


- Why ETLT With Integrate.io, Snowflake Software, and dbt?
- How to Create an ETLT Strategy with Integrate.io, Snowflake, and dbt
- Final Thoughts on ETLT with Integrate.io, Snowflake, and DBT
- FAQs
What do Integrate.io, Snowflake software, and dbt (data build tool) have in common? When used together, they merge the best ETL (extract, transform, load) and ELT (extract, load, transform) into a powerful, flexible, and cost-effective ETLT (extract, transform, load, transform) strategy.
In this guide, we’ll show you how to create an ETLT strategy with Integrate.io, Snowflake software, and dbt tool for Snowflake. But first, we’ll explain why you'd want to use this strategy to build an ETLT data transformation stack.
Why ETLT with Integrate.io, Snowflake Software, and dbt?
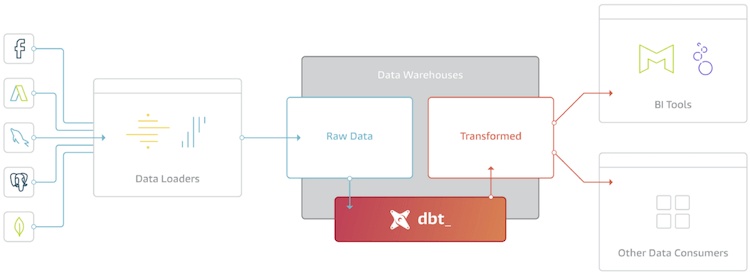
Let’s take a bird's-eye view of the benefits of ETLT and those that come with using Integrate.io, Snowflake software, and dbt data integration:
ETLT Benefits
To understand the benefits of ETLT, we need to start with some background information about its advantages and limitations for data integrations.
In recent years, ELT has become more popular than ever. For some use cases, it’s outpacing the traditional ETL at the heart of data-sharing infrastructure. This is primarily because of the emergence of cloud data warehouse platforms like Snowflake. These data warehouses are so powerful and efficient that they can quickly and cost-effectively transform big data within the warehouse after loading.
Before cloud data warehousing solutions like Snowflake software, carrying out post-load transformations on an onsite legacy data warehouse was slow, impractical, and expensive. But now, post-load ELT transformations are easier and more affordable to achieve.
The primary advantages of ELT are that it skips the initial staging area of ETL, bypasses the need to design and carry out preload transformations, and loads raw data directly into the data warehouse. This lets you ingest and save massive amounts of unstructured data in something close to real-time. It also offers the scalability to structure (and restructure) data later according to your unique data analytics requirements.
However, there are serious limitations to an ELT-only strategy. These limitations primarily relate to compliance and data security. Industry-specific compliance rules often require the masking, encryption, or removal of sensitive data before loading it into virtual warehouses or data lakes.
Even if you are not beholden to such restrictions, you must protect and secure your data when using cloud computing services such as virtual warehouses. You will do this to prevent data breaches, boost security, protect your organizational secrets, and build client and customer trust.
Still, if you want the benefits of ELT, you might need to add a pre-load transformation layer (ETL) to the workflow. In such situations, most organizations simply stick with ETL and decide that the benefits of ELT are not available to them. However, there is a third approach to data integration that merges the best of both worlds: ETLT.
With an ETLT workflow, you perform the minimum required preload transformations to adhere to applicable data compliance standards. Then you load the data into the data warehouse and use the processing power of the data warehouse to manage the rest of the transformations.
Let’s review the most significant benefits of an ETLT data integration strategy:
Compliance: ETLT allows you to meet compliance and data security requirements for preload data transformations and still benefit from ELT’s fast data ingestion and the flexibility to change your business logic as needed.
Data masking: This permits the pseudonymization of data so you can adhere to compliance standards that prohibit sensitive PII (personally identifiable information), PHI (protected health information), and IIHI (individually identifiable health information) from leading back to any specific person. This compliance may apply to you under the European Union’s GDPR, HIPAA, or another regulation.
Customer trust: By elevating your levels of data security, ETLT helps build customer trust.
Better security: Through greater security, ETLT reduces the threat of damage from privacy breaches, hacks, and other security-related failures.
Faster ingestion: ETLT speeds up data ingestion while maintaining strict security standards.
For more information regarding ETLT, read our article on this best-of-both-worlds approach to data integration.
Integrate.io Benefits
