
- はじめに
- データ整理を理解する
- データ整理の重要性
- データラングリングとETLの比較
- 2025年におけるデータラングリングのテクニック
- 2025年のデータラングリングを形成するトレンド
- データラングリングの課題と落とし穴
- まとめ
複雑なデータの世界を進む際、企業はよく生の非構造化情報に手こずることがありますが、そこで、その「混沌」を「明瞭」に変える「データラングリング」が必要となります。ETL プロセスとシームレスに絡み合っているデータラングリングは、綿密にデータを洗練して準備することで、洞察に満ちた分析と意思決定のための準備が整っているだけでなく、それを確実に最適化します。
このプロセスのニュアンスと影響を理解するために、以下に挙げた主なインサイトを本記事で掘り下げてみましょう:
- データラングリングプロセスは、未加工の乱雑なデータを、クリーンで構造化された分析可能な情報に変換し、強固なデータ分析の基盤とするために極めて重要である。
- 自動化、AI 主導のツール、データ統合プロバイダー、データエンリッチメント、リアルタイム処理など、データラングリングの技術は進化している。
- データ整理における一般的な課題には、欠損データ、外れ値、データ品質、複雑なデータ構造の取り扱い、シームレスなデータ統合の確保などがある。
- オートメーションと AI は、データラングリング、プロセスの効率化、手作業の軽減、データ品質の向上において極めて重要なものとなりつつある。
- データ ラングリングは分析用のデータのクリーニングと準備に重点が置かれているが、ETL は大規模なデータの移動と統合のための構造化されたプロセスであり、どちらもデータの品質と使いやすさの確保に非常に重要である。
本記事で、より強固なデータ分析のためにデータを管理および活用するための、データ管理、ETL、強力なツールの重要性を探りましょう。
はじめに
データラングリング は、「データ マンジング」や「データ クリーニング」とも呼ばれる、生のデータセットの形を整えて精製し、分析に適した状態にする技術です。 これは、データ サイエンティストやアナリストが膨大なデータの中から隠された宝石を抽出できるようにする極めて重要なプロセスです。
新しいデータのインサイトが詰まった宝箱へのアクセスが許可され、そのそれぞれが全体的なデータ分析に役立つ可能性を秘めていることを想像してみてください。 データラングリングは、その貴重な生データを細心の注意を払って切り取って形を整え、磨き上げて、実用的なインサイトに変換できるようにするプロセスです。
データラングリングを理解する
「データラングリング」という言葉には、データの整理とクリーニングが含まれますが、それは単にデータセットを整理するだけではなく、検証、変換、統合などの包括的なプロセスであり、それによってデータがクリーンであるだけでなく、その後の分析に適したフォーマットと構造になっていることが保証されます。
データ分析においてデータ整理が重要なステップである理由
データラングリングは、強固なデータアナリティクスを構築する土台となり、インサイトが究極の目標であるデータ分析の広大なランドスケープにおいて、意味のある探索の舞台を整える、非常に重要な初期段階となります。
生データは、不純物の中に散らばった金粉だと考えてください。データ整理は、塵を不純物から丹念に分離して精製し、価値ある金の延べ棒に成形するような、その金を抽出するプロセスに似ています。未加工の金粉が宝石や取引に直接使用できないように、未加工のデータは、欠損値、外れ値、一貫性のないフォーマットなどの課題を抱えており、それが不正確な分析や信頼できないインサイトにつながる可能性があります。なのでデータラングリングを通して、データをクリーンであるだけでなく、確実に構造化されて、意味のある分析ができる状態であるようにします。
データをデータラングリングの厳しさにさらすことで、分析前にデータを可能な限りベストな状態にします。これは、生データを洗練された宝石に変え、データ主導のインサイトへの道を照らす準備を整えるプロセスなのです。
おすすめ記事(英語): 7 Best Data Analysis Tools(おすすめデータ分析ツール7選)
データラングリングの重要性
なぜデータ分析の世界ではデータ管理が不可欠なのでしょうか?その答えは、我々が遭遇するデータセットの複雑さと多様性にあります。知識の探求において、データサイエンティストやアナリストは、フォーマット、構造、品質が違う多様なデータソースからのデータに手こずり、そこで、データラングリングの出番となります。
