
- What is OLTP?
- What is OLAP?
- OLTP vs OLAP: A Features Comparison
- OLTP vs OLAP: The Role of ETL
- ETL Tools and Data Pipelines
- OLTP systems handle transactional data, OLAP systems handle aggregated historical data.
- OLTP systems deal with read as well as write operations, OLAP systems handle only read operations.
- OLTP systems use normalization to reduce data redundancy, OLAP systems use denormalized data for multidimensional data analysis.
- OLTP systems are built for speed, OLAP systems' speed can vary depending on the data being analyzed.
- OLTP systems are built to record everyday business transactions; OLAP systems are built for gathering business intelligence.
- OLTP systems are small in size (up to 10 GB), OLAP systems can be massive, running into several petabytes of data.
- OLTP systems deal with simple queries; OLAP systems deal with complex data analysis algorithms.
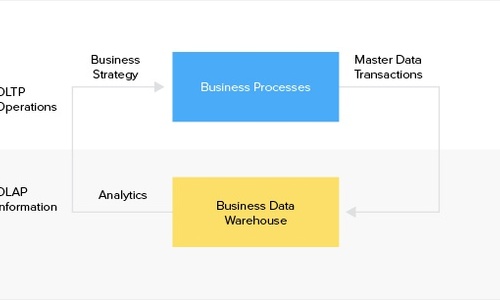
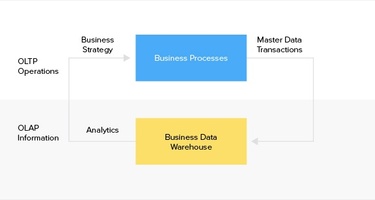
OLTP and OLAP are data processing systems. However, that's where the similarity ends between the two. The two systems serve very different purposes in the data strategy of an organization. Here's a deeper look into OLTP vs OLAP, and the role of ETL data pipelines for gathering insights from big data.
What is OLTP?
OLTP, or Online Transactional Processing works with transactional data. It captures and records transactions as individual records in a database. The simplest example where an OLTP system is used is banking. A bank keeps a record of individual transactions such as credits and debits. These records are updated frequently, which is a feature of OLTP systems.
Speed and data integrity are critical to an OLTP system. It is designed for fast read and write operations. For example, an ATM, typically, processes a transaction within seconds. An OLTP system is also high on atomicity for data integrity. Atomicity in a database prevents completion of a transaction unless all the operations associated with a transaction are successfully completed. In the case of an ATM, for instance, the credit and debit side of your bank record have to be updated for a transaction to be complete. If either of those operations fails, the system is designed to truncate the transaction.
What is OLAP?
OLAP, or Online Analytical Processing works with aggregated data to fetch insights. It fetches data for analysis from OLTP systems and other databases. Compared to an OLTP system, an OLAP system runs complex queries on large datasets for business intelligence.
The focus in OLAP systems is on fast query performance. Techniques such as multidimensional indexing and caching are used to enable fast analysis of aggregated data. However, query performance is still slower compared to an OLTP system, since complex queries are run on large datasets.
Different Kinds of OLAP Systems
OLAP systems can, broadly, be categorized into the following 3 types:
- Multidimensional OLAP (MOLAP) - This is the standard OLAP system that queries data stored in multidimensional arrays. Multidimensional arrays pre-aggregate data into all possible combinations. For example, sales might be aggregated by product, time, and store location. Since all possible combinations are pre-computed, MOLAPs enable fast query response times. A MOLAP is also called an OLAP Cube.
Related reading: The Ultimate Guide to Data Warehouse Design
- Relational OLAP (ROLAP) - Contrary to a MOLAP that processes data stored in multidimensional arrays, a ROLAP queries data stored in a relational database. Multidimensional arrays are, instead, created on the fly, based on the queries supplied. Since combinations of data are created on the fly, query response time in ROLAPs is longer, compared to MOLAPs. However, ROLAPs can store more data and support larger user groups.
- Hybrid OLAP (HOLAP) - As the name suggests, this kind of system is a combination of a MOLAP and a ROLAP. Data is stored in, both, multidimensional databases and relational databases. Either of the two kinds of databases is accessed depending on the query.
The Trend Away From OLAP Cubes
Multidimensional cubes have been central to OLAP systems for a very long time. However, the rise of massively parallel processing (MPP) columnar databases such as Google's BigQuery are eliminating the need for OLAP cubes. These databases store data in columns instead of rows, which fundamentally shifts how data is aggregated. For example, in a typical row-based database, each row of sales transactions will have fields such as product name, date, and price. This substantially simplifies data aggregation, eliminating the explicit need to design cubes for data analysis. MPP databases also distribute a query across hundreds of machines for parallel processing, resulting in incredibly fast query response times.
Related Reading: What are Columnar Databases?
OLTP vs OLAP: A Features Comparison
The two kinds of data systems work in tandem with each other. Here is a quick glance at the key characteristics of the two systems, which highlight the different end-goals.
| OLTP | OLAP | |
| Type of Data | Handles operational data that is updated frequently. | Handles aggregated historical data. |
| Type of Query | Involves simple queries. | Involves complex queries. |
| Size | Typically small in size, from a few 100 MB to 10 GB. | Large in size, typically starting from a terabyte of data to 100 petabytes. |
| Response Time | Response time is in milliseconds. | Response time can vary from a few seconds to hours, depending on the volume of data to be analyzed. |
| Goal | The end-goal is to record everyday transactions. | The end-goal is to analyze captured data for business intelligence. |
| Source of Data | It is fed by everyday operations, such as completed sales, and products added. | It is fed by OLTP and other databases that a business maintains. |
| Type of Operations | Handles both read and write operations. | Typically only handles read operations. |
| Normalization | Uses normalization to reduce data redundancy. | Does not use normalization to enable multidimensional data analysis. |
OLTP vs OLAP: The Role of ETL
Fetching insights from data collected in an OLTP database can be complicated. Usually, for business intelligence such as trends and forecasting, data is needed from several different OLTP databases. Data in different databases might also be in different formats. In order to make this data available for analysis, it needs to undergo a process called ETL.
ETL stands for extract, transform, load. Put simply, raw data is extracted from different sources. This data is then cleaned, organized, and converted into a common format. The cleaned data is then loaded into a destination where analytical tools can be applied to it for business intelligence. In our case, the destination is an OLAP data warehouse. ETL is the preferred method for extracting data from OLTP systems for analysis.
Related Reading: ETL vs ELT
ETL Tools and Data Pipelines
Modern enterprises fetch data from a wide variety of sources, including real-time sources such as sensors and streaming. As data has grown in volume and variety, the task of building and maintaining an ETL data pipeline has become more complex. Fortunately, ETL tools can automate the process, eliminating the need to build and maintain a data pipeline in-house.
Integrate.io lets you build ETL data pipelines within minutes. With our scalable platform, you can integrate data from a really wide range of data repositories and SaaS applications. You can run complex data transformation tasks and start fetching insights quickly. Leave the maintenance and the grunt work to us. Schedule a call to start your free trial of Integrate.io and see how it can solve your data integration problems.




