


- What Is a Data Pipeline?`
- Trend 1: The Rise of Real-Time Data Pipelines
- Trend 2: A Growing Importance of Data Quality and Data Governance
- Trend 3: The Impact of Machine Learning and AI on Data Pipeline Design
- Trend 4: Growing Adoption of Cloud-Native Data Pipeline Solutions
- Trend 5: A Rise in Citizen Integrators
- Trend 6: Embracing Data as a Product
- Trend 7: The Expanding Role of Automation in Data Pipelines
- Data Pipeline Examples
- Final Thoughts
The global data integration market size grew from $12.03 billion in 2022 to $13.36 billion in 2023, making it evident that organizations are prioritizing efficient data integrations and emphasizing effective data pipeline management. Data pipelines play a pivotal role in driving business success by transforming raw datasets into valuable insights that fuel informed decision-making processes.
The five key takeaways are:
- Staying adaptable to emerging data pipeline trends is vital for businesses to leverage innovative technologies and remain competitive.
- Embracing automation in data pipelines enhances efficiency, facilitates swift issue detection, and optimizes resource management.
- Promoting collaboration and communication within organizations lays the groundwork for successfully implementing new trends and streamlining complex data processes.
- A strong focus on data governance ensures regulatory compliance while maintaining consistency across the organization's data assets.
- Empowering non-technical users to build data pipelines through user-friendly integration tools helps democratize access to data, strengthening cross-functional collaboration and decision-making in organizations.
In this post, we will highlight the most prominent trends influencing modern data pipelines while providing actionable tips to help you embrace these advancements and maximize your organization's potential through effective data management practices.
What Is a Data Pipeline?
A data pipeline is a systematic process that orchestrates the movement, transformation, and loading of data from one or multiple sources into an organized repository like a data warehouse or a data lake.
Data pipelines have evolved significantly with modern technologies like real-time processing frameworks, cloud-native solutions, machine learning integrations, and automation tools. These innovations enable businesses to handle high volumes of structured and unstructured information from an ever-growing range of data sources quickly and efficiently.
Moreover, efficient data pipelines are vital in powering applications like business intelligence (BI), machine learning models, customer experience analysis, and marketing campaign optimization – influencing every aspect of an organization's success.
Trend 1: The Rise of Real-Time Data Pipelines
In today’s data-driven world, the demand for instant decision-making is skyrocketing. Real-time data pipelines allow organizations to process and analyze high volumes of data as it is generated, leaving behind the traditional batch processing techniques that often cause delays.
By enabling real-time analytics, businesses benefit from improved operational efficiency, better customer experience, and faster decision-making.
Real-time data pipelines work by simultaneously ingesting a steady stream of information from multiple data sources. That information is then processed and transformed into a consistent format for analysis. Real-time data pipelines require careful planning and proper data hygiene to ensure that only quality data gets processed.
Here are four tips to prepare for the rise of real-time data pipelines:
- Evaluate your infrastructure: Determine whether your current system can manage a significant amount of data flowing continuously in real-time. If not, consider adopting a comprehensive cloud-based data integration solution that can scale alongside your data needs.
- Rethink your ETL processes: Consider transforming the usual ETL methods into parallel or stream-processing workflows to help maintain access to accurate and real-time data.
- Continuously monitor workflows: Set up efficient monitoring systems to easily detect potential issues and ensure data quality throughout your pipeline.
- Focus on data quality: Utilize metadata to standardize information across all data sources, ensuring consistency and allowing for easier integration and analysis of the data throughout your pipeline.
As the rise of real-time data pipelines manifests into more sophisticated technologies backed by impressive use cases, harnessing this trend will prove advantageous.
Trend 2: A Growing Importance of Data Quality and Data Governance
As data pipeline architectures become more sophisticated, the quality of data is more important than ever. Poorly managed or inaccurate information can lead to unpredictable outcomes with machine learning models or AI solutions, rendering them ineffective.
According to a study from Gartner, poor data quality costs businesses an average of $15 million each year and lead to undermined digital initiatives, weakened competitive standings, and customer distrust.
Data governance ensures that standardized practices are implemented across an organization to maintain accuracy, consistency, and relevancy in the collected data.
A well-defined governance framework promotes collaboration between business intelligence teams and effectively addresses compliance, privacy, and risk management concerns.
