


- The Value of a Data Warehouse
- Why Amazon Redshift?
- Step-by-Step Tutorial: Set Up an Amazon Redshift Data Warehouse
- Loading Data Onto Your Redshift Data Warehouse
- Redshift Queries
- Integrate.io: Advanced Solutions for Data Warehouse Use Cases
Most businesses start tracking data with Excel or Google Sheets – the manual way. In fact, 63% of U.S. businesses prefer Excel for budgeting and planning, according to a 2018 Robert Half survey. However, the number of businesses depending on simple spreadsheets is declining, having dropped by 6% between 2017 and 2018 along. Indeed, less and less companies prefer spreadsheet-based solutions to store their data sets.
The reason why companies are leaving Excel and Google Sheets is because they want the benefit of the in-depth data analysis provided by data warehouses like Amazon Redshift and Snowflake. Data warehouses are better than simple spreadsheets because they offer scalability, reduced human error through automation, and business intelligence insights – all of which can transform the efficiency and profitability of your business.
That being said, firing up a data warehouse is a lot more complicated than plugging numbers into a spreadsheet. That’s why we wrote this guide.
The Value of a Data Warehouse
A data warehouse serves as a central data hub for the key information related to your company. By providing access to all your information in one place, the data warehouse integrates data from various databases, spreadsheets, applications, and more. Data from different sources usually don't easily fit together, so the data warehouse connects the information in a way that you can perform deep queries and analysis that incorporates all of it.
In this way, the data warehouse brings tremendous value because it lets you access, analyze, interpret, and extract deep insights using as much information as possible. These insights help your company forecast future trends and make better business decisions. In fact, the companies with access to deep insights from machine learning analytics like this gain an immediate leg up on the competition.
Data Warehouses vs. Databases
Although you can use a data warehouse for querying and managing your database, there are some fundamental differences between data warehouses and databases. For one, databases are designed for "transactional data processing." In other words, they store and provide access to information about what happened in your company's record-keeping and accounting. They allow you to run basic queries and reports for stats and other data on this information.
Conversely, a data warehouse is built for pulling together and analyzing massive amounts of data at once. The data warehouse service integrates your data for use with powerful business insights tools, machine learning, and artificial intelligence algorithms. This complex analysis provides predictive insights about what could happen in the future (not just reports on what happened or is happening now).
Related Reading: Data Warehouse vs. Database: 7 Key Differences
Cloud-Based Data Warehouses: The Way of the Future
An important trend in modern data warehousing strategies relates to cloud-based data warehouses. Most businesses have begun to use cloud-based data warehouse platforms like Amazon Redshift, Snowflake, Google BigQuery, and others. These platforms offer the following advantages:
- Fast, easy, and sometimes free: You can set up a cloud-based data warehouse quickly and inexpensively. If your cloud computing needs are modest, you can even create and use a data warehouse for free. We're going to show you how to that in this article.
- No need to purchase hardware: Without the time and expense of buying physical hardware, it's a lot easier to set up a cloud-based data warehouse than a physical one.
- Scalable: Businesses used to suffer far too long with sluggish onsite servers in desperate need of upgrades. With a cloud-based data warehouse they can upgrade the speed and size of their systems simply by changing the configurations.
- Speed: Analytics, business intelligence, and complex data queries can slow down a traditional data system, but cloud-based data warehouses are built for handling analytics tasks.
- Convenient tech maintenance: To maintain your cloud-based data warehouse, you don't need to employ a full-time tech person. Just call the data warehouse provider and their customer support will sort out your challenges.
- Easy integration: Cloud-based data warehouses were made to integrate with as many data types and formats as possible. However, they're still not perfect, and that's where services like Integrate.io can help.
We chose to use Amazon Redshift for this how-to guide. In the next sections, we'll discuss AWS Redshift and provide a step-by-step procedure of creating a free warehouse on the platform.
Related Reading: Cloud vs. On-Prem Data Warehouse
Why Amazon Redshift?
As one of the most popular data warehouse solutions, Amazon Redshift comes with key advantages regardless of the type and size of your business:
- A free basic tier for setup purposes: You can set up, query, and play with a fully-functional data warehouse on Redshift for free. That way you can decide if this data solution is right for you and your needs.
- Zero hardware requirements: Like all cloud-based data warehouse platforms, you don't need to buy or install any special hardware to use Redshift.
- Scalability: From gigabyte to petabyte scale, rest assured that it's highly unlikely your data needs will "outgrow" the capacity of Redshift no matter how big your company gets.
- Easy for beginners: As part of the Amazon AWS ecosystem, it’s one of the easiest for beginners to set up use
- Use-based pricing: Amazon's "Spectrum Pricing" allows you to merely pay for queries that you run via a use-based pricing model.
Redshift is also one of the most popular data warehousing solutions. Redshift customers currently include notable companies like Nokia, Coinbase, Yelp, Soundcloud, Pinterest, and AMGEN. In addition, a website that tracks data warehouse popularity reports that more companies are adopting Redshift with each passing year:

Redshift is an excellent option for data warehousing “first-timers," but alternatives abound, such as Snowflake and Google BigQuery. Keep a lookout for guides on these data warehouses in the future.
For more information on Integrate.io's native Redshift connector, visit our Integration page.
Step-by-Step Tutorial: Set Up an Amazon Redshift Data Warehouse
The first step of your data warehouse journey is to create a free Amazon Web Services, or AWS account, and log into it. After doing that, you’re ready to start a Redshift instance. But first, you’ll have to set up and connect an IAM role.
1) Set Up Your IAM Role
Without getting too technical, your IAM role allows you to access data from AWS instances called Amazon S3 (Simple Storage Service) buckets. S3 buckets are like file folders in the AWS ecosystem. These “buckets” contain data and descriptive metadata. The IAM role provides a data connection, so your Redshift cluster can access the data in your S3 buckets. Use the instructions and images that follow to set up your IAM role.
Click this link to go to the IAM console. Then click the Roles link:

Click Create Role.

Click Redshift.

Next,
- Click Redshift – Customizable.
- Click Next: Permissions.

On the “Attach Permissions Policies” page:
- Enter "AmazonS3ReadOnlyAccess" into the Search field
- Select the checkbox.
- Click Next: Tags.

You may want to "tag" your IAM role so it’s easy to find. You can do this by entering any tag you want into the Key field.

Name your IAM role:
- Enter the desired name for the role. (this is a required field).
- Click Create Role.

You’ll now see your IAM role on the list of roles:

2) Set Up a Cluster for Your Redshift Data Warehouse
According to Amazon: “An Amazon Redshift data warehouse is a collection of computing resources called nodes, which are organized into a group called a cluster. Each cluster runs an Amazon Redshift engine and contains one or more databases.”
To set up a Redshift cluster for your data warehouse, you need to open your Redshift Management Console and click the Quick Launch Cluster button.
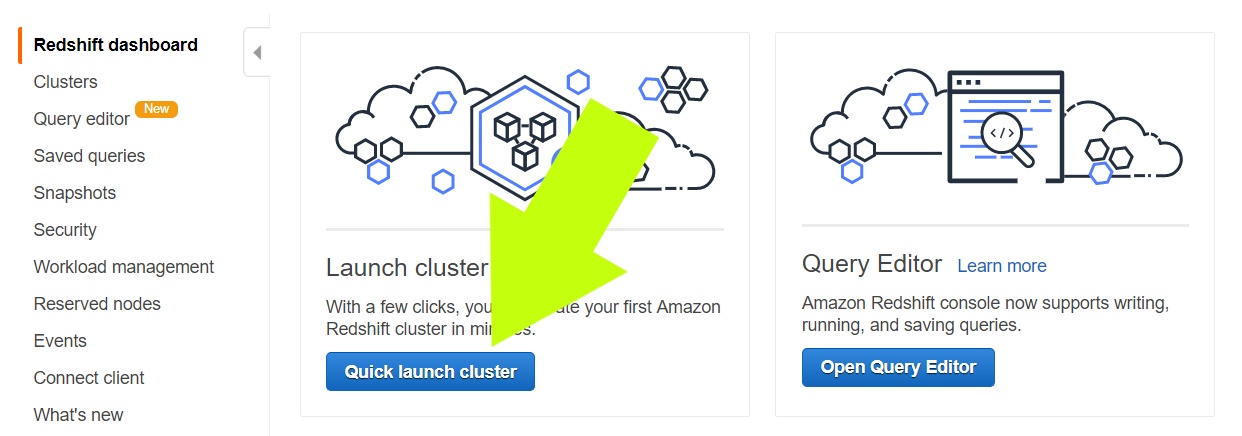
Next, you’re going to configure a basic cluster that keeps you eligible for Amazon’s free tier. This configuration shouldn’t trigger any charges at the time of this writing, but it is advisable to check Amazon's latest pricing tiers before proceeding.
If you understand your future data needs, and know you’ll need a larger setup, consider a bigger node type than the default “dc2.large.” Otherwise, leave all of the default settings as they are and complete the following steps:
- Choose a password for your cluster.
- Attach your newly created IAM role to the cluster by selecting it from the drop-down titled Available IAM Roles.
- Launch the cluster.

NOTE: Look at arrow #2 in the image above. Do you see the text with letters and numbers in the blue box under “TestRole”? These are the credentials for your IAM role. Copy them and save them in a file. You will need them when you’re importing data into your data warehouse.
Congratulations, your cluster is launching! You can watch the progress by clicking the Clusters link on the left of the screen.

3) Secure Access to Your Redshift Data Warehouse
After your cluster is ready, but before you integrate data into the cluster, it’s vital to adjust the access settings to make sure your data warehouse is secure.
To secure access to your Redshift cluster:
- Navigate to the Redshift Console and click Clusters.
- Click on your newly created cluster, which should be the only one on the list (see image below).

You should now be on the Configuration tab. In the Cluster Properties section, click the link beside VPC Security Groups. It will say default along with some numbers and letters as per the image below.

In the next screen:
- Select the Inbound tab.
- Click Edit.

