


- Documents, Explained
- How to Build a Database
- The Information Environment Over Time
- The Problem of Finding Text in Documents
- A Continually Advancing Problem
- Investing in a Textual Warehouse
- How Integrate.io Helps With Textual Data
This is a guest post by computer scientist Bill Inmon, recognized as the “father of the data warehouse.” Bill has written 60 books in nine languages and is currently building a technology called textual ETL.
Here are five things to know about textual warehouses:
-
Ecommerce organizations like yours have lots of documents that include information about customers, sales, marketing, and inventory processes.
-
When document-based textual data exists in several databases, it can be difficult to locate, especially when data exists in silos.
-
Moving data to a textual warehouse can make it easier to find that data.
-
Creating your own textual warehouse is relatively straightforward if you have the right tools.
-
Integrate.io helps you move document-based textual data (and other structured data) to a conventional data warehouse or can help you create your own textual warehouse.
Imagine this scene. One day, someone in your ecommerce organization wakes up and can’t locate the information they need to prospect leads or check inventory processes. They know the information exists somewhere, but they can’t find it. As a result, they miss out on opportunities and can’t make important business decisions.
The simple fact that information exists in the corporation and no one can find it is a real issue for ecommerce enterprises. Losing information (or having information that can’t be found) is simply a way of life.
But does it have to be that way? No, it does not. Misplaced data in an ecommerce organization might be of the transactional variety. The problems of organizing and finding this operational, transaction-based data is well documented. Data dictionaries, repositories, and directories have been around for as long as there have been computers. But there is another type of data that has almost gone unnoticed, and that is document-based textual data. For a variety of reasons, data in a document is as slippery as a fish on the banks of a stream.
In this post, learn about the challenges of locating document-based textual data, the benefits of a textual warehouse, and how a solution like Integrate.io makes it easy to create a single source of truth (SSOT) for unstructured data.
Integrate.io is a data warehouse integration solution built for ecommerce that moves unstructured data from text documents, chat logs, and emails to a data warehouse via low-code/no-code ETL data pipelines. You can then operationalize and analyze this data through business intelligence tools. Email hello@integrate.io to learn more.
Documents, Explained
I am going to focus on documents used in ecommerce organizations like yours. When you create a document or share it with someone in your enterprise, it looks like this:

The document can be about anything. It can be about the terms of a sale. It might be a contract with a customer purchasing your products or services. It might contain inventory information. There are absolutely no restrictions as to what a document can contain.
The only assumption made in this post is that there is something of business importance contained in the document. Otherwise, there is no point in capturing the document. In some cases, there is a lot of business importance contained in the document. In other cases, there is less business importance. But somewhere, to some extent, there is something important to your business in the document.
So what happens to the document once it enters the halls of your ecommerce organization? The document is essentially broken into two types of data:
-
Identifying data
-
Simple text
This division is shown here:

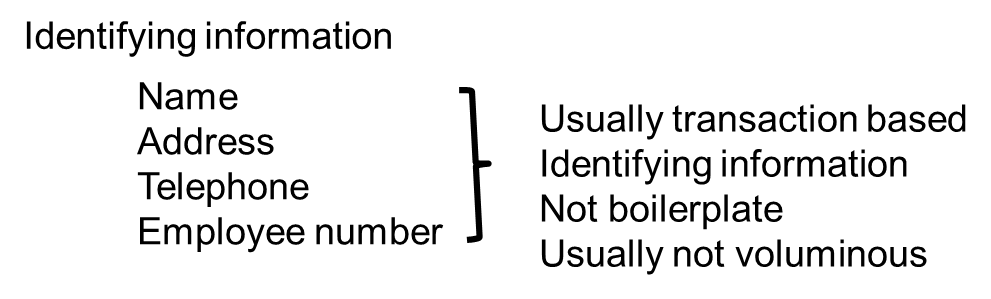
Identifying information includes information such as names, addresses, telephone numbers, email addresses, and so forth. It may also include information about employee numbers, Social Security numbers, account numbers, patient numbers (if you sell products and services to healthcare customers), or other information. The purpose of the identifying information is to allow one document to stand out from all other documents.
The identifying information in one type of document can be wildly different from the identifying information in another document. There is seldom any uniformity in identifying information when comparing one document to another.
