


We just released a new feature for our Salesforce users: Salesforce PK Chunking! Users can now enable PK Chunking feature on Salesforce source component when pulling large data sets from Salesforce. This feature will significantly reduce job run times for Salesforce users that have millions of datasets or a large initial bulk load.
For more information on our native Salesforce connectors, visit our Integration page.
What is Salesforce PK Chunking?
PK Chunking is a Salesforce feature built for large datasets. Salesforce Primary Key (PK) is the object’s indexed record ID. Steps to use PK Chunking:
- Query the target table to identify a number of chunks of records
- Send separate queries to extract the data in each chunk
- Lastly combine the results.
Enabling Salesforce PK Chunking
By enabling this feature, Salesforce automatically splits the Bulk API Query job into multiple batches. We then poll for the progress of each of the batch then process them in parallel once all are done, resulting in significantly reduced job run times. The parallelism depends on cluster node count.
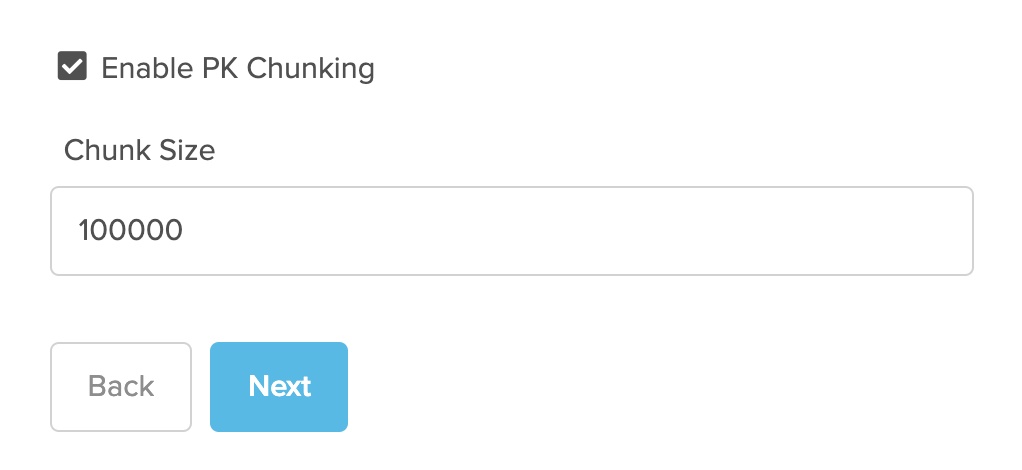
The default chunk size is 100,000, but you can use the ‘chunkSize‘ header field to configure smaller chunks or larger ones up to 250,000. It’s best to experiment with chunk sizes to figure out what works best for your needs.
Read more here: Salesforce PK chunking documentation
Contact our Integrate.io Success Engineer or email support@integrate.io, to inquire about using this feature on your account to make your large queries manageable and reduce your job run times!