データラングリングの中核となるのは、データの品質の保証や、外れ値、欠損値、不整合などの問題の特定および修正であり、生データを、構造化されたクリーンで一貫性のある形式に変換し、使用可能で信頼できるものにします。データラングリングがなければ、データ分析プロセスは、不安定な基礎の上に家を建てるようなもので、崩れやすく信頼性の低い結果をもたらしてしまいます。
2025 年に向けて
未来に目を向けると、2025年、データラングリングの世界はワクワクするような発展を遂げようとしています。増え続けるデータの流入に伴い、それがもたらす課題と機会は進化し続けるでしょう。そして、ML(機械学習)やアルゴリズムの進歩からビッグデータのパワーの活用まで、データラングリングはデータサイエンス分野におけるイノベーションの最前線であり続けるでしょう。
では、2025年のデータラングリングの展望を形作るテクニック、ツール、トレンドについて深く掘り下げてみましょう。AI(人工知能)の役割の探求から、ヘルスケアのような業界特有のニーズへの対応まで、データラングリングの謎を解き明かし、その真の可能性を活用するための知識を身につける旅に乗り出しましょう。
データラングリング と ETL
データラングリングは、主に生データのクリーニングと分析のための準備に焦点が当てられており、乱雑なデータや構造化されていないデータ、一貫性のないデータを、構造化されたフォーマットに変換します。また、多くの場合、分析フェーズに近い段階で行われ、その柔軟性と適応性を特徴とします。データサイエンティストやアナリストの特定のニーズを満たすためにデータを改良し、形を整える反復プロセスなのです。

一方、ETL(抽出、変換、格納)とは、様々なソースからデータを抽出し、(インフライトで)標準化されたフォーマットに変換し、ターゲットデータベースやデータウェアハウスに格納する包括的なデータ統合プロセスです。これは、まずデータを抽出し、それを目的のデータウェアハウスに格納し、そこで変換を行う ELT(抽出、格納、変換)とは対照的です。ETL はより構造化および自動化されたものであり、大規模なデータ移動と統合のためにデザインされており、さまざまなシステム間でデータを同期させる必要がある場合や、BI(ビジネスインテリジェンス)を目的とする場合によく使用されます。
データラングリング と ETL は、どちらもデータの品質と使いやすさの確保には非常に重要ですが、両者の役割は異なります。データラングリングは、生データのクリーニング、変換、リッチ化に重点を置き、多くの場合、探索的データ分析に備えますが、ETL は、その「変換」フェーズでデータラングリングを組み込むことができる手法です。ETL プロセスでは、データはソースから抽出されて変換され(データクレンジングやその他のラングリングタスクを含む)、ターゲットシステムに格納されます。データ ラングリングはより柔軟で順応性が高いですが、ETL は構造化されており、大規模なデータセットをデータベースやデータ ウェアハウスに統合するのに最適です。
データの正規化、ETL、データラングリングの違いを理解することは、データ専門家にとって非常に重要です。データの正規化は主に BI アプリケーションに使用され、それによってデータをレポートやモデルに最適な構造化されたフォームに形成します。そして、これは静止時(データベース内)と飛行中(データ転送中)の両方で行うことができます。
一方、ETL はアプリケーション間でのデータ転送のためにデザインされたプロセスであり、データのラングリングやクレンジング、または正規化に関しては、ETL の「変換」の段階では、データがあるアプリケーションから別のアプリケーションに転送される間にこのような機能を適用する方法として機能します。
そして、進化するデータ分析の状況を進んで行くデータ専門家にとって、データ ラングリングの熟練度、データ正規化の理解、ETL プロセスの専門知識は、非常に貴重な資産となることがあります。
さらに読む(英語):Data Wrangling vs. ETL: What’s the difference?( データラングリングと ETL:両者の違い)
他のデータプロセスとの統合
データラングリングは、データライフサイクルに欠かせないステップではありますが、単独では機能しません。データの収集から最終的な分析、可視化まで、以下のようなさまざまな段階を含む、より大きなデータパイプラインの極めて重要な構成要素なのです。
- ラングリングの前段階: データラングリングの前に、データ収集またはインジェストのフェーズがあり、IoT デバイス、ユーザーとのやり取り、サードパーティの API など、生のデータはデータレイクやデータベースに蓄積される。そのデータの品質と形式は様々で、ラングリングプロセスの舞台となる。
