


パート1では、Integrate.ioダッシュボードのShopifyストアとデータデスティネーションの設定を行いました。また、Shopify Admin APIの中でも特によく使用される部分についても触れました。それでは、Shopifyストアからデータを取得し、設定したデータデスティネーションにロードするためのパイプラインを設定していきましょう。
Shopifyパイプラインを作成する
まず、ダッシュボードの[パッケージの作成]メニューオプションを使用してパッケージを作成します。
手軽にスタートする方法
Integrate.ioには、異なるShopify API(Orders, Products, Customers, and more)からRedshiftにデータを引っ張ってくるための既に用意されたパッケージテンプレートがあります。それらを使ってパッケージパイプラインを自動生成し、必要に応じて変更を加えることができます。
まず、"Shopify [Order Refunds] to Redshift "テンプレートを選択します。
いったんパッケージを作成したら、以下のようなデータフロー図が表示されます。

テンプレートパイプラインの概要と修正
パイプラインを理解して、ニーズに合わせて変更していきましょう。
変数の設定
ショップ名と接続IDを入力します。この情報は、先ほど作成した接続から確認できます。

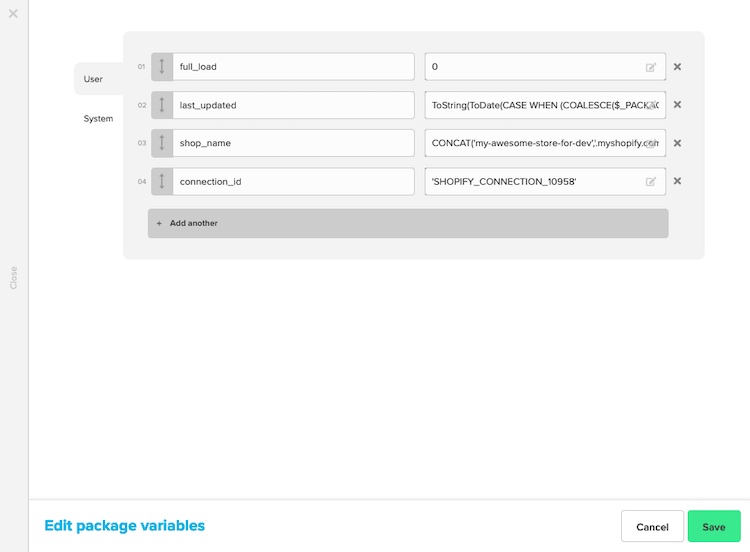
認証でShopifyの接続を追加するには、REST APIコンポーネントを編集します。

「Shopify API [Order Refunds] to Redshift」テンプレートパッケージは、RedshiftでOrder Refundsのデータベーステーブルを作成するためのパイプラインです。しかし、それと同時にパート1で述べたように、トップレベルの注文情報や、商品や顧客のリソースからの類似情報にも興味があります。
Integrate.ioは「Shopify API[Orders] to RedShift」という名前のトップレベルのOrderフィールド用の別のテンプレートが提供されており、その中には非常にシンプルなパイプラインが含まれています。

このテンプレートパッケージを独立して使用し、変数を設定することもできますし( Order Refundsのパイプラインで行ったように)、このパッケージパイプラインを参照して既存のパイプラインで同様のフローを作成することもできます。作成するテーブルが複数ある場合は、後者のオプションの方が良いでしょう。複数のテーブルに対してデータをロードする予定なので、既存のパッケージにトップレベルの注文フィールド用のフローを追加しました。