Integrate.io is an ETL-as-a-Service tool that offers a wide range of immediate connections for virtually any data source, cloud-based service, database, virtual warehouse, or onsite system. Once connected to the source, Integrate.io extracts your data into the Integrate.io staging area. From there, Integrate.io performs the data transformations that you set up via an easy-to-use, visual interface, and loads the data into the data warehouse.
When using Integrate.io in an ETLT process, you will perform only a minimum number of lightweight transformations within Integrate.io — such as masking, removing, or encrypting sensitive data for compliance. By keeping preload transformations simple, you can load your data into the data warehouse as quickly as possible. More complex transformations (like JOINing tables, data enrichment, etc.) will happen in the data warehouse itself.
The three primary benefits of using Integrate.io for your preload transformations are:
Speed: Integrate.io’s wide range of source and destination connections, and its ready-made transformations, let you develop an ETL workflow in minutes. As a cloud-native, fully hosted solution, Integrate.io is ready to build ETL pipelines as soon as you first log into the platform.
Ease of Use: The Integrate.io platform is so easy to operate that anyone can develop ETL workflows. If you’re a complete ETL beginner, a dedicated Integrate.io integration specialist is always available to help you design the integration pipelines your use case requires.
Affordability: When you use Integrate.io, you pay a flat-rate, monthly fee based on how many connectors you’re using. You don’t pay extra for sending more data through the pipeline, and you don’t pay more for processing in-pipeline transformations. This SaaS-like pricing structure means payments are affordable and predictable.
Snowflake Software Benefits
Snowflake software is a powerful data warehousing solution built on the Amazon AWS or Microsoft Azure infrastructure. Like all cloud services, it doesn't require any dedicated on-premises hardware or software. Since the pandemic, Snowflake has emerged as a major player in the cloud data platform space thanks to a successful initial public offering and some heavy investment from Warren Buffett's Berkshire Hathaway.
With the wide array of cloud data warehousing options — like Amazon Redshift, Oracle, BigQuery, and Microsoft Azure SQL Data Warehouse — why would you choose Snowflake software to pair with dbt? Mani Gandham offers this concise explanation of how Snowflake differentiates itself from similar cloud services:
“[Snowflake] offers a unique blend of features that sit between all of these existing options. It stores data in cloud storage for easy cloning, replication, and time-travel/snapshot queries, unlike the others. It separates compute from storage like BigQuery for faster scaling and unlimited concurrency. It still has a concept of a multi-cluster of servers like Amazon Redshift/Azure SQL DW but simplifies management to just size. It supports low-latency queries similar to an always-running multi-cluster like Redshift while scaling up to unlimited datasets like BigQuery. Another major advantage is much better JSON and unstructured data handling along with a very fast and powerful UI console.”
For more information on Integrate.io's native Snowflake connector, visit our Integration Page.
dbt Benefits
dbt is a free, open-source product that performs post-load transformation within the data warehouse itself. By allowing you to program data transformation processes in SQL, dbt lets you build in-warehouse data pipelines.
Here’s how the dbt team describes the solution:
“dbt is the T in ELT. It doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse. This “transform after load” architecture is becoming known as ELT (extract, load, transform).”
“dbt is a tool to help you write and execute the data transformation jobs that run inside your warehouse. dbt’s only function is to take code, compile it to SQL, and then run against your database.”
The dbt team also adds the following in their documentation:
“dbt (data build tool) enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles turning these select statements into tables and views.”
“dbt also enables analysts to work more like software engineers, in line with the dbt viewpoint.”
After using Integrate.io to perform necessary transformations for data compliance and loading the data into Snowflake, the final stage of your ETLT process uses dbt to perform the rest of the transformations that PIVOT, aggregate, JOIN, SELECT, and GROUP BY — whatever the specific type of data analysis decision-makers require.
