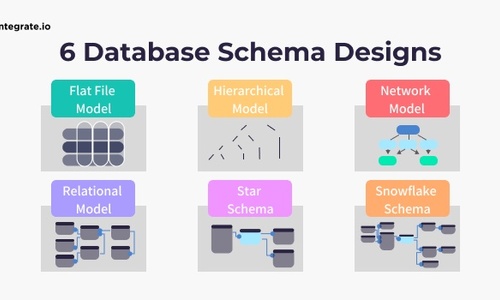

- Why is Choosing The Right Schema Important?
- Flat Model
- Hierarchical Model
- Network Model
- Relational Model
- Star Schema
- Snowflake Schema
- Optimize Your Data Management with Integrate.io \
We know a lot of thought goes into database construction. Before creating any database, developers spend time planning what it will include and how everything will work together. This planning phase is crucial, as it helps ensure that a database has the right design for its intended use.
Here are some use cases for the 6 most popular schemas:
- Flat model: Best model is for small, simple applications.
- Hierarchical model: For nested data, like XML or JSON.
- Network model: Useful for mapping and spatial data, also for depicting workflows.
- Relational model: Best reflects Object-Oriented Programming applications.
- Star model: For analyzing large, one-dimensional datasets.
- Snowflake model: For analyzing large and complex datasets.
Database schemas are the blueprints that help developers visualize how databases should be built. They provide a reference point that indicates what fields of information the project contains. If there are any issues or confusion while building the database, developers can simply refer to the schema and it should have all the answers.
Data administrators also use schemas to work through potential issues long before implementation. This saves valuable time and money because, once a database is implemented, making changes can be difficult. When choosing a schema, all stakeholders must fully consider every aspect of the project to reduce the likelihood that major changes are needed down the line.
In this guide, we'll break down six of the most popular database schema examples and discuss the considerations and use cases surrounding each one.
Why is Choosing The Right Schema Important?
Choosing the wrong database schema for a project can lead to debilitating bottlenecks in an application and costly refactoring. For example, if you didn't realize early on that your application would rely on several table JOINs, your service will eventually grind to a halt when you reach a certain number of users and data.
To resolve this, data will likely have to move to new tables, code will have to point to those new tables, and then those tables will need the proper JOINs. This means you will need a strong test environment (database and source code) to test your changes, a plan to manage data integrity, and a plan for updating your database and source code simultaneously.
Once you start migrating your database to a new schema, there is almost no turning back. Choosing the correct database schema in the first phase can eliminate a lot of anguish and heartache throughout the life of a software project.
Flat Model
A flat model database structure is a single, two-dimensional array where elements in each column are the same type of data, and elements in the same row relate to each other.
Think of this as a single, unrelated database table, like an Excel spreadsheet. If you run a small business with a handful of employees and want to store only their salary information, then a single, flat data model will suffice. This model abides by the KISS principle.

Hierarchical Model
Hierarchical database schemas have a tree-like structure, with a "root" node of data and child nodes that branch out from that root. There is a one-to-many relationship between parent and child nodes. This type of data schema is best reflected in XML or JSON files, where an entity can have sub-entities that are not shared with other entities.
A hierarchical database structure is great for storing nested data, such as the study of taxonomy.

