
- Introduction
- Understanding Data Wrangling
- The Importance of Data Wrangling
- Data Wrangling vs. ETL
- Data Wrangling Techniques in 2025
- Trends Shaping Data Wrangling in 2025
- Challenges and Pitfalls in Data Wrangling
- Conclusion
Navigating the complex world of data, businesses often grapple with raw, unstructured information; this is where data wrangling steps in, turning chaos into clarity. Seamlessly intertwined with ETL processes, data wrangling meticulously refines and prepares data, ensuring it's not just ready but optimized for insightful analysis and decision-making.
To understand the nuances and impact of this process, let's delve into the key insights from the article:
- The data wrangling process is crucial for transforming raw, messy data into clean, structured, and analyzable information, serving as the foundation for robust data analytics.
- Data wrangling techniques are evolving to include automation, AI-driven tools, data integration providers, data enrichment, and real-time processing.
- Common challenges in data wrangling include handling missing data, outliers, data quality, complex data structures, and ensuring seamless data integration.
- Automation and AI are becoming pivotal in data wrangling, streamlining the process, reducing manual effort, and enhancing data quality.
- While data wrangling focuses on cleaning and preparing data for analysis, ETL is a structured process for large-scale data movement and integration, with both being essential for ensuring data quality and usability.
In this article, we will explore the importance of data wrangling, ETL, and powerful tools to help manage and leverage data for more robust data analytics.
Introduction
Data wrangling—also known as data munging or data cleaning—is the art of shaping and refining raw datasets and making them ripe for analysis. It's the crucial process that enables data scientists and analysts to extract the hidden gems within the vast landscape of data.
Imagine being granted access to a treasure chest filled with new data insights, each one holding the potential to inform your holistic data analysis. Data wrangling is the process of meticulously cutting, shaping, and polishing these raw data gems, so they can be transformed into actionable insights.
Understanding Data Wrangling
While the term 'data wrangling' encompasses data munging and cleaning, it's more than just tidying up datasets. It's a comprehensive process that involves validation, transformation, and integration, ensuring data is not only clean but also in the right format and structure for subsequent analysis.
Why Data Wrangling is a Critical Step in Data Analysis
Data wrangling serves as the foundation upon which robust data analytics is built. In the vast landscape of data analytics, where insights are the ultimate goal, data wrangling is the crucial initial step that sets the stage for meaningful exploration.
Consider raw data as gold dust scattered amidst impurities. Data wrangling is similar to the gold extraction process, where the dust is meticulously separated from the impurities, refined, and molded into a valuable gold bar. Just as unprocessed gold dust can't be used directly in jewelry or trade, raw data, with its challenges like missing values, outliers, and inconsistent formats, can lead to inaccurate analysis and unreliable insights. Through data wrangling, we ensure that the data is not only clean but also structured and ready for meaningful analysis.
By subjecting data to the rigors of data wrangling, we ensure that the data is in its best possible state before analysis. It's the process of turning raw data into a polished gem, ready to shine its light on the path to data-driven insights.
Check out: 7 Best Data Analysis Tools
The Importance of Data Wrangling
Why is data wrangling indispensable in the world of data analytics? The answer lies in the sheer complexity and diversity of datasets we encounter. In the quest for knowledge, data scientists and analysts grapple with data from diverse data sources that come in different formats, structures, and qualities. This is where data wrangling comes to the rescue.
At its core, data wrangling ensures data quality, identifying and fixing issues with outliers, missing values, and inconsistencies. It transforms raw data into a structured, clean, and coherent format, ensuring that it is both usable and reliable. Without data wrangling, the data analytics process would be akin to building a house on an unstable foundation—prone to collapse and yielding unreliable results.
Looking Ahead to 2025
As we look to the future, the world of data wrangling is poised for exciting developments in 2025. With the ever-growing influx of data, the challenges and opportunities it presents will continue to evolve. From advancements in machine learning and algorithms to harnessing the power of big data, data wrangling will remain at the forefront of innovation in the field of data science.
