


Integrate.io、Snowflake、dbtの共通点は?Integrate.io、Snowflake、dbtを使うことで、ETLとELTの長所を融合させ、パワフルで柔軟性があり、費用対効果の高いETLT戦略を構築することができます。
このガイドでは、Integrate.io、Snowflake、dbtを使ったETLT戦略の作成方法を紹介します。しかし、まず最初に、そのような戦略の必要性、dbtとは何か、なぜIntegrate.io SnowflakeとdbtをETLTデータ変換スタックに組み込むのかについて説明します。
この記事は多くのことをカバーしていますので、以下のリンクを使って自由にナビゲートしてください。
ETLTでIntegrate.ioとSnowflakeとdbtを使う理由とは?
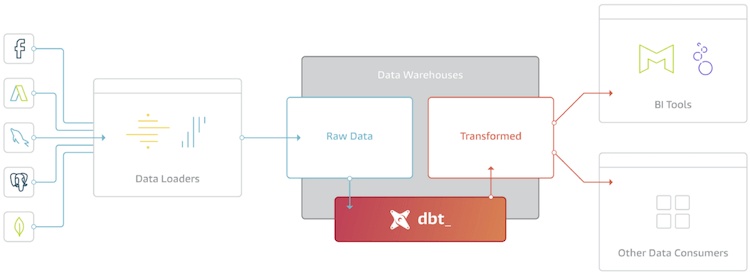
まずはETLT、Integrate.io、Snowflake、dbt、それらを使うメリットを俯瞰してみましょう。
ETLTのメリット
ETLTの利点を理解するためには、まずELT(抽出、ロード、変換)データ統合の利点と制約についての背景情報から始める必要があります。
近年、ELT(抽出、ロード、変換)はこれまで以上に人気が高まっており、いくつかのユースケースでは、従来のETL(抽出、変換、ロード)を凌駕しています。これは主に、Snowflakeなどのようなクラウドデータウェアハウスプラットフォームの出現による部分が大きいでしょう。これらのデータウェアハウスは非常に強力で効率的なため、ロード後にウェアハウス内のデータを迅速かつコスト効率よく変換することができます。
Snowflakeのようなクラウドデータウェアハウスソリューションが登場する前は、レガシーなオンサイトデータウェアハウスでロード後の変換を実行するのは時間がかかり、非現実的で、コストがかかりましたが、現在ではロード後のELT変換がより簡単かつ手頃な価格で実現できます。ELTの主な利点は、ETLの最初のステージング領域をスキップし、プリロード変換を設計して実行する必要性を回避し、生データを直接データウェアハウスにロードすることです。これにより、大量の非構造化データを迅速にインジェストして保存することができます。また、独自のデータ分析の要件に応じて、後からデータを構造化(再構築)する柔軟性も提供します。
しかし、ELTのみの戦略には深刻な制約があります。この制約は主にコンプライアンスとデータセキュリティに関連するものです。業界特有のコンプライアンス規則では、データウェアハウスにデータをロードする前に、機密データをマスクしたり、暗号化したり、削除したりしなければならない場合がよくあります。そのような制約に縛られていなくても、データウェアハウスにデータを送る前にデータを保護し、セキュリティを高め、企業の秘密を保護し、顧客の信頼を築くために、データを保護し、安全に保管しておきたいと思うかもしれません。
この点において、仮にELTのメリットを享受したいと考えていても、ワークフローにプリロード変換レイヤー(ETL)を追加せざるを得ないかもしれません。このような状況では、ほとんどの企業は単にETLに固執し、ELTの利点は利用できないものだと考えてしまいます。しかし、データ統合には、両方の長所を融合させた第三のアプローチ:ETLTが存在するのです。
ETLTワークフローでは、適用されるデータコンプライアンス基準に準拠するために、最低限必要なプリロード変換を実行します。その後、データをデータウェアハウスにロードし、データウェアハウスのコンピューティング能力を使用して残りの変換を行います。
ETLT データ統合戦略の最も重要な利点をレビューしてみましょう。
- コンプライアンス:ELTの高速なデータ取り込みと、必要に応じてビジネスロジックを変更できる柔軟性の恩恵を受けながら、ロード前のデータ変換を必要とするコンプライアンスとデータセキュリティ要件を満たすことができます。
- データマスキング:ロード前のデータマスキングによるデータの仮名化を可能にし、機密性の高いPII(個人を特定できる情報)、PHI(保護された医療情報)、IIHI(個人を特定できる医療情報)を特定の人物に結びつけることを禁止するコンプライアンス基準を遵守することができます。これらのコンプライアンス上の懸念事項は、欧州連合のGDPR基準、HIPAA、または他の基準の下でお客様に適用される場合があります。
- お客様の信頼:データセキュリティのレベルを高めることで、ETLTは顧客の信頼を築きながら、ELTの柔軟性の恩恵を受けることができます。
- セキュリティの向上:セキュリティの向上により、ETLTはプライバシー侵害、ハッキング、その他のセキュリティ関連の障害による被害の脅威を軽減します。
- インジェストの高速化:最も厳しいセキュリティ基準を維持しながら、データの取り込みを高速化します。
ETLTの詳細については、このデータ統合へのベスト・オブ・ツー・ワールドのアプローチに関する最近の記事を必ずお読みください。
Integrate.ioのメリット
Integrate.ioは、事実上あらゆるデータソース、クラウドベースのサービス、データベース、またはオンサイトシステムなどの広範囲におよびスピーディな接続機能を提供するETL-as-a-Serviceツールです。ソースに接続されると、Integrate.ioはあなたのデータをIntegrate.ioのステージングエリアに抽出します。そこからIntegrate.ioは、使いやすくビジュアルなインターフェースを介して設定した任意のデータ変換を実行し、データウェアハウスにデータをロードします。