Ultimately, this ETLT method preserves your ability to load large volumes of data into Snowflake by keeping your Integrate.io transformations as simple as possible. Then it uses dbt to perform transformations within the Snowflake software according to the needs of your use case.
How to Create an ETLT Strategy with Integrate.io, Snowflake, and dbt
As referenced above, the first step of your ETLT cloud data warehouse strategy involves Integrate.io, which extracts data from the source and performs basic transformations that remove/mask/encrypt PHI and PII. After that, Integrate.io loads the data into Snowflake. From there, dbt manages the final data transformations within Snowflake per your needs.
You’ll find detailed instructions for setting up the Integrate.io side of your ETLT equation here.
After using Integrate.io to transform and load your data into Snowflake, it’s time to develop the rest of your transformation workflow with dbt. For this stage, you’ll need some general SQL skills.
However, before we dive into an example of how to create a dbt pipeline, it will help to understand a few things about dbt’s features and components.
The following three sections and examples are largely distilled from an article by John L. Aven and Prem Dubey published on the Snowflake website and Medium.com.
dbt: Features and Components
Here are some general characteristics of dbt:
- ELT developers can create transformation workflows coded as SQL. The SQL queries are “models” within a transformation “package.”
- dbt models are created by a SQL statement. They are simply a table, i.e., a view of the data found in the data warehouse (Snowflake in this case).
- dbt lets you version your SQL query models for testing.
- Each model features reference links to create a DAG (Directed Acyclic Graph), which saves the query order and data lineage as it occurs via the models.
As for its components, dbt comprises three different file types: SQL (.sql), YAML (.yml), and MARKDOWN (.md). The .sql files save the models and tests, like the SQL statements that create the table/view of the data you transform in the warehouse. Some .sql files could be ephemeral and only persist when executing the pipeline. The .yml files store configurations for the dbt project in a project configuration file, and they store configuration and testing information in a schema file. The .md files are optional. They store the documentation for your models.
Installing dbt and Understanding Available Modules
dbt recommends installing the solution via pip and prefers using pipenv. After installation, you’ll use ‘dbt init’ to set up a new project. The dbt project you create can include different types of modules, such as models, analysis, tests, docs, macros, etc.
Here are the most common dbt modules:
Model: A directory that includes .sql files that form your ELT pipelines. Executed in sequence, these create the transformation pipeline.
Test: A directory that includes .sql files that execute tests on the data. You can create a test model that checks if specific values meet your exact specifications, along with other custom tests.
Macro: A directory that includes .sql files created with Jinja. According to dbt documentation: “In dbt, you can combine SQL with Jinja, a templating language. Using Jinja turns your dbt project into a programming environment for SQL, giving you the ability to do things that aren't normally possible in SQL.” Because these are macros, you can use these again and again, and you can combine them to create more complex processes.
Docs: A directory that includes optional documentation formatted into .md files.
Logs: A directory that includes run logs. dbt creates and saves run logs when you execute the “dbt run” command.
Target directories: dbt creates target directories when you compile, build or run documentation. These hold metadata and the SQL code that you've compiled.
Analysis: A directory that includes ready-to-go SQL queries you can use anytime to provide different views of your data for data analytics purposes. You may have a variety of these analyses saved for use, but they are not part of the project's data transformation workflow.
You can learn more about these and other modules in the dbt documentation.
Setting Up dbt on Snowflake
Setting up dbt on Snowflake requires putting the profiles.yml file in the ~/.dbt directory of the machine that is executing the process. You’ll also need to include the ‘sf’ profile information in the dbt project.yml profile field after filling it out with your unique information.