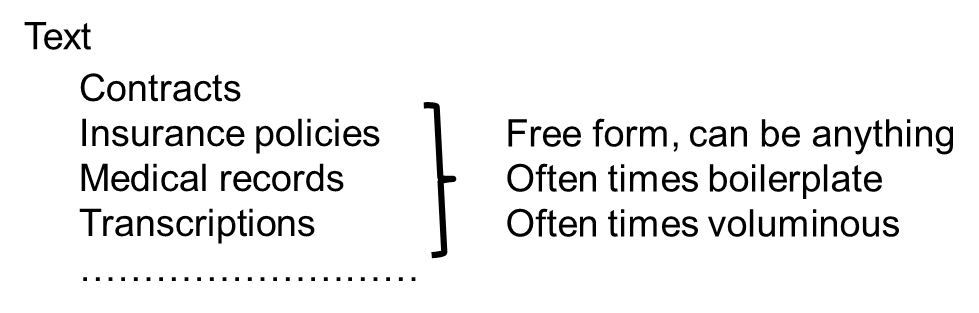
The other kind of information found in a document is simple text—descriptive information about the transaction that is being memorialized or the business activity that is being described. In the case of a contract, it may be terms, conditions, prices, and so forth.
Usually, there is a lot more information in simple text than there is in identifying information.
Once the document enters the domain of the corporation, the data capturing process begins. Data capture consists of taking the identifying information and placing that information in a standard database. Typical of the contents of the database are:
-
Names
-
Addresses
-
Telephones
-
Social Security numbers
In addition, information about the transaction or other business activity typically gets captured. Typical information might be:
-
Dates of a transaction
-
Services or products purchased
-
The amount of a purchase
-
The terms of a purchase
Identifying information and other transaction information from the document gets placed into a database.
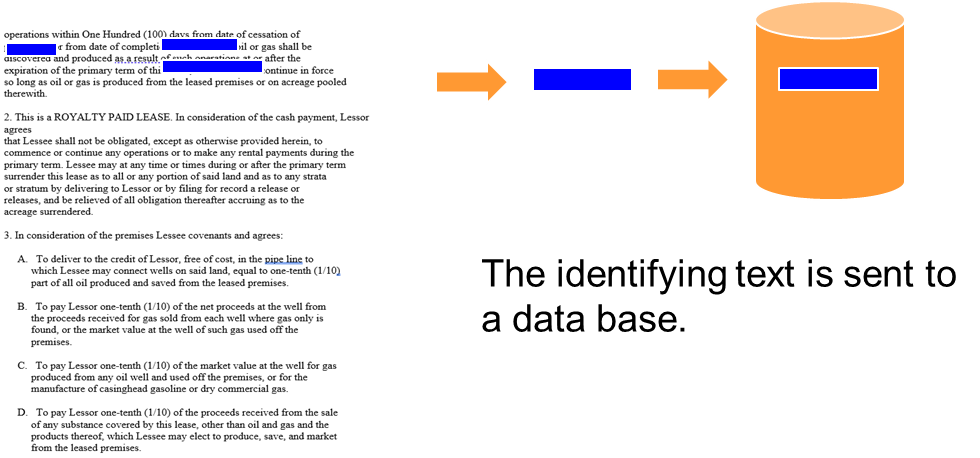
The information captured from the document includes identifying information, transaction information, and anything else needed for the day-to-day operational processing initiated by the document.
How to Build a Database
Identifying information captured in a database is not just for one document. The information captured from the document is normally from multiple documents. Databases capture all customers, sales, and transactions.

So what happens to the document that generated the identifying information into the database after the identifying information has been placed into a database? There are several things that may happen to the document.
The document may be discarded. In this case, the document owner feels that all the information needed has already been captured, and there is no point in retaining the document.
But there may be reasons why the document may still contain valuable information. In this case, the document may be subjected to OCR, which stands for Optical Character Recognition. As a result, an electronic image of the document may be captured and stored by its owner. Alternatively, the document may be stored in a paper format, typically residing in a filing drawer or a folder. There may be other dispositions of the document, but these are the most common.

But what happens when someone needs to retrieve one of these documents? As long as there are not too many documents and the data is reasonably current, there is usually not a problem. However, problems arise when many documents start to appear and/or documents start to age.