ETLTプロセスでIntegrate.ioを使用する場合、Integrate.io内では、コンプライアンス目的で機密データ(PHIとPII)をマスクしたり、削除したり、暗号化したりするような、最小限の軽量な変換しか実行しません。ロード前の変換をシンプルにすることで、データをできるだけ早くデータウェアハウスにロードすることができます。そして、より複雑な変換(テーブルの結合、データの濃縮など)は、データウェアハウス自体で行われます。
Integrate.ioをロード前変換に使用する3つの主な利点は以下の通りです。
- スピード:Integrate.ioの幅広いソースとデスティネーションの接続とすぐに使える変換機能により、数分でETLワークフローを開発することができます。さらに、クラウドネイティブで完全にホストされたソリューションとして、Integrate.ioのインスタンスは、プラットフォームに最初にログインした瞬間からETLパイプラインの構築を開始する準備ができています。
- 使いやすさ:Integrate.ioは使いやすさを念頭に設計されています。プラットフォームは非常に操作が簡単なので、誰でもETLワークフローを開発するために使用することができます。もしあなたがETLの全くの初心者であっても、Integrate.ioの統合スペシャリストがいつでもあなたのユースケースで必要とする統合パイプラインの設計をお手伝いします。
- 手頃な価格:Integrate.ioを使用すると、使用しているコネクタの数に応じて、手頃な価格の定額制の月額料金を支払うことになります。パイプラインを介してより多くのデータを送信するために追加料金を支払う必要はありませんし、パイプライン内の変換を処理するために追加料金を支払う必要もありません。これにより、手頃な価格で予測可能な価格体系を実現しています。
Integrate.ioの仕組みについて詳しくは、こちらをご覧ください。
Snowflakeのメリット
Redshift、BigQuery、Azure SQL Data Warehouseなど、数あるクラウドデータウェアハウスのオプションの中で、なぜdbtとのペアリングにSnowflakeを選ぶのでしょうか?Mani Gandham氏は、Snowflakeの特徴を次のように簡潔に説明しています。
「Snowflakeは、既存のデータウェアハウスの選択肢にある機能を独自にブレンドしたものです。クラウドストレージにデータを保存しているため、他のものとは異なり、クローン作成、レプリケーション、タイムトラベル/スナップショットクエリを簡単に行うことができます。また、BigQueryのようにコンピュートとストレージを分離し、より高速なスケーリングと無制限の同時実行を実現しています。Redshift/Azure SQL DWのようなサーバーのクラスタの概念は残っていますが、管理はサイズのみに簡素化されています。BigQueryのように無制限のデータセットにスケールアップしながら、Redshiftのような常時稼働のクラスタと同様の低レイテンシのクエリをサポートしています。もう一つの大きな利点は、非常に高速で強力なUIコンソールとともに、JSONや非構造化データの取り扱いが格段に優れていることです。」
dbtのメリット
dbtは、データウェアハウス内でロード後に変換を行うフリーのオープンソース製品です。dbtは、SQLでデータ変換プロセスをプログラムすることができるため、社内のデータパイプラインを構築するための強力なソリューションだといえます。
dbtチームはこのソリューションについて次のように説明しています。
「dbtはELTのTです。dbtはデータを抽出したりロードしたりはしませんが、すでにウェアハウスにロードされているデータを変換するのが得意です。この "transform after load "アーキテクチャはELT(extract, load, transform)と呼ばれるようになってきています。」
「dbtは、ウェアハウス内で実行されるデータ変換ジョブの作成と実行を支援するツールです。 dbtの唯一の機能は、コードを取得してSQLにコンパイルし、データベースに対して実行することです。」
dbtチームはドキュメントの中で次のようにも述べています。
「dbt(データビルドツール)は、アナリティクスエンジニアがSelect文を書くだけでウェアハウス内のデータ変換を可能にします。」
「dbtはまた、dbtの視点に沿って、アナリストがよりソフトウェアエンジニアのように仕事をすることを可能にします。」
Integrate.ioを使ってデータコンプライアンスのために必要な変換を行い、Snowflakeにデータをロードした後。ETLTプロセスの最終的な状態では、意思決定者が必要とする特定のタイプのデータ分析に応じて、 dbtを使用してPIVOT、集約、JOIN、SELECT、GROUP BYなどの残りの変換を実行します。
最終的に、このETLTメソッドは、Integrate.ioの変換を可能な限りシンプルにすることで、大量のデータを素早くSnowflakeにロードするELTの特性を維持しつつ、dbtを使用して、ユースケースのニーズに応じてSnowflake内で変換を実行します。
Integrate.io、Snowflake、dbtを使用したETLT戦略の作り方