We will delve deeper into the techniques, tools, and trends that will shape the landscape of data wrangling in 2025. From exploring the role of artificial intelligence to addressing the specific needs of industries like healthcare, we will embark on a journey to unravel the mysteries of data wrangling and equip you with the knowledge to harness its true potential.
Data Wrangling vs. ETL
Data Wrangling primarily focuses on the cleaning and preparation of raw data for analysis. It deals with transforming messy, unstructured, or inconsistent data into a structured format. Data wrangling often occurs closer to the analysis phase and is characterized by its flexibility and adaptability. It's an iterative process where data is refined and shaped to meet the specific needs of data scientists and analysts.

On the other hand, ETL (Extract, Transform, Load) is a comprehensive data integration process that involves extracting data from various sources, transforming it (in-flight) into a standardized format, and then loading it into a target database or data warehouse. This is in contrast to ELT (Extract, Load, Transform), where data is first extracted, then loaded into the destination data warehouse, and transformations are performed there. ETL is more structured, automated, and is designed for large-scale data movement and integration. It's commonly used in scenarios where data needs to be synchronized across different systems or for business intelligence purposes.
Both data wrangling and ETL are essential for ensuring data quality and usability, but they serve distinct roles. Data wrangling focuses on cleaning, transforming, and enriching raw data, often in preparation for exploratory data analysis. ETL, on the other hand, is a method that can incorporate data wrangling during its 'transformation' phase. In the ETL process, data is extracted from sources, transformed (which can include data cleansing and other wrangling tasks), and then loaded into a target system. While data wrangling is more flexible and adaptable, ETL is structured and ideal for integrating large datasets into databases or data warehouses.
What is the Best ETL Method for Data Analysis?
Understanding the distinction between data normalization, ETL, and data wrangling is essential for data professionals. Data normalization is primarily used for BI applications, formatting data into a structured form that's optimal for reports and models. This can be done both at rest (in the database) and in flight (during data transfer).
ETL, on the other hand, is a process designed for transferring data between applications. When it comes to data wrangling, cleansing, or normalization, the 'transformation' phase of ETL serves as the method to apply these functions while the data is in transit from one application to another.
For data professionals navigating the evolving landscape of data analytics, proficiency in data wrangling, understanding of data normalization, and expertise in ETL processes can be invaluable assets.
Learn more here: Data Wrangling vs. ETL: What’s the difference?
Integration with Other Data Processes
Data wrangling, while a critical step in the data lifecycle, doesn't operate in isolation. It's a pivotal component of a larger data pipeline that encompasses various stages, from data collection to final analysis and visualization.
- Pre-Wrangling Phase: Before data wrangling comes the data collection or ingestion phase. Whether it's from IoT devices, user interactions, or third-party APIs, raw data is accumulated in data lakes or databases. The quality and format of this data can vary, setting the stage for the wrangling process.
- Post-Wrangling – Data Visualization: Once data is cleaned and transformed, it's often visualized to identify patterns, trends, and anomalies. Tools like Tableau, Power BI, and Matplotlib rely on well-wrangled data to produce meaningful visual representations.
- Machine Learning and AI: For data scientists building predictive models, data wrangling is a precursor to feature engineering and model training. Clean, structured data ensures that machine learning algorithms can be trained effectively, leading to more accurate predictions.
- Real-time Analytics: As businesses move towards real-time decision-making, the wrangled data feeds into real-time analytics tools. This allows organizations to react promptly to emerging trends or issues.
Data wrangling is an essential part of making the most out of data. Being able to structure and manipulate data sets can unlock insights into a variety of areas, including machine learning, AI, and real-time analytics. This understanding of data is essential for organizations to make timely and accurate decisions.
Data Wrangling Techniques in 2025
As we step into the future of data analytics, the landscape of data wrangling is evolving at a rapid pace. In 2025, data wrangling is not just a necessary step; it's an art form, continually refined to meet the demands of the ever-expanding world of data. In this section, we'll explore the techniques that will define data wrangling in 2025.
