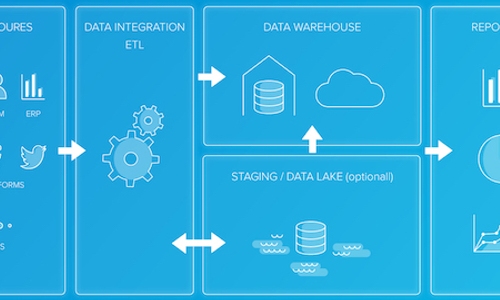
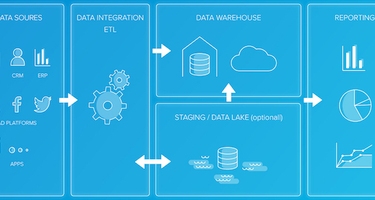

These days, companies have access to more data sources and formats than ever before: databases, websites, SaaS (software as a service) applications, and analytics tools, to name a few. Unfortunately, the ways businesses often store this data make it challenging to extract the valuable insights hidden within — especially when you need it for smarter data-driven business decision-making.
Standard reporting solutions such as Google Analytics and Mixpanel can help, but there comes a time when your data analysis needs outgrow capacity. At this point, you might consider building a custom business intelligence (BI) solution, which will have the data integration layer as its foundation.
First emerging in the 1970s, ETL remains the most widely used method of enterprise data integration. But what is ETL exactly, and how does ETL work? In this article, we drill down to what it is and how your organization can benefit from it.
What is ETL?
ETL stands for Extract, Transform and Load, which are the three steps of the ETL process. ETL collects and processes data from various sources into a single data store (e.g. a data warehouse or data lake), making it much easier to analyze.
In this section, we'll look at each piece of the extract, transform and load process more closely.
Extract
Extracting data is the act of pulling data from one or more data sources. During the extraction phase of ETL, you may handle a variety of sources with data, such as:
- Relational and non-relational databases
- Flat files (e.g. XML, JSON, CSV, Microsoft Excel spreadsheets, etc.)
- SaaS applications, such as CRM (customer relationship management) and ERP (enterprise resource planning) systems
- APIs (application programming interfaces)
- Websites
- Analytics and monitoring tools
- System logs and metadata
We divide ETL into two categories: batch ETL and real-time ETL (a.k.a. streaming ETL). Batch ETL extracts data only at specified time intervals. With streaming ETL, data goes through the ETL pipeline as soon as it is available for extraction.
Transform
It's rarely the case that your extracted data is already in the exact format that you need it to be. For example, you may want to:
- Rearrange unstructured data into a structured format.
- Limit the data you've extracted to just a few fields.
- Sort the data so that all the columns are in a certain order.
- Join multiple tables together.
- Clean the data to eliminate duplicate and out-of-date records.
All these changes and more take place during the transformation phase of ETL. There are many types of data transformations that you can execute, from data cleansing and aggregation to filtering and validation.
Load
Finally, once the process has transformed, sorted, cleaned, validated, and prepared the data, you need to load it into data storage somewhere. The most common target database is a data warehouse, a centralized repository designed to work with BI and analytics systems.
Google BigQuery and Amazon Redshift are just two of the most popular cloud data warehousing solutions, although you can also host your data warehouse on-premises. Another common target system is the data lake, a repository used to store "unrefined" data that you have not yet cleaned, structured, and transformed.
Related Reading: ETL vs ELT
Implementing ETL in a Data Warehouse
When an ETL process is used to move data into a data warehouse, a separate layer represents each phase:
Mirror/Raw layer: This layer is a copy of the source files or tables, with no logic or enrichment. The process copies and adds source data to the target mirror tables, which then hold historical raw data that is ready to be transformed.
Staging layer: Once the raw data from the mirror tables transform, all transformations wind up in staging tables. These tables hold the final form of the data for the incremental part of the ETL cycle in progress.
Schema layer: These are the destination tables, which contain all the data in its final form after cleansing, enrichment, and transformation.
Aggregating layer: In some cases, it's beneficial to aggregate data to a daily or store level from the full dataset. This can improve report performance, enable the addition of business logic to calculate measures, and make it easier for report developers to understand the data.
Why Do You Need ETL?
ETL saves you significant time on data extraction and preparation — time that you can better spend on evaluating your business. Practicing ETL is also part of a healthy data management workflow, ensuring high data quality, availability, and reliability.