これまで言及したように、ETLT戦略の最初のステップでは、Integrate.ioがソースからデータを抽出し、PHIとPIIデータを削除/マスク/暗号化する基本的な変換を実行します。その後、Integrate.ioはデータをSnowflakeにロードします。そこからdbtは、あなたのニーズに合わせてSnowflake内での最終的なデータ変換を管理します。
もしIntegrate.ioで困ったことがあれば、Integrate.ioの専門家が電話一本で対応してくれます。
Integrate.ioを使ってデータを変換し、Snowflakeにロードしたら、次はdbtを使って残りの変換ワークフローを開発してみましょう。この段階では、一般的なSQLのスキルが必要です。
この段階では、一般的なSQLのスキルが必要になりますが、dbtパイプラインの作成方法の例を見ていく前に、dbtの機能とコンポー ネントについて少し理解しておくと良いでしょう。
*以下の3つのセクションと例は、SnowflakeのウェブサイトとMedium.comに掲載されたJohn L. AvenとPrem Dubeyの記事から抜粋したものです。
dbt: 機能とコンポーネント
dbtの一般的な特徴は以下の通りです。
- ELTの開発者は、SQLとしてコード化された変換ワークフローを作成することができます。SQLクエリは、トランスフォーメーション "パッケージ "内の "モデル "です。
- dbtのモデルは、SQL文によって作成されます。dbtのモデルはSQL文によって作成されたもので、テーブル、つまりデータウェアハウス(ここではSnowflake)にあるデータのビューです。
- dbtでは、テスト用にSQLクエリモデルのバージョンを作成することができます。
- 各モデルには、DAG(Directed Acyclic Graph)を作成するための参照リンクが用意されています。
dbtは3つの異なるファイルタイプで構成されています。SQL(.sql)、YAML(.yml)、MARKDOWN(.md)です。.sqlファイルは、ウェアハウスで変換するデータのテーブル/ビューを作成するSQLステートメントのように、モデルとテストを保存します。.sqlファイルの中には、パイプラインを実行しているときだけ持続するような儚いファイルもあります。.ymlファイルは、dbtプロジェクトの設定をプロジェクト設定ファイルに保存し、設定とテストの情報をスキーマファイルに保存します。.mdファイルはオプションです。モデルのドキュメントを保存します。
インストールし、利用可能なモジュールを理解する
dbtはソリューションをpipでインストールすることを推奨していますが、彼らはpipenvを使うことを好んでいます。インストール後、「dbt init」を使って新しいプロジェクトをセットアップします。あなたが作成するdbtプロジェクトには、モデル、分析、テスト、ドキュメント、マクロなど、様々なタイプのモジュールを含めることができます。
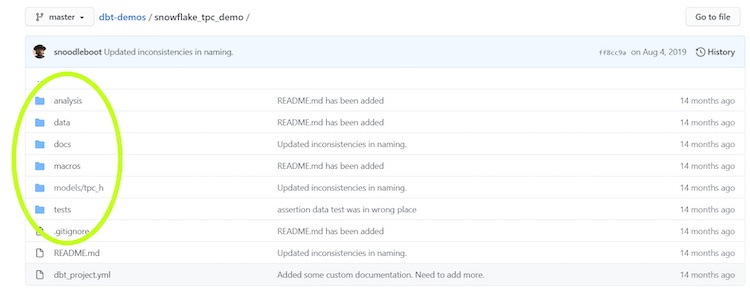
最も一般的な dbt モジュールの説明です。
-
Models:ELTパイプラインを形成する.sqlファイルが入っているディレクトリです。これらのファイルを順番に実行することで、変換パイプラインを形成します。
-
Tests:データのテストを実行する.sqlファイルが含まれるディレクトリです。特定の値が正確な仕様を満たしているかどうかをチェックするテスト・モデルと、任意の数のカスタム・テストを作成することができます。
-
Macros:Jinjaで作成した.sqlファイルが入っているディレクトリです。dbtのドキュメントによると 「dbtでは、SQLとJinjaというテンプレート言語を組み合わせることができます。Jinjaを使うと、dbtプロジェクトがSQLのためのプログラミング環境に変わり、通常では不可能なことができるようになります。」マクロは何度も何度も使うことを想定しているので、それらを組み合わせてより複雑な処理を作成することができます。
-
Docs: .mdファイルにフォーマットされたオプションのドキュメントを含むディレクトリ。
-
Logs:実行ログを含むディレクトリ。「dbt run」コマンドを実行すると、dbtは実行ログを作成して保存します。
-
Target directories:dbtは、ドキュメントのコンパイル、ビルド、実行時にターゲットディレクトリを作成します。これらのディレクトリには、メタデータとコンパイルされたSQLコードが格納されます。
- Analysis: このディレクトリには、すぐに実行できるSQLクエリが含まれています。ディレクトリにはすぐに使えるSQLクエリが含まれており、データ分析のためにデータの異なるビューを提供することができます。これらの分析は、いつでもデータで使用できるように保存しておくことができますが、プロジェクトのデータ変換ワークフローの一部ではありません。
これらのモジュールや他のモジュールについては、dbtのドキュメントを参照してください。
Snowflake上でのdbtのセットアップ
Snowflake上でdbtを設定するには、プロセスを実行しているマシンの~/.dbtディレクトリにprofiles.ymlファイルを置く必要があります。また、dbt_project.ymlのプロファイルフィールドに次の'sf'プロファイル情報を含める必要があります。