Overview of Traditional Data Wrangling Methods
Traditionally, data wrangling involved a labor-intensive process. Data scientists and analysts would roll up their sleeves and delve into spreadsheets, scripts, and manual interventions to clean and prepare data. While effective, these methods were often time-consuming and lacked scalability, making them less suitable for big data and real-time analytics.
Python emerged as a savior for many data wranglers. With its versatile libraries like pandas, data manipulation became more efficient. Yet, challenges remained, especially when dealing with large datasets or complex data structures.
Emerging Techniques for Efficient Data Wrangling
In 2025, data wrangling is all about efficiency, speed, and adaptability. Here are some emerging techniques that are shaping the future of data wrangling:
Automation and AI
Automation is the buzzword in modern data wrangling. AI-driven tools can identify patterns, outliers, and data quality issues in real-time, significantly reducing the manual effort required for data cleaning. Machine learning algorithms can even suggest data transformations based on historical patterns.
Data Integration Providers
Data integration providers offer end-to-end solutions for data wrangling. They enable seamless data integration from diverse sources, handle ETL (Extract, Transform, Load) processes, and provide data enrichment capabilities. These platforms offer user-friendly interfaces that empower data analysts to perform complex data transformations without coding.
Enriching and Reshaping Data
Data wrangling is not just about cleaning data; it's about enriching it. Tools and techniques can augment datasets with external data sources, enriching them with additional context. Moreover, data reshaping techniques allow for quick pivoting and restructuring of data to fit specific analysis needs.
Real-Time Data Wrangling
Real-time analytics demands real-time data wrangling. With the increasing importance of data points arriving in real-time, data wranglers are focusing on tools that can process and clean data as it flows in, ensuring that analytical models are always fed with the latest, high-quality data.
Challenges in Real-time Data Wrangling
The rise of real-time analytics has brought with it the need for real-time data wrangling. This presents unique challenges:
- Speed: Traditional data wrangling processes might not be fast enough for real-time needs. Tools and techniques need to operate at the speed of incoming data, ensuring it's cleaned and transformed without causing lags in the analytics process.
- Data Consistency: With data streaming in continuously, ensuring consistency becomes a challenge. For instance, if a data source changes its format or introduces new fields, the wrangling process must adapt on the fly.
- Scalability: As the volume of real-time data grows, the wrangling processes must scale accordingly. This requires robust infrastructure and tools capable of handling large data inflows without degradation in performance.
- Error Handling: In a real-time scenario, there's little room for error. If an issue arises during the wrangling process, it needs to be addressed immediately to prevent disruptions in downstream analytics.
- Continuous Iteration: Unlike batch processing, where data wrangling might be a one-off or periodic task, real-time wrangling requires continuous iteration and refinement as data patterns evolve.
We found this video on 12 data wrangling functions in Python that you might find interesting
Importance of Automation in Data Wrangling
Automation is the linchpin of modern data wrangling. In a data landscape characterized by different formats, varying data sources, and large datasets, manual data cleaning and transformation simply cannot keep up.
By automating data wrangling processes, organizations can:
- Save Time: Automation reduces the time spent on repetitive data cleaning tasks, allowing data professionals to allocate more time to analysis and decision-making.
- Enhance Data Quality: AI-driven automation can identify and rectify data quality issues in real-time, ensuring that the data used for analysis is of the highest quality.
- Improve Usability: Automated tools often come with user-friendly interfaces, making data wrangling accessible to a broader audience within an organization.
The data wrangling landscape in 2025 is characterized by a shift towards automation, AI-driven techniques, and user-friendly platforms that empower data scientists and analysts to work more efficiently with diverse datasets. These advancements are essential in meeting the increasing demands of data analytics, particularly in the context of big data and real-time analytics.
Trends Shaping Data Wrangling in 2025
Artificial Intelligence and Machine Learning in Data Wrangling
Artificial intelligence (AI) and machine learning (ML) have become integral to data wrangling processes. These technologies bring a level of automation and intelligence that was previously unimaginable.
- AI-Powered Data Cleaning: AI-driven algorithms can automatically detect and clean messy data. They identify patterns, outliers, and inconsistencies, making data cleaning a more efficient and accurate process.