- ラングリング後 - データの可視化: データがクリーニングされて変換されると、パターン、トレンド、異常の特定のために可視化されることが多い。ちなみに、Tableau、Power BI、Matplotlib などのツールは、適切にラングリングされたデータに依存して意味のある視覚的表現を生成する。
- ML(機械学習)および AI:予測モデルを構築するデータサイエンティストにとって、データのラングリングはフィーチャーエンジニアリングとモデルトレーニングの前段階となる。クリーンで構造化されたデータで、ML のアルゴリズムの効果的なトレーニングができ、それがより正確な予測につながる。
- リアルタイム分析: ビジネスがリアルタイムの意思決定に向かうにつれ、集められたデータはリアルタイムの分析ツールに供給される。これにより、企業は新たなトレンドや問題に迅速に対応することができる。
データラングリングは、データを最大限に活かすのに非常に重要な作業であり、データセットを構造化して操作できるようになることで、ML、AI、リアルタイム分析など、さまざまな分野のインサイトを引き出すことができます。このようなデータの理解は、組織のタイムリーで正確な意思決定に不可欠です。
2025年のデータラングリング技術
データアナリティクスの未来に向けて、データラングリングの状況は急速に進化しており、2025年は、データラングリングは単に必要なステップというだけでなく、拡大し続けるデータの世界の要求に応えるために絶えず改良され続けるアートフォームとなっています。そこでこのセクションでは、2025年のデータラングリングを確定するテクニックを見てみましょう。
従来のデータラングリング手法の概要
従来、データ整理には労働集約的なプロセスが必要であり、データサイエンティストやアナリストは、腕まくりをしてスプレッドシートやスクリプト、手作業に没頭して、データのクリーニングや準備を行っていました。このようなやり方は効果的ではありますが、時間がかかることが多く拡張性に欠けるため、ビッグデータやリアルタイム分析には適していませんでした。
そこで、多くのデータラングラーの救世主として Python が登場し、pandas のような多機能なライブラリによって、データ操作はより効率的になりましたが、特に大規模なデータセットや複雑なデータ構造を扱う際には、課題が残りました。
効率的なデータラングリングのための新しいテクニック
2025年、データラングリングは効率性、スピード、適応性がすべてとなります。ここでは、データラングリングの未来を形作る新たなテクニックをいくつか見てみましょう:
オートメーションと AI
「オートメーション」は、最新のデータラングリングの流行語です。AI 主導のツールは、パターン、異常値、データ品質の問題をリアルタイムで特定して、データクリーニングに必要な手作業を大幅に削減することができ、機械学習アルゴリズムは、過去のパターンに基づいてデータ変換を提案することもできます。
データ統合プロバイダー
データ統合プロバイダーには、データ管理のためのエンドツーエンドのソリューションがあり、それでさまざまなソースからのシームレスなデータ統合ができるようになり、ETL (抽出、変換、格納) プロセスの処理をしたり、データ エンリッチメント機能が得られるようになります。そしてこのようなプラットフォームには、データアナリストがコーディングなしで複雑なデータ変換を実行できるようになる、ユーザーに優しいインターフェースがあります。
データの強化と再形成
データラングリングとは、単にデータをきれいにすることではなく、データを強化することです。ツールやテクニックは、データセットを外部のデータソースで補強し、それによってそのデータセットは追加的なコンテクストで強化されます。さらに、データ再形成の技術により、特定の分析ニーズに合わせてデータを速やかにピボットおよび再構築できるようになります。
リアルタイムのデータラングリング
リアルタイムの分析には、リアルタイムのデータラングリングが必要です。リアルタイムで到着するデータ ポイントの重要性が高まる中、データ ラングラーは、流入するデータを処理してクリーンアップできるツールに焦点を当てており、分析モデルに常に最新の高品質データが確実に供給されるようにしています。
リアルタイムのデータラングリングの課題
リアルタイム分析の台頭により、リアルタイムのデータ ラングリングの必要性が生じています。 そして、それには以下のような独特の課題が伴います:
- スピード:従来のデータラングリングプロセスでは、リアルタイムのニーズに対して十分なスピードが得られない可能性がある。ツールやテクニックは、アナリティクスプロセスに遅れを生じさせることなく、入力されたデータを確実にクリーニングし、変換するスピードで動作しないといけない。