データ変換パイプラインの開発
これで、データパイプラインを作成する準備が整いました。Snowflakeでは、公開されているdbt/Snowflakeのデモの文字列変換を利用し、dbtでこれをどう実現すればよいかのすばらしい例を提供しております。これには、TPC-Hベンチマークデータセットも含まれています。次の例では、John L. Aven氏とPrem Dubey氏が、どのようにしてこれらのデータセットを集約して分析を実現したかを見てみましょう。
Snowflakeは、TPC-Hベンチマークデータセットを提供する公開されているdbt / Snowflakeデモからの一連の変換を使用して、dbtでこれを行う方法の優れた例を提供します。
- Average Account Balance for all Customers in a Nation
- Average Available Quantity for each Product, regardless of Supplier
- Average Supply Cost for each Product, regardless of Supplier
AvenとDubeyは、この情報を以下の列を持つテーブルに集約しました。
- Customer Name
- Customer Account Balance
- Market Segment
- Nation
- Part Available Quantity
- Part Name
- Part Manufacturer
- Part Brand
- Part Type
- Part Size
- Region
- Supplier Account Balance
- Supplier Name
- Supply Cost for each Part and Supplier Pair
次に、期待されるアナリティクスビューを実現するために、次のような一連のSQL変換を選択しました。このように(パッケージとして)順次に変換でデータをフィルタリングすることを選択することで、方向性を維持しやすくなり、間違いがないことを確認しやすくなります。これがパイプラインです。
1) supplier_parts: JOIN three tables (PART, SUPPLIER, PARTSUPP) on the PARTKEY field and the SUPPKEY field. This step creates an ephemeral table.