Here are five tips to prepare for the growing importance of data quality and data governance:
- Establish clear roles and responsibilities: Create a dedicated team responsible for upholding data management policies and coordinating IT and business units. This team will foster seamless communication among stakeholders while advocating for improved infrastructure when necessary.
- Create a data catalog: Develop a comprehensive inventory of existing datasets, including metadata about each source, to help streamline access to accurate information according to specific use cases or regulatory requirements.
- Implement continuous monitoring processes: Schedule regular data monitoring tasks to identify inconsistencies within a dataset before downstream issues arise proactively.
- Automate workflows where applicable: Embrace automated solutions like data integration tools or AI-driven algorithms to detect anomalies or errors in large datasets regularly without placing excessive workload burdens on human analysts.
- Encourage cross-domain collaboration: Encourage departments to share their domain-specific knowledge to improve data quality.
By prioritizing high-quality information and adhering to comprehensive governance frameworks, businesses can ensure the reliability of their data, enabling AI technologies to make more accurate decisions.
Trend 3: The Impact of Machine Learning and AI on Data Pipeline Design
Machine learning and artificial intelligence (AI) have revolutionized the complex processes involved in data pipeline design. Some of their benefits include automating mundane tasks like cleaning and transforming data to dynamically identify errors like duplicates or missing values.
By integrating AI into the data pipeline architecture, organizations can facilitate more informed decision-making while optimizing the customer experience. For instance, machine learning models swiftly analyze large volumes of customer data to generate actionable insights regarding sales trends or individual preferences, leading to improved retention rates.
Here are four tips to prepare for integrating machine learning and AI into your workflows:
- Familiarize your team with AI tools: Provide training sessions covering the basics of machine learning algorithms and AI-powered ETL frameworks to expose your workforce to the upcoming advanced technologies.
- Select appropriate ML/AI platforms: Review different cloud-based providers like Amazon AWS, Microsoft Azure, and Google Cloud Platform that offer Machine Learning-as-a-Service environments tailored to suit varied pipeline requirements based on your industry or specific objectives.
- Design your data architecture with flexibility in mind: Ensure that your existing pipelines are adaptable enough to accommodate advancements in machine learning techniques while considering compatibility across various platforms.
- Establish a monitoring framework: Develop a strategy to identify inaccuracies caused by biases in algorithms to ensure data quality through the machine learning models.
Machine learning and artificial intelligence continue to shape pipeline operations, so stakeholders must adapt their strategies accordingly to benefit from these emerging innovations.
Trend 4: Growing Adoption of Cloud-Native Data Pipeline Solutions
There is a significant shift toward the adoption of cloud-native data pipeline tools, which enable streamlined end-to-end data integration processes via advanced ETL (Extract, Transform, Load) processes.
Compared to traditional on-premises solutions, these cloud-based platforms offer increased scalability, reduced operational costs, enhanced security measures, and seamless data management.
Cloud-native data pipeline tools automate various tasks associated with data collection, consolidation, transformation, and loading into target systems such as data warehouses and lakes. It is due to their fast processing speeds and ease of use provisions that make it easy for even non-technical users to set up efficient workflows quickly.
Here are four tips to prepare for the adoption of cloud-native data pipeline tools:
- Assess your organization's pipeline infrastructure: Analyze whether your current solution meets scalability demands and maintains adequate performance levels when handling large datasets. Evaluate cloud provider integration options to determine compatibility with future migration initiatives.
- Develop an organized migration plan: Outline clear objectives detailing the advantages of switching from on-premises systems to cloud-native platforms while factoring in any required enhancements during transition phases.
- Select the right provider: Explore different data integration platforms that cater to your organization's specific goals while considering features such as ease of use, pre-built integrations, and customization options. Research customer reviews and prioritize vendors with transparent pricing models.
- Train your workforce in new technologies: Ensure appropriate training sessions cover essential aspects of working with these newly adopted platforms. Opt for a tool with responsive customer support options if users need technical assistance.
Cloud-native data pipelines enable companies to unlock numerous opportunities that would otherwise be too costly and labor-intensive.
Trend 5: A Rise in Citizen Integrators
As cloud-based data integration tools become more user-friendly, they enable non-technical users, called citizen integrators, to work proficiently with data pipeline tools, even if they are not data scientists or IT staff. As a result, business units can execute data projects more efficiently without relying on IT.
Easy-to-use data pipeline tools have empowered those with limited technical knowledge to create and manage their own data pipelines.