- Automated Data Transformation: ML models can recommend data transformations based on historical patterns, streamlining the process of structuring data for analysis. This not only reduces manual effort but also improves the quality of data transformations.
- Predictive Data Enrichment: AI can predict missing values and enrich datasets by drawing from external sources. This is particularly valuable when dealing with unstructured data, as AI can help contextualize it for analysis.
Big Data Challenges and Solutions
Big data presents unique challenges and opportunities for data wrangling:
- Scalability: With the exponential growth of data, the scalability of data wrangling processes becomes paramount. Modern tools and platforms are designed to handle large datasets efficiently, ensuring that data wrangling doesn't become a bottleneck.
- Real-Time Data: The need for real-time analytics necessitates real-time data wrangling. Data points arriving in real-time must be cleaned, validated, and integrated on the fly to support timely decision-making.
- Data Variety: Big data is often diverse, coming from various sources in different formats. Data wrangling tools are evolving to handle this diversity seamlessly, ensuring that data can be integrated and transformed regardless of its source or format.
The Role of Data Governance and Compliance
Today where data privacy and compliance are paramount, data governance plays a critical role in data wrangling:
- Data Privacy: Regulations like GDPR and CCPA require organizations to handle data with the utmost care. Data wrangling processes must incorporate data masking, anonymization, and other privacy measures to ensure compliance.
- Data Auditing and Provenance: Data governance includes tracking the lineage of data, ensuring that every transformation and integration step is auditable. This transparency is essential for maintaining data quality and compliance.
- Collaboration and Documentation: Modern data wrangling tools emphasize collaboration and documentation. Data wranglers can annotate and document their actions, making it easier to demonstrate compliance with regulatory requirements.
Data wrangling in 2025 will be marked by the infusion of artificial intelligence and machine learning, which will not only streamline the process but also enhance data quality. The challenges posed by big data are being met with scalable and real-time solutions. Additionally, data governance and compliance have become integral to the data wrangling process, ensuring that data is handled responsibly and in accordance with regulations.
As we navigate the evolving landscape of data wrangling, it becomes evident that this field is at the heart of data analytics. It's the bridge that transforms raw data into actionable insights, enabling data scientists, analysts, and organizations to make informed decisions. In the next section, we will delve into real-world case studies and success stories that highlight the practical impact of data wrangling on decision-making and business outcomes.
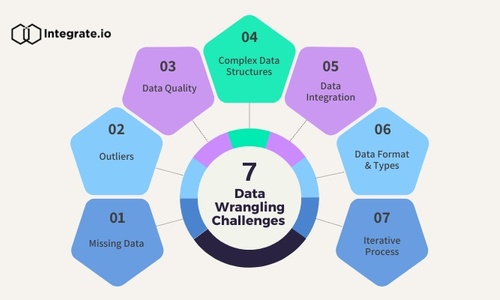
Challenges and Pitfalls in Data Wrangling
Data wrangling, while essential, is not without its challenges and potential pitfalls. Let’s explore some of the common issues encountered during the data wrangling process and strategies to overcome these challenges.
Common Issues Encountered During Data Wrangling
- Missing Data: Incomplete datasets with missing values can pose a significant challenge. It's crucial to decide whether to impute missing values, exclude incomplete records, or find alternative data sources to fill the gaps.
- Outliers: Outliers can skew analysis results. Identifying whether an outlier is a genuine data point or an error is critical. Handling outliers may involve transformations or the creation of outlier-specific models.
- Data Quality: Ensuring data quality is a perpetual challenge. Inaccurate or inconsistent data can lead to erroneous conclusions. Regular data quality checks and validation procedures are essential.
- Complex Data Structures: Dealing with data in various structures, such as nested or hierarchical formats, can be complex. Data wranglers need to reshape these structures into a usable form.
- Data Integration: Integrating data from multiple sources, each with its own schema and format, requires careful mapping and alignment. Mismatches can lead to data inconsistencies.
- Data Format and Types: Handling diverse data formats (e.g., CSV, JSON, XML) and types (e.g., text, numerical, categorical) demands versatile tools and techniques.
