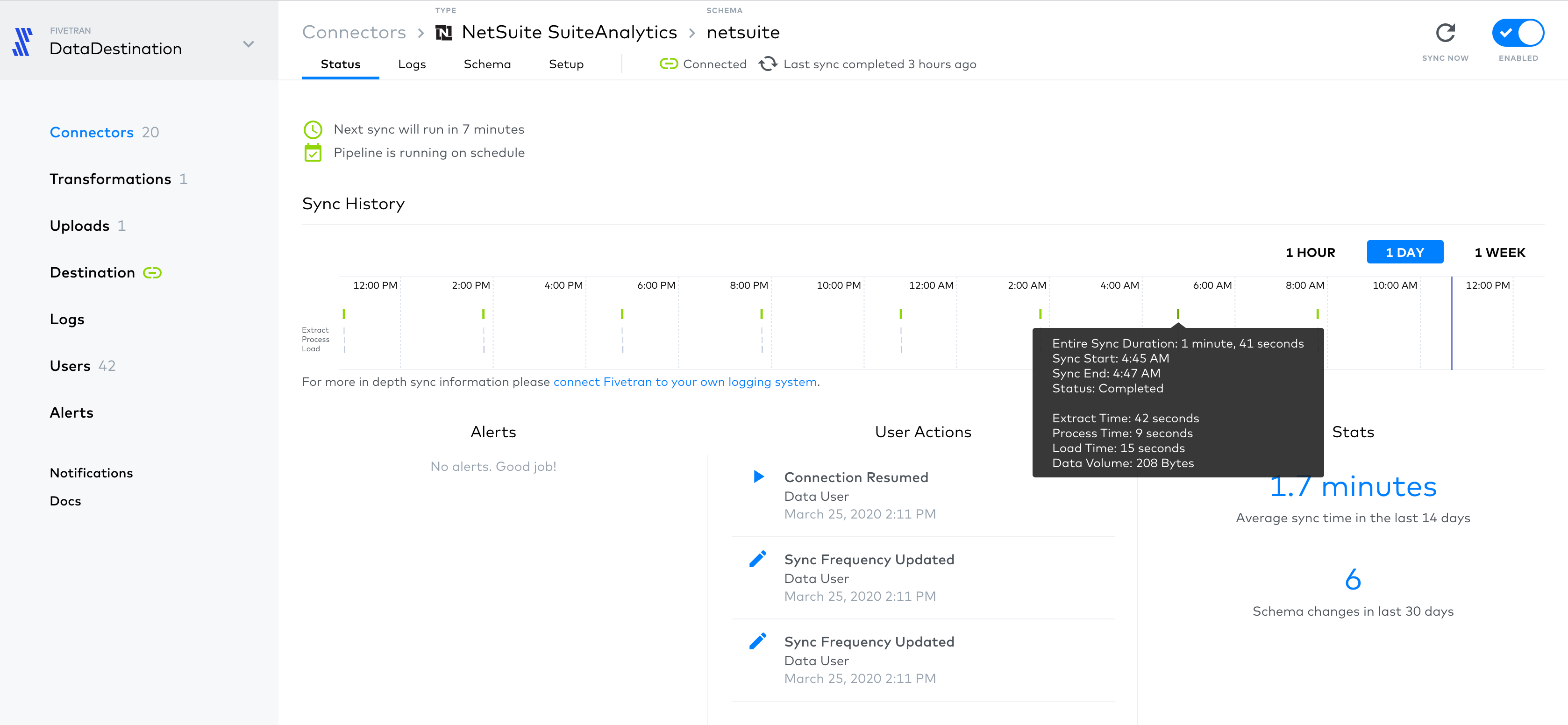
Fivetran
Fivetran is a no-code data integration platform for building modern pipelines. It lets users leapfrog manual coding and SQL statements by streaming multiple sources into one cohesive repository.
With Fivetran, data sourcing is simple. Popular sources such as Microsoft Azure and Facebook come with premade connectors and models that don't require a background in SQL.