Develop Your Data Transformation Pipeline
Now you’re ready to create a data pipeline. Snowflake offers an excellent example of how to do this with dbt by using a string of transformations from a publically available dbt/Snowflake software demo, which offers the TPC-H benchmark datasets. In the following example, we’ll see how John L. Aven and Prem Dubey achieved their desired analytics view of these datasets by aggregating:
- Average account balance for all customers in a nation
- Average available quantity for each product, regardless of supplier
- Average supply cost for each product, regardless of supplier
Aven and Dubey aggregated this information into a table with the following columns:
- Customer Name
- Customer Account Balance
- Market Segment
- Nation
- Part Available Quantity
- Part Name
- Part Manufacturer
- Part Brand
- Part Type
- Part Size
- Region
- Supplier Account Balance
- Supplier Name
- Supply Cost for each Part and Supplier Pair
Next, they chose the following series of SQL transformations to achieve their desired analytics view. By choosing to filter the data through sequential transformations like this (as a package), it’s easier to keep your bearings and make sure you have made no mistakes. Here’s the pipeline:
1) supplier_parts: JOIN three tables (PART, SUPPLIER, PARTSUPP) on the PARTKEY field and the SUPPKEY field. This step creates an ephemeral table.

2) average_account_balance_by_part_and_supplier: Compute the average aggregation for the supplier account balance by part and supplier. This step creates an ephemeral table.

3) average_supply_cost_and_available_quantity_per_part: Calculate the average aggregation of the supply cost and available quantity, calculating by part for the supplier. This step creates an ephemeral table.

4) supplier_parts_aggregates: JOIN the aggregations to the supplier parts table. This step creates a permanent new table.

5) customer_nation_region: JOIN the three tables (CUSTOMER, NATION, REGION) by the NATIONKEY. This step creates an ephemeral table.

6) average_acctbal_by_nation: Calculate the average_customer_account_balance over the nation field. This step creates an ephemeral table.

7) customer_nation_region_aggregates: JOIN the average_customer_account_balance to the customer_nation_region table. This step creates a permanent new table.

8) analytics_view: JOIN customer_nation_region_aggregates to supplier_parts_aggregates. This is for a BI Dashboard.

That’s the completion of your transformation pipeline! Keep in mind that each model includes reference links to generate a DAG (Directed Acyclic Graph), so dbt makes it easy to see a visual graph that shows the sequence and logic behind your SQL transformations.
Now that you’ve seen how to design a dbt data transformation pipeline, the next step involves connecting this data to data analytics and BI solutions to perform analyses, create graphs, and display and share your data with team members and decision-makers.
Final Thoughts on ETLT with Integrate.io, Snowflake Software, and dbt
This guide has given you a general understanding of the what, why, and how behind creating an ETLT data integration strategy with Integrate.io, Snowflake software, and dbt. We hope you’ll consider Integrate.io for your next cloud data platform integration project.
As an enterprise-grade, ETL-as-a-Service solution, Integrate.io brings power and scalability to your ETLT pipeline. The Integrate.io team is always available to help you meet your goals. Contact us now to test drive our 14-day pilot.
FAQs
Q: What is dbt on Snowflake?
dbt (Data Build Tool) on Snowflake is a data transformation tool that allows data analysts and engineers to write, test, and document SQL-based transformation workflows directly within the Snowflake data warehouse. dbt manages the "transform" step in the ELT (Extract, Load, Transform) process, enabling users to build modular, version-controlled, and testable data models using SQL, which are then executed within Snowflake for efficient, scalable data processing.
Q: What is dbt in ETL?
In the ETL (Extract, Transform, Load) context, dbt is responsible for the "T"—the transformation of data. Unlike traditional ETL tools that extract, transform, and then load data, dbt is designed for the ELT paradigm: data is first loaded into the warehouse (like Snowflake), and dbt then transforms it using SQL models. dbt does not handle extraction or loading but excels at transforming and modeling data already present in the warehouse, supporting best practices such as testing, documentation, and version control.
Q: Is dbt a good ETL tool?
dbt is an excellent tool for the "Transform" step in modern ELT workflows, especially in cloud data warehouse environments like Snowflake. It is not a full ETL tool since it does not perform data extraction or loading, but it is highly regarded for its transformation capabilities, modular SQL modeling, built-in testing, and robust documentation features. dbt is particularly favored by analytics engineers for its developer-friendly workflow, scalability, and integration with version control systems.
Q: Which ETL tool is best for Snowflake?
The best Snowflake ETL tool depends on the specific requirements of your data pipeline:
-
Integrate.io, Fivetran, Stitch, Talend: Popular choices for extraction and loading data into Snowflake, often used in combination with dbt for transformation.
-
Matillion: An ETL/ELT platform with native Snowflake integration, offering a visual interface for building data pipelines.
A typical best-practice stack is to use an ETL tool like Fivetran or Stitch for extraction and loading, and dbt for transformation within Snowflake, leveraging the strengths of each.
Summary Table
| Tool | Functionality | Strength with Snowflake |
|---|---|---|
| Integrate.io | Transform (ETL) | Automated connectors, easy setup, transformation capabilities |
| Fivetran | Extract, Load (ELT) | Automated connectors, easy setup |
| Stitch | Extract, Load (ELT) | Simplicity, cloud-native |
| Matillion | Extract, Load, Transform | Visual interface, native support |
| Talend | Extract, Load, Transform | Enterprise features, flexibility |
dbt is not a full ETL tool but is the leading choice for transformation in Snowflake-centric data architectures.