The Information Environment Over Time
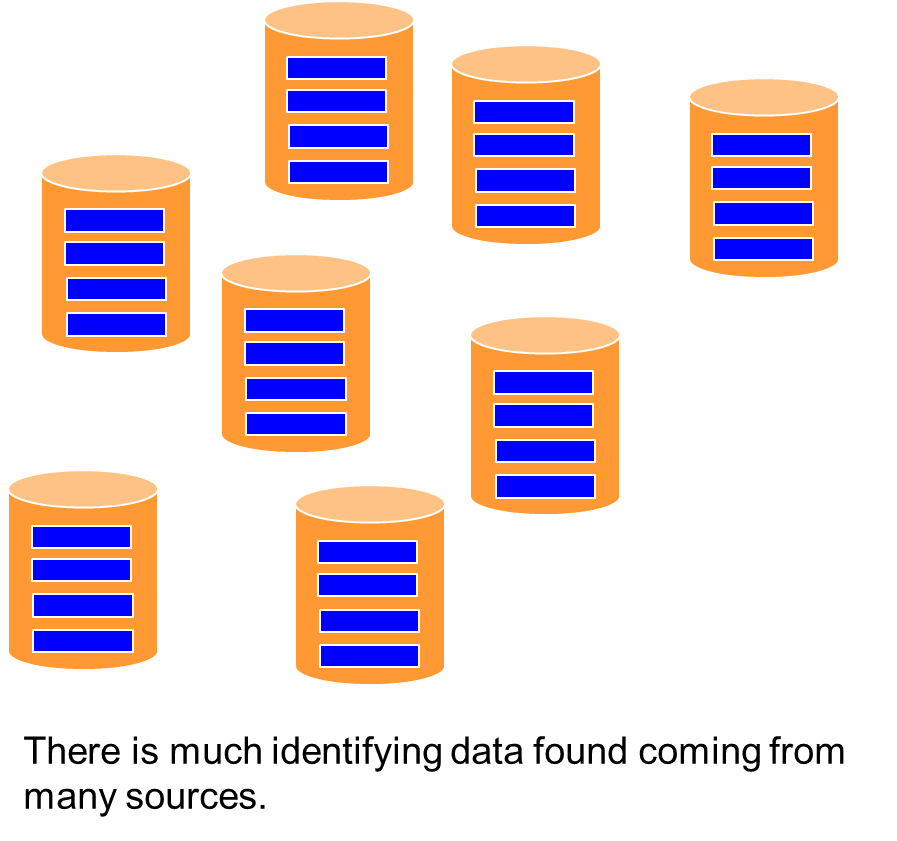
Operational databases that contain identifying data can start to grow. In the beginning, there might be a manageable number of databases. But over time, for a variety of reasons, the number of databases increases. Also, the data found in those databases can start to age.
Most IT departments in ecommerce organizations handle current data but struggle with older or archival data.
Many operational databases that collect information over time have been created without organizations thinking about data integration. Data exists in silos because all these databases can’t ‘talk’ to each, making it difficult to analyze that data.
One of the approaches used for siloed systems is to address this problem using a repository or directory (or data dictionary) that points to where the operational data lies.