In addition to its ease and speed, Fivetran is equipped with security features to keep data protected. These assure that information is always secure and compliant with all current industry regulations:
- Sophisticated encryption protocols
- Data masking technology
- Auditing capabilities
Price: Starts at $6,000 per year
G2 Customer Rating: 4.2/5

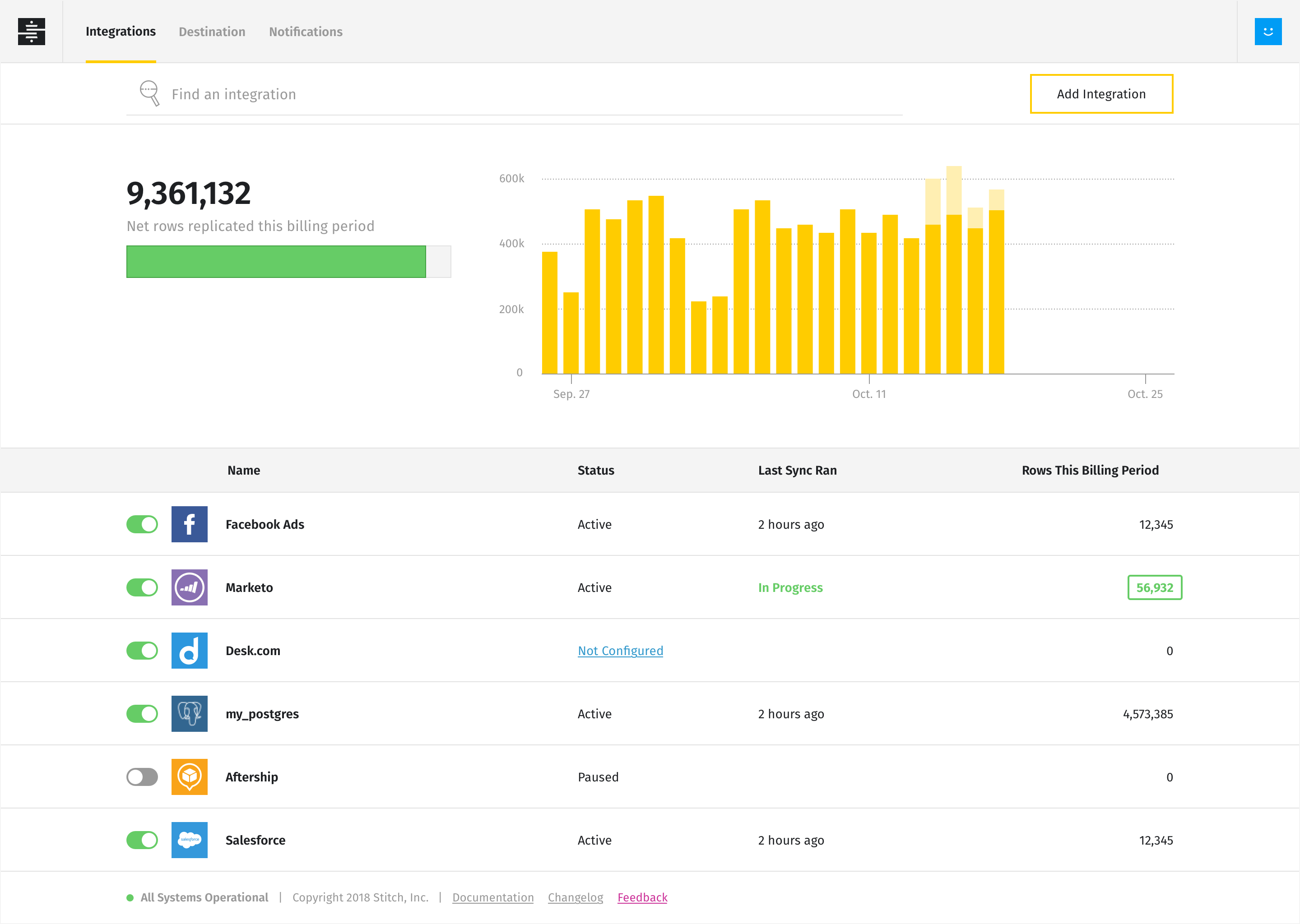
Stitch
Stitch's cloud-based, open-source, and developer-friendly data integration tool lets data teams create and collaborate on projects, as well as move data. The ETL process simplifies the connection of all sorts of sources — including databases and streaming services — while transforming extracted data into a structured format ready for further analysis.
Leveraging the Singer open-source framework, companies can extract data from any system in a standard JSON format. Stitch's error detection technology not only alerts of generic pipeline problems, but also offers solutions where possible.
Besides its ETL capabilities, Stitch offers three products crafted for sales, marketing, and product analytics.
- Stitch for SALES Analytics allows users with the required tools to understand customer activity, improve procedures, and maximize income from sales initiatives.
- With MARKETING Analytics, users are able to track campaigns, measure marketing effectiveness, identify opportunities for improvement, and leverage insights for future campaigns.
- Finally, PRODUCT Analytics equips users with the ability to monitor product usage data in real-time and integrate it into other systems for detailed analysis.