Here are four tips to empower citizen integrators in your organization:
- Identify potential citizen integrators: Select individuals interested in learning new technologies or possessing domain-specific knowledge, as they are the ideal candidates for handling advanced pipeline frameworks.
- Adopt user-friendly solutions: Look into streamlined data integration platforms that offer pre-built integrations, which helps eliminate bottlenecks during implementations requiring connecting various systems.
- Foster a collaborative environment: Encourage open communication channels between dedicated DataOps teams and non-technical users to share ideas and strengthen efforts toward achieving your organization's business intelligence goals.
- Incorporate mentorship programs: Pair citizen integrators with experienced data engineers to facilitate knowledge transfer of modern data pipeline practices and encourage hands-on learning experiences.
By embracing the move towards citizen integrators, businesses reduce bottlenecks, alleviate the burden on IT staff, and empower domain experts to work directly with data, leading to better decision-making.
Trend 6: Embracing Data as a Product
Modern data architectural approaches, such as data mesh, have transformed how data is managed, emphasizing its role as an independent, valuable asset. These approaches present data ownership in a decentralized manner, where business units take responsibility for the information they create.
Treating data as a product alleviates bottlenecks caused by waiting for technical resources and expedites actionable insights, empowering organizations to optimize decision-making with greater efficiency.
The fundamental principles of data mesh are:
- Decentralized data ownership: Business units handle their own data, ensuring up-to-date accuracy and reliability.
- Data as a product: Viewing data as an asset encourages quality, discoverability, and usability.
- Self-serve data infrastructure: Standardized tools and platforms empower teams to access and analyze datasets independently of central IT departments.
- Domain-oriented architecture: Data product teams align with business units to ensure they have the necessary expertise and resources to manage their data effectively.
Here are four tips to prepare for embracing data as a product within your organization:
- Embrace a decentralized approach: Encourage your organization to adopt a mindset that views each dataset as a product. This perspective will support organizational change and promote more efficient data-handling processes.
- Implement easy-to-use self-service tools: Invest in platforms that allow non-technical users to effortlessly create, analyze, and manipulate data pipelines without relying on IT or other departments.
- Train employees on domain-specific factors: Empower stakeholders by providing them with the knowledge to manage domain-specific nuances effectively, such as handling data related to unique industry regulations.
- Promote strong data governance practices: Ensure well-defined policies, guidelines, and standards are in place to safeguard against shadow IT and maintain consistency across business units.
By treating data as a product, organizations can optimize how they manage and utilize datasets to eliminate silos and empower domain-specific business units to make better data-driven decisions.
Trend 7: The Expanding Role of Automation in Data Pipelines
Automation has emerged as a driving force for data pipelines, significantly improving data efficiency and accuracy. Businesses streamline their data management efforts by automating repetitive tasks and reducing the opportunity for human errors, making informed decisions quicker and more effectively.
Automation tools streamline critical data management tasks like coding, testing, and monitoring data pipelines. Automating these tasks allows organizations to quickly identify anomalies, mitigate potential issues, and allocate resources more strategically by focusing on higher-priority tasks.
Here are four tips to prepare for implementing automation within your organization
- Assess your current data processes: Identify areas within your existing data management workflows, like redundant or time-consuming tasks, that could benefit from automation.
- Develop a strategy to implement automation: Focus on aligning your automation initiatives with your organization's business goals, ensuring that introducing new technologies and processes contributes to overall success.
- Consider automation technologies based on these factors: Compatibility with your current infrastructure, scalability for future growth, ease of use, transparent pricing, and dependable support options.
- Follow best practices to address common pitfalls during automation integrations: Select tools that align with company goals, implement effective change management, provide sufficient resources for implementation, and maintain a clear strategy and comprehensive planning.
By adopting and integrating automation into existing data pipelines, organizations establish a robust framework that enables actionable insights and effective decision-making while proactively adapting to evolving business objectives.
Data Pipeline Examples
Exploring some practical examples of data pipelines to understand their real-world applications and uses is helpful. This section highlights a few companies that demonstrate how they effectively transform raw data into valuable insights.
Netflix
Netflix's data infrastructure is incredibly advanced, handling more than 550 billion daily events, which is about 1.3 petabytes of data. The streaming giant's structure comprises smaller systems for data ingestion, analytics, and predictive modeling. Netflix mainly uses Apache Kafka for real-time events and data processing. Kafka sends data to AWS's S3 and EMR and other services like Redshift, Hive, Snowflake, and RDS for long-term storage needs.