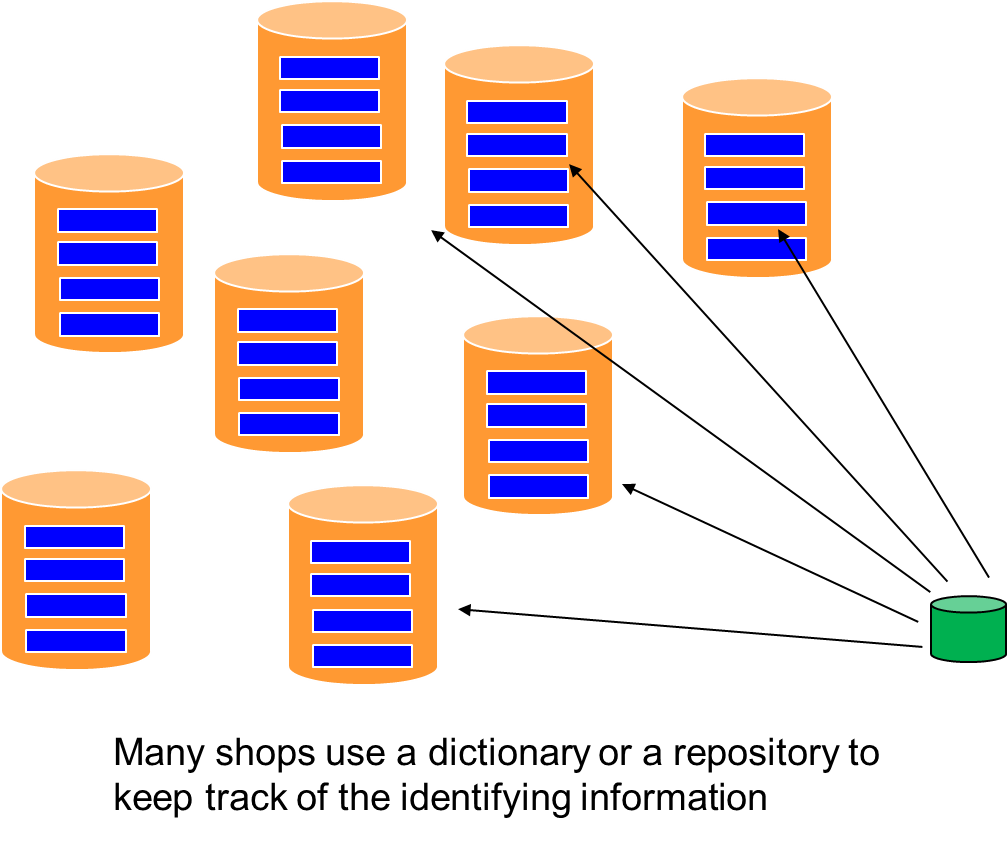
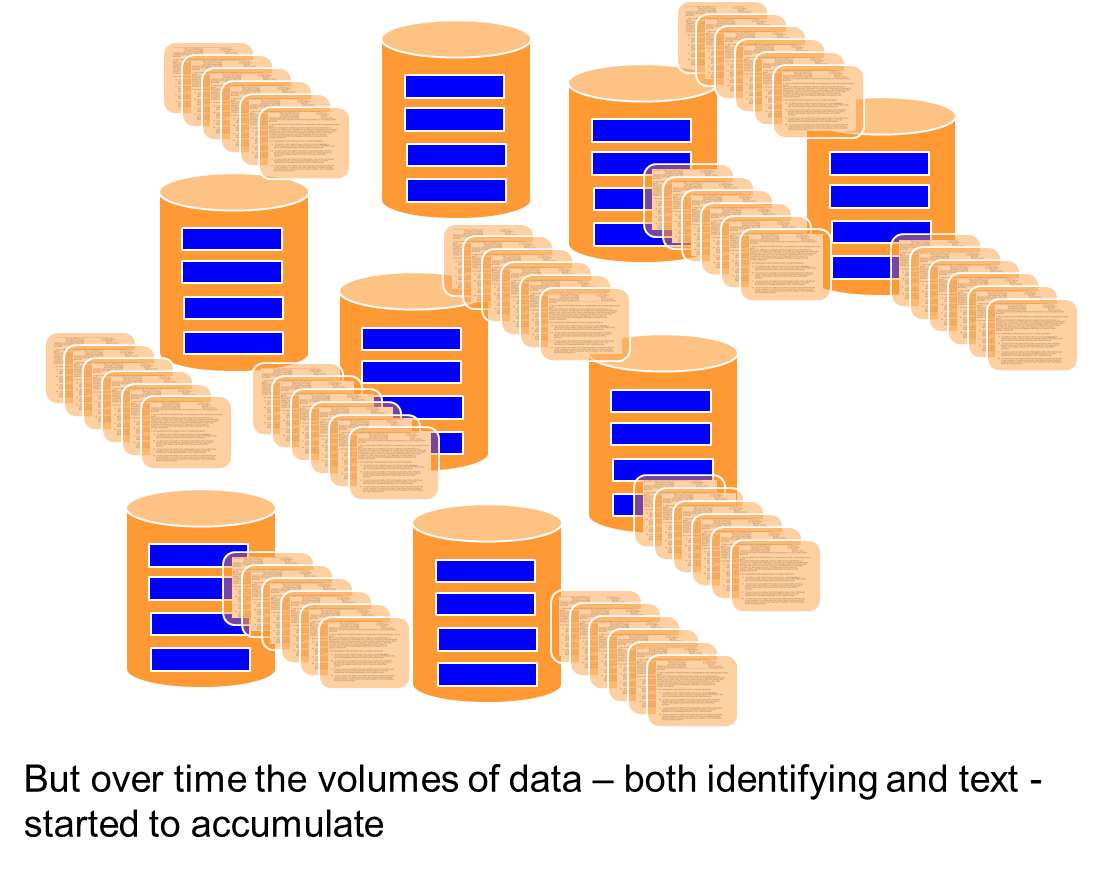
But over time, the amount of data can continue to increase. Each new record and each new file piles up on top of what is already there.