Each of the three major components in the ETL saves time and development effort by running just once in a dedicated data flow:
Extract: Recall the saying "a chain is only as strong as its weakest link." In ETL, the first link determines the strength of the chain. The extract stage determines which data sources to use, the refresh rate (velocity) of each source, and the priorities (extract order) between them — all of which heavily impact your time to insight.
Transform: After extraction, the transformation process brings clarity and order to the initial data swamp. Dates and times combine into a single format and strings parse down into their true underlying meanings. Location data convert to coordinates, zip codes, or cities/countries. The transform step also sums up, rounds, and averages measures, and it deletes useless data and errors or discards them for later inspection. It can also mask personally identifiable information (PII) to comply with GDPR, CCPA, and other privacy requirements.
Load: In the last phase, much as in the first, ETL determines targets and refresh rates. The load phase also determines whether loading will happen incrementally, or if it will require "upsert" (updating existing data and inserting new data) for the new batches of data.
How Does Modern ETL Help Your Business?
"Big data" truly lives up to its name — not only in size and quantity but also in impact, possible interpretations, and use cases. Each department in a modern organization requires unique insights from large volumes of data. For example:
- Sales teams require accurate, high-quality information about prospective customers.
- Marketing teams need to assess the conversion rates of campaigns and develop future strategies.
- Customer success teams want to drill down in order to address problems and improve customer service.
By extracting and preparing the data your employees need, ETL can help solve these issues and others. ETL makes it dramatically simpler, faster, and more efficient to run reporting and analytics workflows on your enterprise data.
In satisfying these diverse demands, ETL also helps create an environment that sustains data governance and data democracy. Data governance is the overall management of your enterprise data, including its availability, usability, integrity, and security. With data democracy, everyone in your company who needs sophisticated data analytics has access to it. This reduces steep learning curves, helps people ask the right questions, and helps clarify the answers they get.
How ETL Works
In this section, we'll dive a little deeper, taking an in-depth look at each of the three steps in the ETL process.
You can use scripts to implement ETL (i.e. custom DIY code) or you can use a dedicated ETL tool. An ETL system performs a number of important functions, including:
Parsing/Cleansing: Data generated by applications may be in various formats like JSON, XML, or CSV. The parsing stage maps data into a table format with headers, columns, and rows, and then extracts specified fields.
Data enrichment: Preparing data for analytics usually requires certain data enrichment steps, including injecting expert knowledge, resolving discrepancies, and correcting bugs.
Setting velocity: "Velocity" refers to the frequency of data loading, i.e. inserting new data and updating existing data.
Data validation: In some cases, data is empty, corrupted, or missing crucial elements. During data validation, ETL finds these occurrences and determines whether to stop the entire process, skip the data or set the data aside for human inspection.
Data Extraction
Data extraction involves the following four steps:
Identify the data to extract: The first step of data extraction is to identify the data sources you want to incorporate into your data warehouse. These sources might be from relational SQL databases like MySQL or non-relational NoSQL databases like MongoDB or Cassandra. The information could also be from a SaaS platform like Salesforce or other applications. After identifying the data sources, you need to determine the specific data fields you want to extract.
Estimate how large the data extraction is: The size of the data extraction matters. Are you extracting 50 megabytes, 50 gigabytes, or 50 petabytes of data? A larger quantity of data will require a different ETL strategy. For example, you can make a larger dataset more manageable by aggregating it to month-level rather than day-level, which reduces the size of the extraction. Alternatively, you can upgrade your hardware to handle the larger dataset.
Choose the extraction method: Since data warehouses need to update continually for the most accurate reports, data extraction is an ongoing process that may need to happen on a minute-by-minute basis. There are three principal methods for extracting information:
• Update notifications: The preferred method of extraction involves update notifications. The source system will send a notification when one of its records has changed, and then the data warehouse updates with only the new information.
• Incremental extraction: The second method, which you can use when update notifications aren’t possible, is incremental extraction. This involves identifying which records have changed and performing extraction of only those records. A potential setback is that incremental extraction cannot always identify deleted records.
• Full extraction: When the first two methods won't work, a complete update of all the data through full extraction is necessary. Keep in mind that this method is likely only feasible for smaller data sets.
Assess your SaaS platforms: Businesses formerly relied on in-house applications for accounting and other record-keeping. These applications used OLTP transactional databases that they maintained on an on-site server. Today, more businesses use SaaS platforms like Google Analytics, HubSpot, and Salesforce. To pull data from one of these, you’ll need a solution that integrates with the unique API of the platform. Integrate.io is one such solution.