Configure the following settings:
- Under “Type,” select “Custom TCP Rule.”
- Under “Protocol,” select “TCP.”
- Under “Port Range,” type 5439. This will be the same port you set when launching the cluster.
- Under “Source,” select “Custom IP” and input the IP address you’ll use to connect to the database (and any other IP addresses you or your team plan to use). Don’t know your IP address? Go here, or just select “My PI.”
- Click Save.

Loading Data Onto Your Redshift Data Warehouse
After securing access to your data warehouse, you can begin loading data. Amazon provides sample data in an S3 bucket that’s ready to load, so we’ll use that for this tutorial. However, you may want to load your own data by following the same instructions we have outlined below.
1) Configure Your Tables
First, you’ll configure the schema for the tables that will hold your data. For that, you'll need to access the Query Editor.
Go back to the Redshift Management Console and click Open Query Editor.

The system may prompt you to fill out a few fields. Use the same data from Section 3 to fill out these fields (See Image 11 above for this data).
Once you're in the Query Editor, you will cut-and-paste some data to create the schema for your first tables.

Amazon offers several pipe-delimited text files to cut-and-paste and create schema for various tables. Create your tables one-by-one with the following steps:
- Cut-and-paste the table schema for User Table (see data below) into the query text field.
- Click the “Run Query” button.
- Wait for the query to complete.
- Click “Clear.”
- Repeat the process for the rest of the tables (see data below).
Here's the code you'll cut-and-paste into the query field to create a variety of tables:
Create User Table
create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean);
Create Venue Table
create table venue( venueid smallint not null distkey sortkey, venuename varchar(100), venuecity varchar(30), venuestate char(2), venueseats integer);
Create Category Table
create table category( catid smallint not null distkey sortkey, catgroup varchar(10), catname varchar(10), catdesc varchar(50));
Create Date Table
create table date( dateid smallint not null distkey sortkey, caldate date not null, day character(3) not null, week smallint not null, month character(5) not null, qtr character(5) not null, year smallint not null, holiday boolean default('N'));
Create Event Table
create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp);
Create Listing Table
create table listing( listid integer not null distkey, sellerid integer not null, eventid integer not null, dateid smallint not null sortkey, numtickets smallint not null, priceperticket decimal(8,2), totalprice decimal(8,2), listtime timestamp);
Create Sales Table
create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp);
2) Load Data Into Your Tables
Now you’ll connect the tables to the information in the Sample S3 Buckets. You’ll do this with the following cut-and-paste commands. Enter the commands, one-by-one, into the query field – just like you did when creating the tables.
IMPORTANT: You’ll need the IAM credentials you saved in Step #3 (above). In each of the commands below, replace the text “am-role-arn with the text of your own credentials.
Here's the code you'll cut-and-paste into the query field to connect the data to your tables:
Load Users Data
copy users from 's3://awssampledbuswest2/tickit/allusers_pipe.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '|' region 'us-west-2';
Load Venue Data
copy venue from 's3://awssampledbuswest2/tickit/venue_pipe.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '|' region 'us-west-2';
Load Category Data
copy category from 's3://awssampledbuswest2/tickit/category_pipe.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '|' region 'us-west-2';
Load Date Data
copy date from 's3://awssampledbuswest2/tickit/date2008_pipe.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '|' region 'us-west-2';
Load Event Data
copy event from 's3://awssampledbuswest2/tickit/allevents_pipe.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '|' timeformat 'YYYY-MM-DD HH:MI:SS' region 'us-west-2';
Load Listing Data
copy listing from 's3://awssampledbuswest2/tickit/listings_pipe.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '|' region 'us-west-2';
Load Sales Data
copy sales from 's3://awssampledbuswest2/tickit/sales_tab.txt' credentials 'aws_iam_role=arn:aws:iam-role-arn' delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS' region 'us-west-2';
Redshift Queries
Now that you’ve loaded your data warehouse with information, it’s time to practice writing a few basic SQL queries.
Query All Data From User Table
SELECT * FROM users
The result should look like this:

Query Total Sales For a Specific Date
SELECT sum(qtysold) FROM sales, date WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
The result should look like this:

Get creative and invent some fresh queries of your own!
Integrate.io: Advanced Solutions for Data Warehouse Use Cases
This was a simple example of how to create a basic data warehouse. You can use this data warehouse to integrate data from all the databases and applications related to your company, like data pertaining to: marketing, accounting, payroll, clients, customers, vendors, distributors, scheduling, shipping, production, billing, warehousing, customer satisfaction, market research, advertising, public relations, and more.
Having all of this information in one place will help you make better business decisions, but how do you get the data in there? Redshift interfaces with a wide range of data types. However, not all of your data will readily fit into your warehousing solution.
Whether you're an experienced data guru or a "data newbie", data integration challenges are a massive headache. This is where Integrate.io can help. When you encounter data integration bottlenecks, Integrate.io's advanced ETL solutions help you extract and transform all kinds of data to work with your data warehouse through both our pre-configured integrations and REST API component.
Don't worry! Integrate.io is a lot easier to use than you think! Contact the Integrate.io team now to learn about our powerful, easy-to-use data integration technologies.