Soon the information environment is in a big mess. Nobody can find anything.
The piling on of new data over old data is roughly equivalent to what happens to archaeological artifacts over time. Each year a new layer of dust and dirt falls on the artifact. In order to retrieve the artifact, it is necessary to remove all the dirt that has collected over it over time.
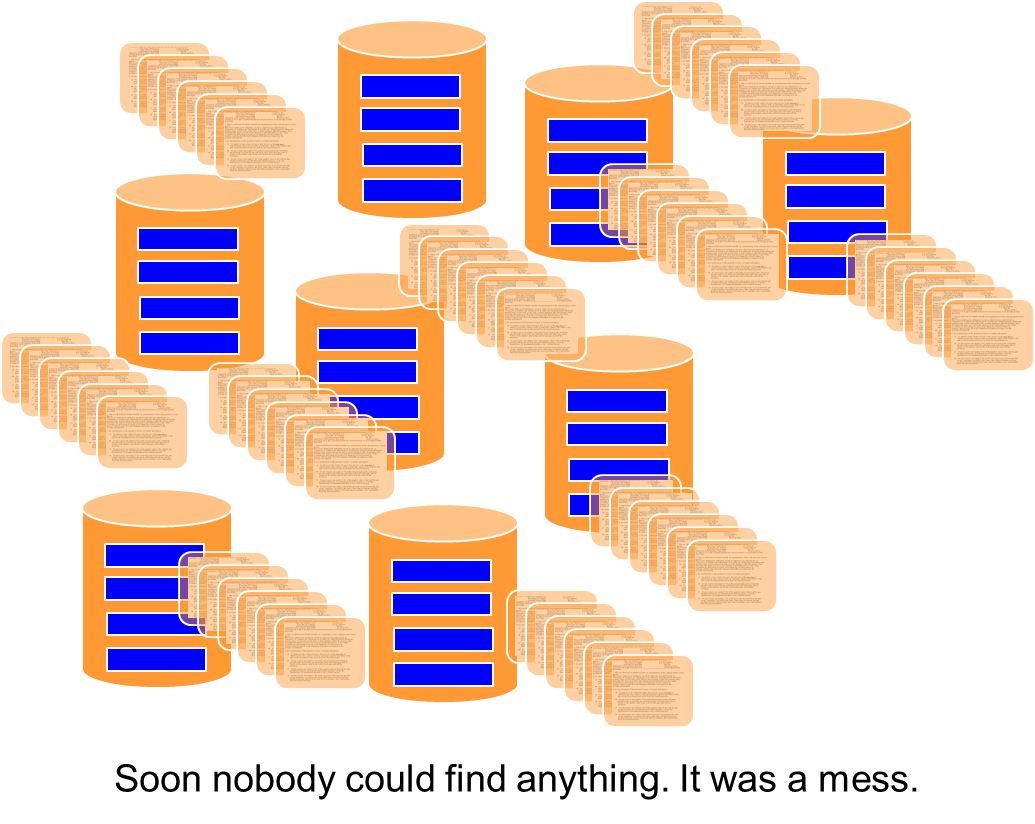
The mess being created is true for all data, including the text data that had been stored.
Integrate.io performs ETL, ELT, Reverse ETL, and super-fast Change Data Capture (CDC), helping you operationalize and analyze unstructured data from Word documents, PowerPoint presentations, and other files. Email hello@integrate.io to learn more.