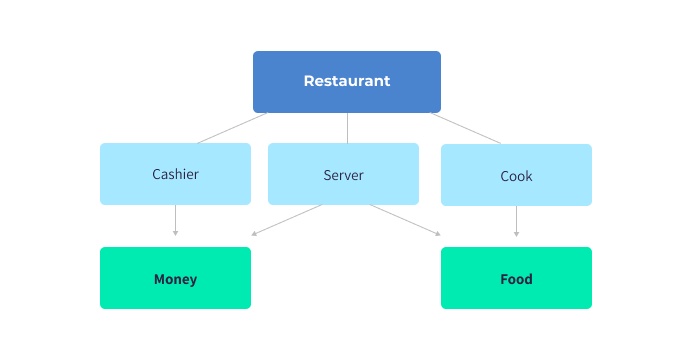
Network Model
The network model is like the hierarchical model in that it represents a series of nodes and vertices; however, unlike the hierarchical model, it allows many-to-many relationships. From a theoretical standpoint, this means the graph can have cycles. A cycle in the graph indicates that there is a path of vertices in which you can start and end at the same node.
Billions of dollars lie in a company's ability to efficiently move its goods from point A to point B, and thus, a deep understanding of how to apply the network model is vital. Most applications that need spatial calculations would likely benefit from having data stored inside a network-modeled database. GIS (Geographic Information Systems), is software that enables users to efficiently store and analyze mapping data.
A network model is also useful when depicting workflows, especially when there are multiple paths to the same result. Take a restaurant chain, for example, where a typical workflow is a server telling the cook what to make. The cook will whip up each dish on the ticket and announce, "Order up!" The server will then grab the plate and do a final quality assurance to make sure it's what the patron asked for. In this scenario, there is a many-to-many relationship between the food and the different categories of employees. Thus, this workflow would best be structured using a network database structure.
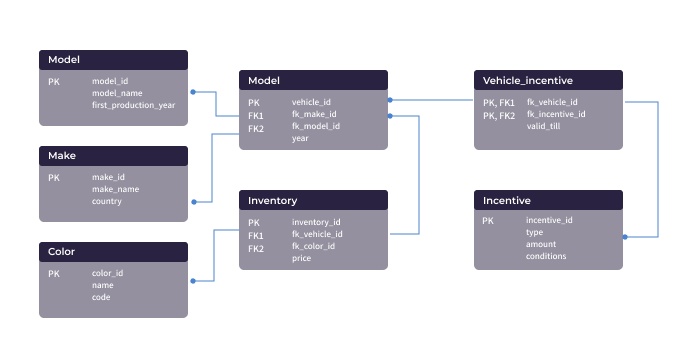
Relational Model
The introduction of the relational database model ushered in a new era of data processing. Interestingly, the inventor of the relational database, Edgar Codd from IBM in the 1970s, had a different definition of what "relational" meant.
However, through decades of use, the programming community has settled on a more universal understanding of what a relational database is. That is, we store data as relations (i.e. tables), and there are relational operators that we perform on the data to manipulate and calculate things from it.
With that in mind, relational databases are best thought of as a series of entities, some of which relate to each other in certain ways. It's important to think of each entity as separate. If you're building out a piece of software that follows the Object-Oriented Programming approach, it would be best to store each object's data as its own table with the database.
Here's a good relational database schema example: If you're programming a car, you might have an object for the tires, axles, engine, seats, paint, etc. The tires attach to the axles, which spin because of the engine, and so on. Representing each of these objects as their own table, with a link between the appropriate entities (tire to axle, axle to engine, etc.) would be an optimal way to neatly store data and understand how the car works.
People use Relational Database Management Systems to manage their relational databases. Read our deep dive on RDBMSs here.
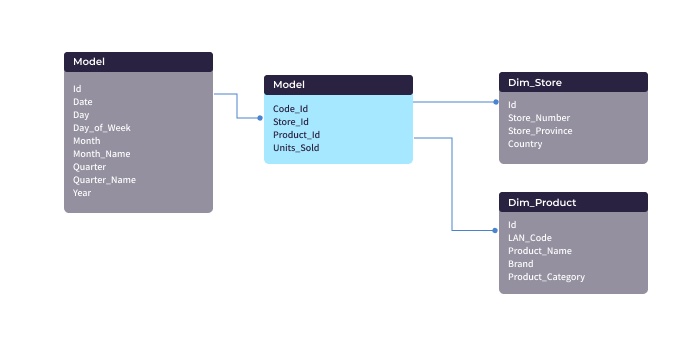
Star Schema
When you visualize a star database schema example, things start to get a little more interesting. A star schema is a different way to organize your data. It makes for some of the best database design examples when storing and analyzing massive amounts of data. One of the reasons the star schema shines is that it relies on the usage of "facts" and "dimensions."
A "fact" is a numerical data point that drives business processes, and a "dimension" is a description of that fact. Using car sales numbers, for example, the "fact" table would contain information about the number of units sold, and a corresponding "dimensional" table would have the colors of those cars.
The cool thing about star schemas is that they're simply abstractions on top of traditional relational databases. That is, if you have an RDBMS, you can use it to structure your data into a star schema database structure.
Related Reading: Snowflake Schemas vs. Star Schemas
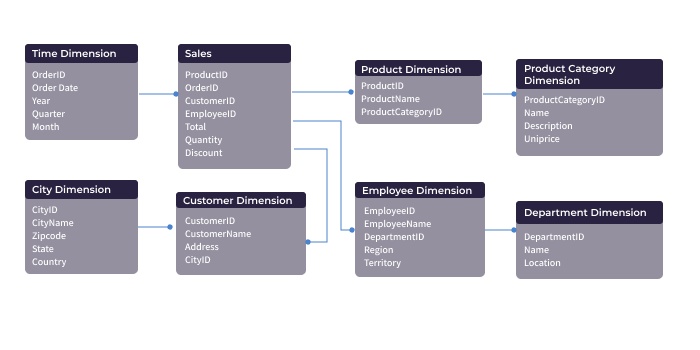
Snowflake Schema
As the star schema is an adaptation of the relational database model, the snowflake schema is an adaptation of the star schema. Its name derives from how one would depict an entity-relation diagram (ERD) of a snowflake schema: you guessed it, it starts to look like a snowflake.
As with the star schema, the snowflake schema has a central fact table that stores the main data points and references to its dimensional tables. Unlike the star schema, the snowflake schema dimensional tables can have their own dimensional tables, thus expanding how descriptive a dimension can be.
Using our car database schema example, let's say the operations department needs to forecast which resources they'll need for building their cars. Like the sales department, they will want to know which cars have been sold, and how many.
In the database schema example above, we had a dimensional table indicating the color of the cars sold. The operations department might want to know more about the paint other than color: brand, cost, number of coats, and so on. In this scenario, a snowflake schema would be useful because the color dimensional table requires its own dimensional tables (paint brand, cost, number of coats, etc).
Optimize Your Data Management with Integrate.io
Ultimately, you can choose any of these database design examples to structure your new database, but it's critical that you choose wisely. If you're starting from scratch, take the time to sit down with key stakeholders and assess your database's size and complexity. Also consider the type of information you'll be storing, and map out the relationships of all those data points long before anyone dives into the code.
While the planning phase might seem overwhelming at first, it will save you countless hours of rework in the long run and lead you down the path to a powerful, reliable database schema that your business can count on for years to come.
As you plan your new database structure, it's also a great opportunity to look at how your data is stored, moved, and utilized. If you need help building a no-code data integration pipeline capable of processing even the most complex and massive datasets, look no further than Integrate.io.
With Integrate.io, you can design and execute no-code data pipelines using the most advanced ETL/ELT platform available. Start your 14-day free trial and see it in action for yourself.