パイプラインを見ていると、4種類のIntegrate.ioコンポーネントを使用していることに気づくでしょう。
- REST APIソース:このコンポーネントは、Shopifyのadmin APIを使用してShopifyからデータを取得するために使用します。
- Clone:このコンポーネントは、同じデータに対して異なる操作を適用するために使用します。
- Select:このコンポーネントは、このコンポーネントは、データ内のフィールドを選択、作成、またはフィルタリングするために使用します。
- Redshiftデスティネーション:このコンポーネントは、選択したデータをRedshiftに書き込むために使用します。
ちょっと魔法のように見えても、心配しないでください。これは、他の2つのリソース(製品と顧客)のフローを追加した際に説明します。
参考までに、3つのリソースすべてのフローを追加した後の最終的なパイプラインは以下のようになります。

上記の図のようにするためには、2つの作業を完了させる必要があります。
- CustomersとProduct APIのパスをパイプラインに追加します。
- Redshiftのデスティネーションコンポーネントをカスタムコンポーネントに置き換えます。
それでは、これらの作業を1つずつ順を追って見ていきましょう。パイプラインをテンプレートパッケージだけに頼らずに済むように、各コンポーネントが何をするのかを理解しておくことが重要です。
CustomersとProductのエンドポイントをパイプラインに追加する
手順ははどちらのリソースも似たようなものです。
1) Orders用の既存のREST APIコンポーネントをコピーします。

2) コンポーネントの詳細を変更します。すなわち、URLのResourceをproducts.json,に変更し、ベースレコードのJSONPath式を$.products[*]に変更します(レスポンスのproductsフィールド配列の配下にあるすべてのオブジェクトを選択することを意味します)

3つ目のステップでは、Integrate.ioが自動的にスキーマの差分(商品と注文の間)を検出し、プロンプトをクリックすることで適用されます。

3) Cloneコンポーネントを追加。
4)Croneの下には、2つのSelectコンポーネント(名前はproduct_fieldsとflatten_product_variants)を並列で追加します。まず1つ目はハイレベルの製品フィールド(product-id, title, tagsなど)を選択し、2つ目はレスポンス結果のバリアントフィールド内でネスト化されている製品バリアントを選択します。

5) product_fieldsのSelectコンポーネントで、取得したいトップレベルのフィールドを選択し、カスタムエイリアス値で名前を変更します

6) variants フィールドは配列になっているので、まず[Flatten](https://www.integrate.io/docs/flatten/) 関数を適用して配列オブジェクトに一つずつアクセスできるようにし、次に[JsonStringToMap](https://www.integrate.io/docs/jsonstringtomap/) メソッドを使ってこれらのオブジェクトをマップに変換します。

7) 最後に、parse_product_variants という新しい select コンポーネントで variant フィールドを選択します。タイプキャスティングと (long)variant#idといったように # 文字を使って、バリアント内の id フィールドにアクセスし、それをLong型 (元々は文字列) に変換していることに注目してください。

現時点でグラフはこのようになっています。

同様の手順が顧客リソースに対しても実行されます(ここでの製品バリアントの配列は、顧客リソースの顧客アドレスの配列に似ています)。これでパイプラインを仕上げる最後のステップを残すだけになりました。
データデスティネーションを追加する
データをRedshiftで管理したい場合は、先ほど使ったテンプレートに付属していたRedshiftコンポーネントを使って、Redshift接続を追加します。別のデータデスティネーションがある場合は、それらのRedshiftコンポーネントを入れ替えて、独自のデータベース・デスティネーションコンポーネントを追加すればOKです。データベース・デスティネーションを追加するには、以下の手順に従います。
1) 最後に選択したコンポーネントの下部にある+のアイコンをクリックします。次の画面で適切な選択先コンポーネントを選択します。
2) 生成されたデータベースコンポーネントを編集します。
- ターゲット データベース接続(以前に作成したもの)とターゲット テーブル名を指定します。
- パイプラインでデータをデータベースにインクリメンタルにプッシュしたい場合は、Operation typeで「Merge with existing data using update and insert」を選択します。