The Problem of Finding Text in Documents
If text has been discarded, it’s difficult to find. Finding paper documents, for example, requires manually searching through a myriad of file cabinets. As long as there are only a few cabinets to be searched, a manual search is acceptable. But once there starts to be many cabinets, a manual search is simply not acceptable.
Many organizations store text as an OCR document (typically in a .pdf file).
But there are several problems with taking an OCR snapshot of documents. The biggest issue is that, in its simplest form, OCR is nothing but a snapshot or an image. In order to understand what is in the OCR document, you have to manually read the document.
With OCR, you can ask the OCR technology to convert what text is recognizable into an electronic format. As long as the image is clear and the text is in the right font and is readable, OCR does a good job of capturing the text that is in the image.
However, just because text gets captured and then electronically converted to text does not mean that it can be read or searched. Indeed, there are many reasons why electronically captured text cannot be analyzed. In order to be analyzed by the computer, the text needs to be disambiguated, the process of removing uncertainty from text that takes place during the data integration method Extract, Transform, Load (ETL).
In a word, OCR does not live up to all the promises made by the OCR vendor. Just because you create an OCR record of a document does not necessarily mean you can do anything with it.
What needs to happen is that the text found on the OCR documents should be placed in a textual warehouse.

If you do not have a textual warehouse, you may have to process text stored in OCR by reading the documents manually. And there is only a limited amount of analysis that can be done when reading text is done this way.

THE PROBLEM OF MANUALLY READING A DOCUMENT
Reading documents manually works if there are a small number of documents to be read. But what if there are many documents to be read? An avalanche of documents? What if documents need to be read by a specific deadline?


Or even worse, what if you are looking for documents that have information scattered across multiple documents?

In a word, manually reading documents is not a long-term or satisfactory solution.
A Continually Advancing Problem
One solution is to make do as best you can or, rather, do whatever it takes to get to the next project. But kicking the can down the road only makes matters worse. Every month new data, new documents, and new projects pile onto what is already there. Each time you add new data, the problem of finding existing data becomes worse. Trying to ignore the root problem only makes matters incrementally worse. Each day, each month, and each new document only increases the difficulty of finding data that already exists in your corporation.

You arrive at the point where finding existing data becomes a limiting factor in your ability to do business.
Transaction-based data (identifying data)suffers from the same problem. But transaction-based data is usually a little easier to search than textual data.
Investing in a Textual Warehouse
A textual warehouse is similar to a data warehouse except that it applies only to text and documents.
It helps your ecommerce organization find its text/document-based data. In many ways, the textual warehouse serves the same function as a card catalog in a library. In a large library, there is a wide collection of knowledge and books. You would never want to visit a library and walk up and down the stacks of books and examine each book on the shelves. If you tried such an approach, you would be in the library for months at a time. Instead, you go into the library and use the card catalog to direct you to where you want to go. In doing so, you save endless amounts of searching time.
Libraries have known about and have used a textual warehouse for a long time now. In a library, it is called a card catalog.

Creating a Textual Warehouse
A textual warehouse is easy to create if you have the right tools. The steps to creating a textual warehouse are:
-
OCR your documents
-
Make the text on the document electronically readable
-
Pass your text through textual ETL using an appropriate taxonomy or taxonomies
-
Create a small “working” textual warehouse
-
Load your working textual warehouse into your larger corporate textual warehouse

As a rule, you create your system-wide textual warehouse incrementally, one project at a time. You can start to use your textual warehouse as soon as you start to put data into it. But the warehouse is not complete until all documents have been processed. And, of course, as new documents enter the system, you can process and place them into your warehouse.
In many ways, the textual warehouse is the analogical equivalent to the operational data repository.