- Iterative Process: Data wrangling is often an iterative process, requiring continuous refinement. Keeping track of changes and ensuring reproducibility is challenging but crucial.
Strategies to Overcome Data Wrangling Challenges
- Data Profiling: Start by thoroughly understanding your data. Profiling tools can help identify missing values, outliers, and data quality issues.
- Automate Where Possible: Embrace automation and AI-driven tools to expedite the data cleaning process and reduce manual errors.
- Data Governance: Establish clear data governance practices to maintain data quality, lineage, and compliance.
- Documentation: Document every step of the data wrangling process. Clear documentation aids in transparency, collaboration, and compliance.
- Collaboration: Encourage collaboration among data professionals, domain experts, and data wranglers to collectively address challenges and ensure data accuracy.
- Regular Updates: Data wrangling is not a one-time task. Set up processes for regular updates, especially for real-time data sources.
Future Outlook
The future of data wrangling is promising and ever-evolving. Beyond 2025, we can anticipate several trends and developments that will shape this field:
- Further Automation: Automation will continue to play a pivotal role in data wrangling, with AI and ML algorithms becoming even more sophisticated in identifying and addressing data issues.
- Integration with Data Science Platforms: Data wrangling will become seamlessly integrated with data science platforms, providing a unified environment for data professionals.
- Increased Emphasis on Data Ethics: As data privacy regulations evolve, data wrangling will incorporate ethical considerations and compliance measures as fundamental aspects.
- Data Wrangling as a Specialized Skill: Data wrangling will emerge as a specialized skill set, with dedicated professionals and certifications.
Conclusion
In conclusion, data wrangling is the cornerstone of effective data analytics. It transforms raw data into actionable insights, enabling data scientists and analysts to make informed decisions. While it comes with challenges, embracing automation, data governance, collaboration, and continuous learning are key strategies to navigate the evolving landscape of data wrangling.
As we look to the future, data wrangling will remain a dynamic field, adapting to the demands of big data, artificial intelligence, and data ethics. It's a field of endless possibilities, and those who master it will be at the forefront of data-driven innovation.
Empowering Your Data Journey with Integrate.io
In the realm of data analytics, data wrangling stands as the pivotal bridge between raw data and actionable insights. Its true potential, however, can only be fully realized with the right tools and resources.
At Integrate.io, we recognize the intricacies and challenges of data wrangling in today's dynamic landscape. Our platform is uniquely designed to cater to both ETL and ELT processes, offering a comprehensive solution that streamlines your data preparation and integration needs.
ETL vs. ELT: Flexibility with Integrate.io
- ETL Capabilities: With our ETL solution, data wrangling is performed while the data is in flight, allowing for efficient transformation before it reaches its destination. This ensures that your data is already structured and cleaned by the time it's loaded into the target system.
- ELT Capabilities: Recognizing the growing trend and benefits of ELT, especially with modern data warehouses like Snowflake, Redshift, and BigQuery, our platform facilitates data wrangling post-loading. This means you can harness the computational power of these warehouses to efficiently wrangle large datasets, making the process faster and more scalable.
With Integrate.io, you can:
- Ensure Data Quality: Our platform prioritizes data quality, offering features to validate, clean, and enrich your datasets.
- Seamless Integration: Whether you're using ETL or ELT, integrate data from diverse sources with ease, ensuring it's ready for analysis.
- Real-Time Capabilities: Stay ahead in real-time data scenarios, with our platform's ability to process and wrangle data as it flows in, regardless of the chosen method.
The flexibility of Integrate.io, supporting both ETL and ELT, sets us apart in the market. Not every competitor offers such adaptability, making us a preferred choice for many data professionals.
To explore the dual capabilities of Integrate.io and how they can benefit your data-driven projects, we invite you to take advantage of our 14-day free trial. Experience firsthand how our platform can simplify your data wrangling challenges, enhance data quality, and accelerate your analytics journey.
For a more personalized exploration, our experts are on standby to provide a free demo of the platform. Dive deep into the features, ask questions, and discover how Integrate.io can seamlessly fit into your data projects, irrespective of your preference for ETL or ELT