To bring all these resources together as a "single" warehouse, Netflix developed Metacat. This technology connects various data sources (like RDS, Redshift, Hive, Snowflake, and Druid) with different computing engines (such as Spark, Hive, Presto, and Pig). In addition to Metacat, connections are made to secondary Kafka subsystems and tools like Elasticsearch – all while maintaining separate operational metric flows using their telemetry system called Atlas.
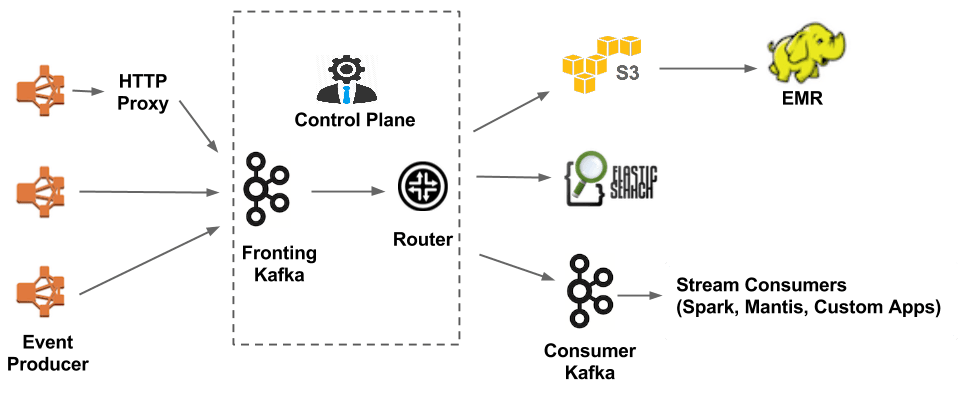
Netflix's interconnected infrastructure demonstrates the power of data pipelines in managing large-scale, complex data ecosystems efficiently.
Gusto
Gusto, a cloud-based payroll and benefits platform established in 2011, recognized the need for a data-informed culture as the company grew to serve around 60 thousand customers. Initially, their engineering team and product managers ran ad hoc SQL scripts on production databases. However, Gusto decided first to build a robust data infrastructure to support analytics and predictive modeling.
Their solution involved consolidating all major data sources into a single warehouse using AWS Redshift and S3 as the data lake. Amazon's Database Migration Service facilitated data transfer from production app databases to Redshift.
Looker serves as a BI front-end tool for company-wide access, exploration, and dashboard creation, while Aleph offers web-based SQL query writing capabilities. Snowplow is employed for event tracking and monitoring, integrating seamlessly with Redshift. Airflow orchestrates tasks throughout the pipeline.
By developing this pipeline, Gusto enhanced data access and manipulation across departments. Analysts can now create their own datasets within an Airflow task before exposing them in Looker for dashboard creation or further analysis.
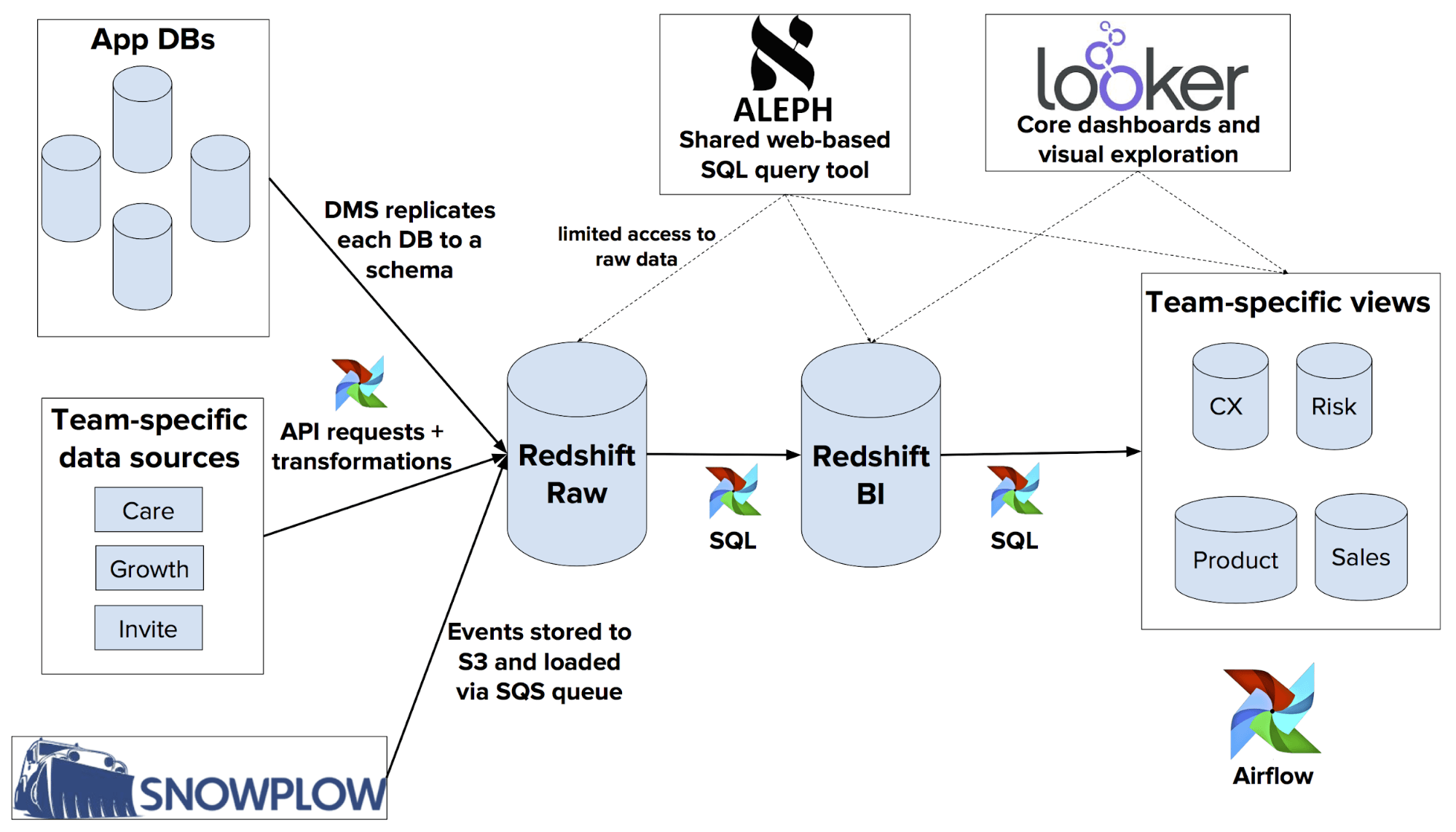
Gusto's thoughtfully designed data infrastructure illustrates how empowering citizen integrators and streamlining access to data can foster a collaborative, data-driven culture within organizations.
Final Thoughts