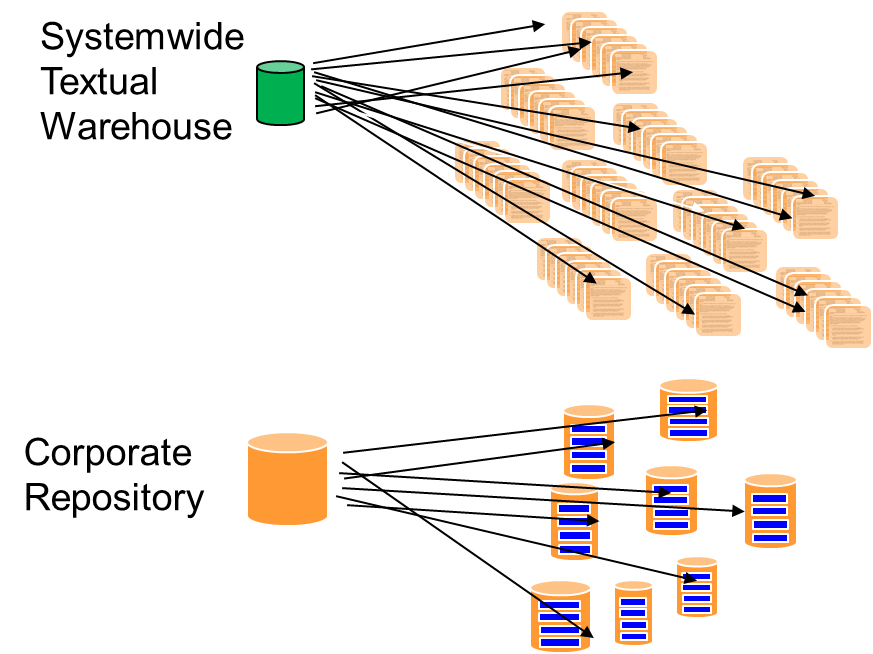
So what are the internal contents of the textual warehouse? There really are two types of content to the textual warehouse: mandated data and optional data.
Mandated Data
The mandated data in the textual warehouse looks like this:
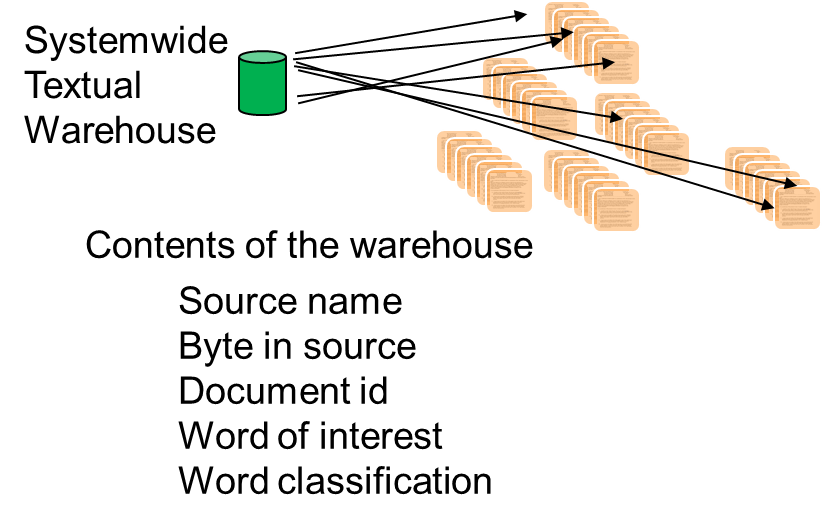
One type of mandated data is the source name. The source name is the name the system knows the document by. Another type of mandated data is the byte address of the word being referenced in the document. Another mandated type of data is the document ID. This is the external name the document is known by outside of the computer system. Next, there is the word of interest, which is the referenced word. Then there is the word classification, which is the taxonomic reference to the word of interest.