- データの一貫性: データが絶え間なく流れ込んでくるため、一貫性の確保が課題となる。例えば、データソースがそのフォーマットを変更したり、新しいフィールドを導入したりした場合、ラングリングのプロセスはそれにその場で対応しないといけない。
- スケーラビリティ: リアルタイムのデータ量が増えるにつれて、ラングリングプロセスもそれに応じた拡張が必要であり、そのためには、パフォーマンスを低下させることなく大量のデータ流入を処理できる、強固なインフラとツールが求められる。
- エラー処理: リアルタイムのシナリオでは、エラーの余地はほとんどないが、ラングリングプロセス中に問題が発生した場合、下流のアナリティクスに支障が出ないよう、即座の対処が必要である。
- 継続的な反復: データラングリングが単発または定期的なタスクであるバッチ処理とは異なり、リアルタイムのラングリングでは、データパターンが進化するにつれて、継続的な反復と改良が求められる。
Python の 12のデータラングリング機能について、面白いビデオを見つけました。
データラングリングにおけるオートメーションの重要性
オートメーションは現代のデータ管理の要であり、さまざまな形式やさまざまなデータソース、大規模なデータセットが特徴のデータ環境では、手動によるデータのクリーニングと変換では追いつけません。
そこでデータラングリングプロセスを自動化することで、組織は次のことが実現します:
- 時間の節約:オートメーションにより、反復的なデータクリーニング作業に費やされる時間が短縮されるため、データ担当者は分析や意思決定に多くの時間を割くことができる。
- データ品質の向上: AI を活用したオートメーションにより、データ品質の問題をリアルタイムで特定および修正し、それによって、分析に使われるデータが最高品質であることが保証される。
- ユーザビリティの向上: 自動化されたツールは、ユーザーに優しいインターフェースを備えていることが多く、それによって、組織内の幅広いユーザーがデータ管理にアクセスできるようになる。
2025年におけるデータ分析の展望は、自動化、AI 主導の技術、データサイエンティストやアナリストが多様なデータセットをより効率的に扱えるようにする、ユーザーに優しいプラットフォームへのシフトによって特徴付けられます。そしてこのような進歩は、データ分析、特にビッグデータとリアルタイム分析の文脈における需要の増加への対応に非常に重要です。
2025年のデータラングリングを形作るトレンド
データラングリングにおける AI および ML
AI(人工知能)と ML(機械学習)は、データラングリングプロセスに欠かせないものとなっており、このようなテクノロジーは、以下のような、以前は想像もできなかったレベルのオートメーションとインテリジェンスをもたらします。
- AI によるデータクリーニング: AI 主導のアルゴリズムは、乱雑なデータを自動的に検出してクリーニングすることができ、パターン、異常値、不整合を識別することから、データクリーニングがより効率的で正確なプロセスになる。
- データ変換の自動化: MLモデルは、過去のパターンに基づいてデータ変換を推奨することから、分析のためにデータを構造化するプロセスが効率化される。これは手作業が減るだけでなく、データ変換の品質向上にもなる。
- 予測的データエンリッチメント: AI は欠損値を予測して外部ソースからデータを集めることで、データセットを強化することができる。これは、分析のためのデータのコンテクストが AI でわかることから、非構造化データを扱う場合に特に価値がある。
ビッグデータの課題と解決策
ビッグデータは、データラングリングに以下のような独特の課題と機会をもたらします:
- スケーラビリティ: データの急激な増加に伴い、データラングリングプロセスのスケーラビリティが最も重要になる。最新のツールやプラットフォームは、大規模なデータセットを効率的に処理できるようにデザインされており、データラングリングがボトルネックにならないことが保証されている。
- リアルタイムデータ: リアルタイム分析の必要性により、リアルタイムのデータ ラングリングが必要になり、タイムリーな意思決定に対応するために、リアルタイムで到着するデータポイントのその場でのクリーニング、検証、統合が必要になる。
- データの多様性: ビッグデータは多様であることが多く、さまざまなソースからさまざまな形式で提供される。データラングリングツールは、この多様性をシームレスに処理し、ソースや形式に関係なくデータを統合および変換できるように進化している。
データガバナンスとコンプライアンスの役割
データのプライバシーとコンプライアンスが最重要視される今日、データガバナンスはデータラングリングにおいて以下のような重要な役割を果たしています:
- データプライバシー: GDPR(EU一般データ保護規則)や CCPA(カリフォルニア州消費者プライバシー法)のような規制で、組織は最大限の注意を払ってデータを取り扱うことが求められ、データラングリングプロセスは、データのマスキング、匿名化、その他のプライバシー対策を取り入れ、コンプライアンスを確保しないといけない。
- データ監査とプロビナンス(データなどの出自や履歴): データガバナンスには、データの系統を追跡し、変換と統合ステップが全て監査可能であることを保証することが含まれ、この透明性は、データ品質とコンプライアンスの維持に非常に重要である。
- 連携とドキュメンテーション: 最新のデータラングリングツールは、連携とドキュメンテーションを重視している。データラングラーは自分たちのアクションに注釈を付けて文書化することができるため、規制要件に準拠していることを証明しやすくなる。
2025年のデータラングリングは、AI とML の導入によって顕著になり、プロセスの効率化だけでなく、データの品質も上がるでしょう。そして、ビッグデータがもたらす課題は、スケーラブルでリアルタイムなソリューションによって解決され、さらに、データ ガバナンスとコンプライアンスはデータ ラングリング プロセスにとって極めて重要なものになり、それによって、データは責任を持って規制に従ってきちんと取り扱われるようになります。
進化し続けるデータラングリングの状況を進んでいくにつれ、この分野がデータ分析の中心にあることが明らかになってきました。生データを実用的なインサイトに変換し、データサイエンティスト、アナリスト、組織が十分な情報に基づいた意思決定を行えるようにする橋渡し役ですね。次のセクションでは、データラングリングが意思決定とビジネス成果に与える実際的な影響に焦点を当てた、実際のケーススタディとサクセスストーリーを掘り下げていきましょう。
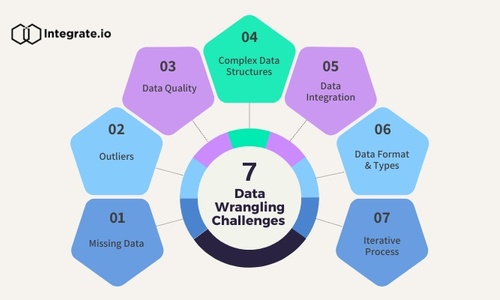
データラングリングの課題と落とし穴
データラングリングは非常に重要ですが、課題や潜在的な落とし穴がないわけではありません。ここでは、データラングリングプロセスで遭遇するよくある問題と、その課題を克服するための戦略を見てみましょう。
データラングリングでよくある問題
- 欠損データ: 欠損値のある不完全なデータセットは、重要な課題となることがあり、欠損値のインプットを行うか、不完全なレコードを除外するか、ギャップを埋める代替データソースを見つけるかを決定することが非常に重要である。
- 外れ値: 外れ値は分析結果を歪める可能性がある。外れ値が本物のデータポイントなのか、それともエラーなのかを識別することは非常に重要であり、外れ値の取り扱いには、変換や外れ値専用モデルの作成が必要になる場合がある。
- データの質:データ品質の確保は永遠の課題である。不正確なデータや一貫性のないデータは、誤った結論につながる可能性があり、定期的なデータ品質のチェックと検証手順は非常に重要である。
- 複雑なデータ構造: 入れ子形式や階層形式など、さまざまな構造のデータを扱うのは複雑な場合があり、データラングラーは、このような構造を使用可能な形に再構築する必要がある。
- データ統合: それぞれに独自のスキーマとフォーマットがある複数のソースからのデータ統合には、慎重なマッピングと整合が必要であり、不一致はデータの不整合につながる。
- データ形式とデータ型: CSV、JSON、XML などの多様なデータ形式や、テキスト、数値、カテゴリーなどのデータ型を扱うには、汎用性の高いツールやテクニックが求められる。
- 反復プロセス: データラングリングは、反復プロセスであることがよくあり、継続的な改良が求められる。変更の追跡しや再現性の確保することは、大変ではあるが不可欠なものである。
データラングリングの課題を克服する戦略
- データのプロファイリング:データを徹底的に理解することから始める。プロファイリングツールで、欠損値、外れ値、データ品質の問題を特定できるようになる。
- 可能な限り自動化する: データクリーニングのプロセスを迅速化し、手作業によるミスを減らすために、オートメーションと AI 主導のツールを導入する。
- データガバナンス: データ品質、リネージ、コンプライアンスの維持のために、明確なデータガバナンスを確立する。
- ドキュメンテーション: データラングリングプロセスの各ステップを文書化する。明確な文書化で、透明性、コラボレーション、コンプライアンスが実現する。
- 連携: データ専門家、ドメイン専門家、データ ラングラー間の連携を促進して、協働で課題に対処し、データの正確性を確保する。