2) Average_account_balance_by_part_and_supplier: Compute the average aggregation for the supplier account balance by part and supplier. This step creates an ephemeral table.

3) average_supply_cost_and_available_quantity_per_part: Calculate the average aggregation of the supply cost and available quantity, calculating by part for the supplier. This step creates an ephemeral

4) supplier_parts_aggregates: JOIN the aggregations to the supplier_parts table. This step creates a permanent new table.

5) customer_nation_region: JOIN the three tables (CUSTOMER, NATION, REGION) by the NATIONKEY. This step creates an ephemeral table.

6) average_acctbal_by_nation: Calculate the average_customer_account_balance over the nation field. This step creates an ephemeral table.

7) customer_nation_region_aggregates: JOIN the average_customer_account_balance to the customer_nation_region table. This step creates a permanent new table.

8) analytics_view: JOIN customer_nation_region_aggregates to supplier_parts_aggregates. This is for a BI Dashboard.

これで変換パイプラインは終了です。各モデルにはDAG(Directed Acyclic Graph)を生成するための参照リンクが含まれていることを覚えておいてください。そのためdbtを使用すると、SQL変換の背後にあるシーケンスとロジックを示す視覚的なグラフを簡単に確認することができます。
dbtのデータ変換パイプラインをデザインする方法を見てきましたが、次のステップでは、このデータを様々なデータ分析やBIソリューションに接続して、分析を実行したり、グラフを作成したり、 データを表示してチームメンバーや意思決定者と共有したりすることができます。
まとめ
このトピックを完全にカバーするには十数本の記事が必要になるため、このブログを通して、Integrate.io / Snowflake / dbtを使用したETLTデータ統合戦略の作成の背景、理由、および方法についての一般的な理解が得られることを願っています。また、今後のデータ統合プロジェクトでIntegrate.ioを検討していただければ幸いです。
エンタープライズグレードのETL-as-a-serviceソリューションとして、Integrate.ioは、ETLTパイプラインに強力で使いやすい機能を提供します。あなたのデータ統合のユースケースが何であれ、それがETLであれ、ELTであれ、ETLTであれ、Integrate.ioチームはいつでもあなたの目標を達成するためのお手伝いをしています。今すぐIntegrate.ioのオンラインデモを予約し、無料トライアルを受けてみてはいかがでしょうか?