Optional Data
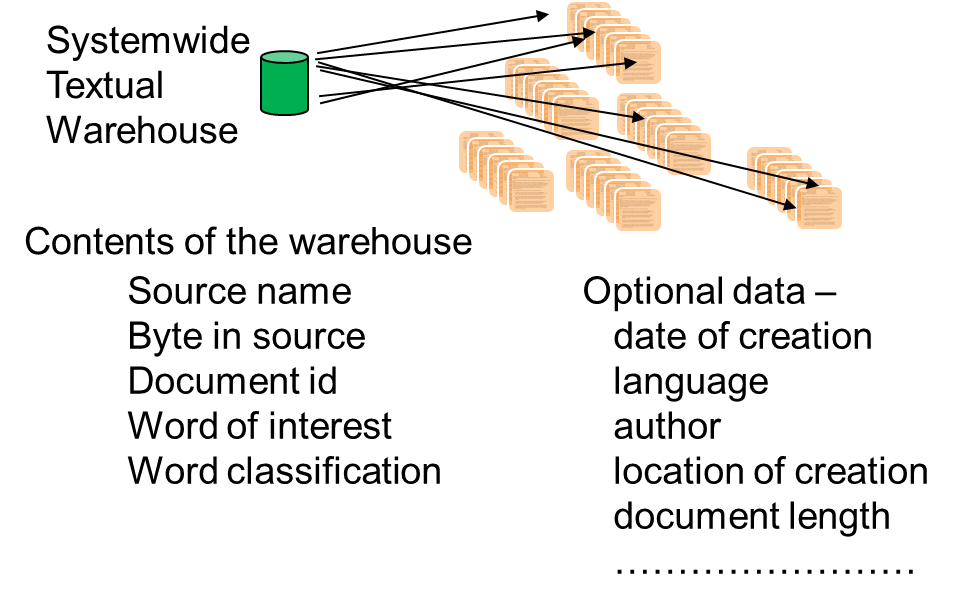
Some of the other types of data that might be included in the textual warehouse include:
-
The date of creation of the document
-
The language the document is in
-
The author of the document
-
The place the document was created
-
The length of the document
In fact, you can include any kind of data that you wish in the textual warehouse.
Once you have built the textual warehouse, you can have immediate end-user access to the documents found in your ecommerce organization.
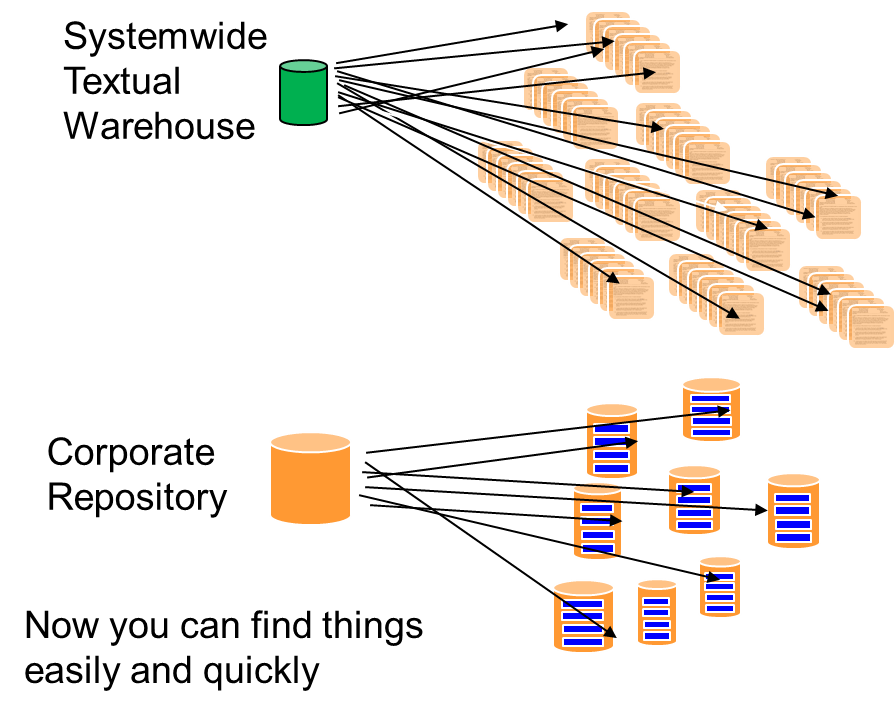
Now you can find documents and text easily and quickly throughout your company.
How Integrate.io Helps With Textual Data
Whether you move unstructured textual data to a textual or traditional warehouse, the process often requires advanced knowledge of coding and data engineering, which many ecommerce companies lack. Integrate.io helps you integrate unstructured data into a warehouse (or data lake) through its native out-of-the-box connectors. After using one of the connectors, you can run data through business intelligence tools and generate ecommerce insights about customers, sales, marketing, and inventory processes.
Other Integrate.io features include excellent customer service, simple pricing, advanced security, and compliance with data governance legislation.
Integrate.io is a new data warehouse integration platform for ecommerce that integrates unstructured data with a traditional data warehouse of your choice. Integrate.io’s philosophy is to remove the pain points commonly associated with data integration. Schedule a 7-day demo or email Integrate.io to learn more.