3) スキーママッピングのステップで、オートフィルをクリックしてフィールドを自動的に入力します。テーブルの行に一意の識別子(主キー)を指定します。


4) パイプライン内の他のテーブルに対して手順1-3を繰り返します。
パッケージの準備ができました。

パイプラインのテスト
パッケージをテストする前に、以下の最終チェックリストを完了することをお勧めします。
- [Save and Validate] をクリックしてエラーをチェックします。エラーがない場合は、緑色の信号が表示されます。

- 黄色の「Run Job」ボタンをクリックします。クラスタがない場合は、サンドボックスクラスタを作成し、それを選択します。変数の値を確認し、「Run job」をクリックします。

- ダッシュボードでジョブの進行状況を確認できます。ジョブの最初の実行では、データベース接続の設定が悪いため、失敗しました。

- 緑で100%になったら、パッケージで指定したデータベースのデスティネーションのデータを検証します。オプションとして、すべてが良好であれば、メジャーバージョンのパッケージを作成することもできます。

データの可視化
データを可視化する場合、多くのオプションが利用できます。この記事では、Google Data Studioを使用します。これは便利でノーコードのツールであり、ビジュアライゼーションを使用して一般的なクエリのほとんどに答えるのに十分な汎用性を持っています。
それでは、Google Data Studio にデータを接続する方法を見ていきましょう。
1) Google Studio のホームページにアクセスし、新しいダッシュボードを作成します。データリソースのプロンプトが表示されます。データを保存するためにIntegrate.ioパイプラインで使用した保存先のデータベースの詳細を提供します。この例では、PostgreSQLデータベースを追加し、とりあえずshopify_ordersを選択しました。

2) フィールドのメタデータを確認します。Data Studioはフィールドのデータ型を検出するのに非常に優れていますが、場合によっては正しく検出できないことがあります。そこで、データスタジオで「Resource」→「Managed Added Data Resources」→「Edit」と進み、データタイプを確認します。


これで、ビジュアライゼーションの作成を始めることができます。Google Data Studio がサポートしているチャートの種類は以下の通りです。
これらのオプションをすべて網羅するのではなく、答えたいビジネス上の問いから始めて、それに応じてビジュアライゼーションを作成します。
Q: どれくらいの注文があるか?
この問いに答えるためには、以下のようなスコアカード型のチャートを使用することができます。

すべての設定は右側のボックスで行われます。ここでは、いくつかの重要な概念を覚えておきましょう。
- メトリック: 可視化される値。この場合、order_numberがメトリックです。
- 集計タイプ。スコアカードの出力は1つの値だけなので、何らかの方法ですべての値を集約する必要があります。ここでは集約タイプをCTD (Count Distinct)としました
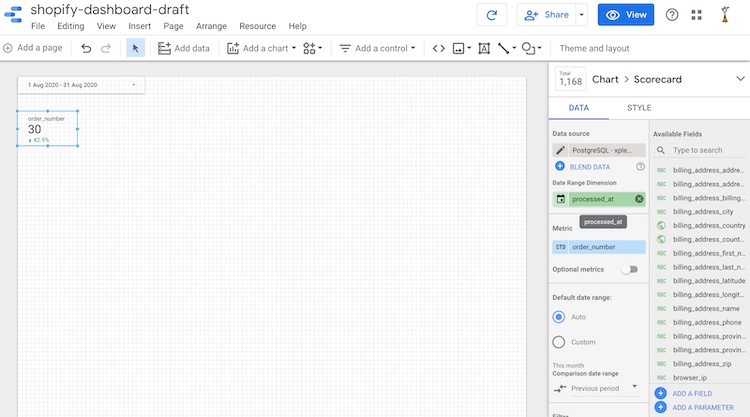
Q: 今月は何件の注文がありましたか?また、前月と比較して数字はどのように変化していますか?
このような質問に対しては、追加のコントロールを使用することができます。ダッシュボードに日付範囲コントロールを追加してみましょう。デフォルトの日付範囲を "今月 "に設定します。