Price: Starts at $100 per month
G2 Customer Rating: 4.5/5
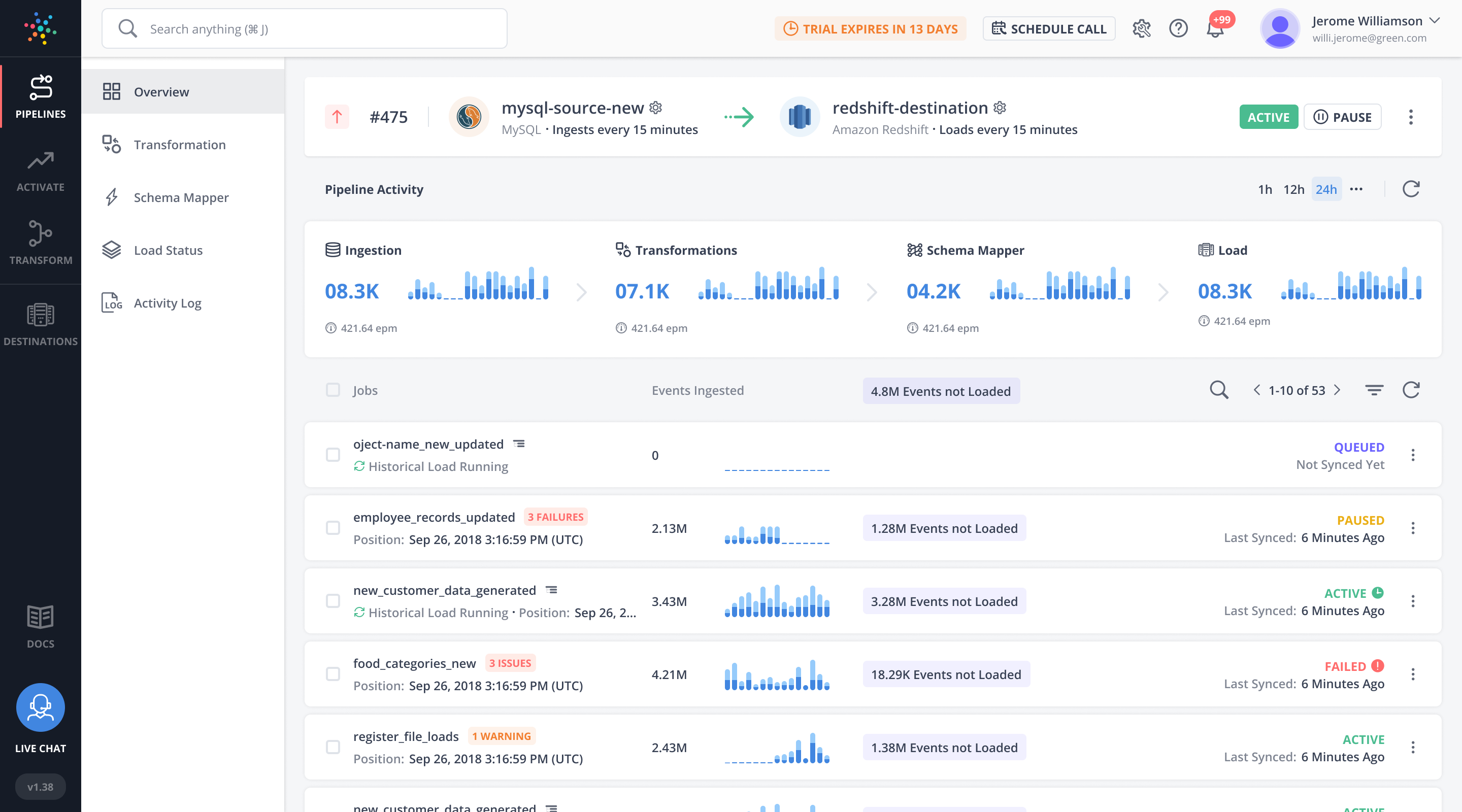
Hevo Data
Hevo Data gives companies access to a suite of features and capabilities:
- The platform provides the ability for near real-time data integration without any coding or complex configurations.
- It has a simple user interface, as well as an extensive library of integrations for popular sources — like databases and web apps — so data teams can quickly connect applications to the platform.
- Hevo also supports Reverse ETL, so data loads can be performed in both directions, from source systems to cloud warehouses and vice versa.
- Furthermore, it offers multi-region workspace support that gives users the opportunity to store their data in multiple locations.
With Hevo's multi-tenant platform, collaborating on projects with both internal colleagues and external partners is possible.
Price: Starts at $239 per month
G2 Customer Rating: 4.3/5

Gravity Data
Gravity Data offers an intuitive platform that allows users to assemble intricate data pipelines. The platform's automated features, such as sophisticated scheduling & monitoring capabilities, make it possible to manage data flows in real-time.
Additional features include:
- A simple, drag-and-drop interface that eliminates the requirement for coding knowledge or assistance from DevOps teams.
- The ability to construct complex on-premise data pipelines within minutes.
- An opportunity for users to track customer data usage and a guarantee that what they're observing is reliable.
Price: Starts at $270 per month
G2 Customer Rating: 5/5 (2 reviews)
Harness the Unlimited Power of No-Code Data Pipelines with Integrate.io
Data scientists can harness the power of no-code data pipeline tools, but businesses should carefully assess their needs before deciding which to implement. Make sure the software or service provider you choose is going to help you leverage insights for business growth and achieve a true competitive advantage.
If constructing and monitoring a comprehensive data pipeline presents an overwhelming challenge, Integrate.io is here for you. Our team of experts can help you map out a plan, with pricing, that delivers everything your company requires. Schedule an intro call with one of our experts today.