Cloud-based ETL solutions like Integrate.io extract data from popular SaaS APIs by:
• Engineering out-of-the-box API integrations for the most popular SaaS applications. Integrate.io offers over 100 out-of-the-box AI integrations.
• Navigating complex REST APIs, even converting SOAP to REST automatically.
• Creating strategies to deal with custom resources and fields — and the many built-in resource endpoints — found in different SaaS APIs.
• Providing constant updates and fixes for data connections that fail. For example, Salesforce might update its API without notifying users, resulting in a scramble to find a solution. ETL platforms like Integrate.io develop relationships with SaaS developers and receive advanced notice of these kinds of updates before they go live, which prevents unwanted surprises.
Data Transformation
In traditional ETL strategies, data transformation that occurs in a staging area (after extraction) is “multistage data transformation.” In ELT, data transformation that happens after loading data into the data warehouse is “in-warehouse data transformation.”
Whether you choose ETL or ELT, you may need to perform some of the following data transformations:
Deduplication (normalizing): Identifies and removes duplicate information.
Key restructuring: Draws key connections from one table to another.
Cleansing: Involves deleting old, incomplete, and duplicate data to maximize data accuracy — perhaps through parsing to remove syntax errors, typos, and fragments of records.
Format revision: Converts formats in different datasets — like date/time, male/female, and units of measurement — into one consistent format.
Derivation: Creates transformation rules that apply to the data. For example, maybe you need to subtract certain costs or tax liabilities from business revenue figures before analyzing them.
Aggregation: Gathers and searches data so you can present it in a summarized report format.
Integration: Reconciles diverse names/values that apply to the same data elements across the data warehouse so that each element has a standard name and definition.
Filtering: Selects specific columns, rows, and fields within a dataset.
Splitting: Splits one column into more than one column.
Joining: Links data from two or more sources, such as adding spend information across multiple SaaS platforms.
Summarization: Creates different business metrics by calculating value totals. For example, you might add up all the sales made by a specific salesperson to create total sales metrics for specific periods.
Validation: Sets up automated rules to follow in different circumstances. For instance, if the first five fields in a row are NULL, then you can flag the row for investigation or prevent it from being processed with the rest of the information.
Data Loading
Data loading is the process of loading the extracted information into your target data repository. Loading is an ongoing process that could happen through "full loading" (the first time you load data into the warehouse) or "incremental loading" (as you update the data warehouse with new information). Because incremental loads are the most complex, we'll focus on them in this section.
Types of Incremental Loads:
Incremental loads extract and load information that has appeared since the last incremental load. This can happen in two ways:
Batch incremental loads: The data warehouse ingests information in packets or batches. If it's a large batch, it's best to carry out a batch load during off-peak hours — on a daily, weekly, or monthly basis — to prevent system slowdowns. However, modern data warehouses can also ingest small batches of information on a minute-by-minute basis with an ETL platform like Integrate.io. This allows them to achieve an approximation of real-time updates for the end-user.
Streaming incremental loads: The data warehouse ingests new data as it appears in real-time. This method is particularly valuable when the end-user requires real-time updates (e.g. for up-to-the-minute decision-making). That said, streaming incremental loads are only possible when the updates involve a very small amount of data. In most cases, minute-by-minute batch updates offer a more robust solution than real-time streaming.
Incremental Loading Challenges:
Incremental loads can disrupt system performance and cause a host of problems, including:
Data structure changes: Data formats in your data sources or data warehouse may need to evolve according to the needs of your information system. However, changing one part of the system could lead to incompatibilities that interfere with the loading process. To prevent problems relating to inconsistent, corrupt, or incongruent data, it’s important to zoom out and review how slight changes affect the total ecosystem before making the appropriate adjustments.
Processing data in the wrong order: Data pipelines can follow complex trajectories that result in your data warehouse processing, updating, or deleting information in the wrong order. That can lead to corrupt or inaccurate information. For this reason, it’s vital to monitor and audit the ordering of data processing.
Failure to detect problems: Quick detection of any problems with your ETL workflow is crucial: e.g. when an API goes down, when your API access credentials are out-of-date, when system slowdowns interrupt dataflow from an API or when the target data warehouse is down. The sooner you detect the problem, the faster you can fix it, and the easier it is to correct the inaccurate/corrupt data that results from it.