- 定期的なアップデート: データ管理は1回限りの作業ではない。特にリアルタイムのデータソースについては、定期的な更新のためのプロセスを設定する。
今後の展望
データラングリングの未来は有望であり、常に進化しています。2025年以降、この分野を形成するトレンドと発展が以下のように予想されます:
- さらなるオートメーション: オートメーションは今後もデータ ラングリングにおいて極めて重要な役割を果たし、AI および ML アルゴリズムはデータの問題を特定して対処する上でさらに洗練される。
- データ サイエンス プラットフォームとの統合:データ ラングリングはデータ サイエンス プラットフォームとシームレスに統合され、それによって、データのプロフェッショナルは、統一された環境が得られる。
- 高まるデータ倫理の重視: データ・プライバシー規制が進化するにつれ、データ管理は倫理的配慮とコンプライアンス対策を基本的な側面として取り入れることになる。
- 専門スキルとしてのデータラングリング: データラングリングは、専門的なスキルセットとして登場し、専門のプロフェッショナルや認定資格を持つようになるであろう。
まとめ
結論として、データラングリングは効果的なデータ分析の要であり、生データを実用的なインサイトに変換し、データサイエンティストやアナリストが情報に基づいた意思決定を行えるようにしてくれます。データラングリングには課題がつきものですが、オートメーション、データガバナンス、コラボレーション、継続的な学習は、データラングリングの進化する状況を進んでいくのに重要な戦略となります。
将来を見据えても、データラングリングはビッグデータ、AI、データ倫理の需要に適応するダイナミックな分野であり続けるでしょう。それは無限の可能性を秘めた分野であり、それを習得できれば、データ主導型イノベーションの最前線に立つことになるでしょう。
Integrate.io でデータジャーニーを強化しよう
データ分析の領域において、データラングリングは生データと実用的なインサイトをつなぐ極めて重要な橋渡し役となりますが、その真の可能性は、適切なツールとリソースがなければ十分に発揮されません。
Integrate.io では、今日のダイナミックな状況におけるデータラングリングの複雑さと課題を認識しています。当社のプラットフォームは、ETL と ELT の両方のプロセスに対応するよう独自にデザインされており、データの準備と統合のニーズを効率化する包括的なソリューションを提供します。
ETL と ELT:Integrate.io の柔軟性
- ETL機能: 当社の ETL ソリューションでは、データラングリングが飛行中(In-flight)に実行されるため、目的地に到達する前に効率的な変換が可能であり、それによって、データがターゲットシステムに格納されるまでに、すでに構造化されてクリーニングされていることが保証される
- ELT機能: 特に Snowflake、Redshift、BigQuery のような最新のデータウェアハウスでは、ELT のトレンドと利点が高まっていることを認識し、当社のプラットフォームで格納後のデータ解析がしやすくなる。これは、このウェアハウスの計算能力を活用して、大規模なデータセットを効率的に処理し、プロセスをより高速かつスケーラブルにできるということである。
そして、Integrate.io だと、以下のようなことができます:
- データ品質の確保: 当社のプラットフォームはデータ品質を最優先していることから、データセットの検証、クリーニング、強化を行う機能がある。
- シームレスな統合: ETL の使用でも ELT の使用でも、多様なソースからのデータを簡単に統合し、きちんと分析に適した状態する。
- リアルタイム機能: リアルタイムのデータシナリオを先取りするために、当社のプラットフォームには、選択された方法に関係なく、流れ込んでくるデータを処理して取り回す能力がある。
ETL と ELT の両方に対応する 柔軟性で、Integrate.io は市場で際立っており、このような適応性がある競合他社は皆無であるため、多くのデータ専門家に好まれる選択肢となっています。
Integrate.io の 2 つの機能と、それがデータ駆動型プロジェクトにどのようなメリットをもたらすかを探るには、14日間の無料トライアルのご利用がお勧めです。 当社のプラットフォームがどのようにデータ ラングリングの課題をシンプルにし、データ品質を上げ、分析の取り組みを加速するかをぜひ直接ご体験ください。
より詳しくお知りになりたい方は、当社の専門家による無料のデモにお問い合わせいただき、ETL や ELT のご希望に関わらず、Integrate.io がデータプロジェクトにどのようにシームレスにフィットするかをぜひご確認ください。