Data pipelines will continue to evolve, and by embracing these cutting-edge trends, you will be equipped with the tools and strategies to achieve maximum value from your data assets in the future.
Here is a quick recap of the 7 data pipeline trends to watch in 2023:
- Trend 1: The Rise of Real-Time Data Pipelines: Real-time data pipelines enable faster decision-making and improved operational efficiency.
- Trend 2: A Growing Importance of Data Quality and Data Governance: Data quality and governance are crucial for reliable AI-driven insights and business outcomes.
- Trend 3: The Impact of Machine Learning and AI on Data Pipeline Design: Machine learning and AI integration streamline data pipeline design, enhancing analytics capabilities.
- Trend 4: Growing Adoption of Cloud-Native Data Pipeline Solutions: Cloud-native data pipeline solutions offer scalability, reduced costs, and seamless data management.
- Trend 5: A Rise in Citizen Integrators: Citizen integrators empower non-technical users to manage data pipelines efficiently.
- Trend 6: Embracing Data as a Product: Treating data as a product optimizes its management, eliminates silos, and improves decision-making.
- Trend 7: The Expanding Role of Automation in Data Pipelines: Automation in data pipelines enhances efficiency, accuracy, and resource allocation.
By embracing these trends, businesses can unlock the full potential of their data assets to drive success in today's competitive landscape.
How Integrate.io Can Help
Integrate.io, a powerful data integration platform, can play a pivotal role in helping businesses adapt to the latest trends impacting data pipelines. With its user-friendly interface and robust pre-built integrations, Integrate.io helps organizations effortlessly harness the power of real-time data processing, automation, and cloud-based solutions.
By democratizing access to advanced data pipeline technologies and streamlining workflows for citizen integrators and technical users alike, Integrate.io empowers organizations with more efficient operations and valuable insights. Try Integrate.io today or schedule a call to witness first-hand how your organization can benefit from an all-in-one solution for modern data pipeline management.