スコアカードにはまだ同じ数字が表示されています。カウントを更新するには、Data Studioが注文の日付を決定する "Date range Dimension "を指定する必要があります。私たちの場合、その情報は processed_at フィールドにあります(Data Studio はフィールドのタイプを Date として検出しています)。先月と比較した変化を表示するために、"比較日付範囲 "の値を "前の期間 "に指定します。
Q: 売上高、値引き、税金の合計は?そして、先月と比べてどれくらい変わったのか?
これらの値は、それぞれ total_price, total_discounts, total_taxes のフィールドから、注文数と同じように計算することができます。ここでは合計集計を適用し、通貨の種類をUSD-USドルと指定します。

スタイルのオプションでは、「Compact Numbers」と「Show absolute Change」のオプションを True に設定して、好みに合わせて設定しました。

Q: 年間を通しての売上高の伸びは?
この問いには、時系列チャートをプロットし、メトリックを total_price aggregated by sum、ディメンジョンを processed_at と指定し、"Granularity" レベルを month に設定します。

Q: 曜日によって注文件数は変わるか?
このために、別の時系列を棒グラフでプロットし(この場合、線グラフはあまり意味がないので)、order_numberを一意にカウントして集計し、粒度を "Day of the week "レベルに設定します。

Q: 私の注文の何%が返金になりますか?
円グラフをプロットし、"Dimension "でfinancial_statusを指定します。Shopify APIによると、支払いステータスは "paid", "refund", "pending "の3つの値があります。円グラフはそれらの割合を表示します。

Q: 注文はどこからきているのか?
ここでは、ジオマップ・チャートを使用します。チャートのディメンションには、shipping_address_country_codeまたはshipping_address_countryのいずれかを指定できます(これらのフィールドは両方ともData Studioによってロケーションとして検出されるため)。また、特定の都市をズームして、より特定の場所をピン留めすることも可能です(ドキュメントを参照してください)。マップに隣接して円グラフを追加し、凡例として機能するようにします。これはジオマップチャートと同じディメンションを使用します。

Q: 今月の新規顧客数は?取引のうち、保留中のものは何件ありますか?現在どれくらいの受注残がありますか?
これらの質問は、スコアボード・チャートでカバーすることができます。このような質問に答えるために使用する新しいコンセプトは、フィルタリングです。customer_order_countsフィールドの値が1に設定されている行のみを含むfirst_orderと呼ばれるフィルタを作成しました。


同様のフィルタを作成して、保留中のトランザクション(financial_statusが'pending'と等しくなる行のみを含む)と受注残(fulfulfulment_statusがfilledと等しくなる行を除く)を取得することができます。
Q: 特定の国の上記のメトリクスをすべて表示するにはどうすればよいか?返金された注文に関連する値を表示するにはどうすればよいか?
2つのDataコントロールウィジェットを追加します。1つはコントロールフィールドが shipping_address_country で、もう1つはコントロールフィールドが financial_status です。

Q: ダッシュボードを見栄えよくして、チームで共有するにはどうすればよいか?
Data Studioにはたくさんのスタイリング機能があります。私は、いくつかのテキストや長方形のボックスを追加したり、スコアカードの位置を揃えたり、テーマを変更したりしました。また、画像(自分のウェブサイトのスクリーンショットやロゴ)からテーマの色を抽出する便利なオプションもあります。

最後に、Googleドキュメントファイルを共有するのと同じように、URLを使ってレポートを共有することができ、Shopifyのデータから構築されたインタラクティブなレポートを見ることができます。また、これらのレポートをウェブサイトに埋め込むこともできます。

他のテーブル(顧客と製品スキーマ)も同じように可視化することができます。
データの同期
ソリューションを完成させるには、スケジュール同期機能を追加することをお勧めします。Integrate.ioは、定期的にパッケージを実行する機能を提供しています。そのためには、Integrate.ioのダッシュボードからスケジュールを作成し、実行する頻度とパッケージを指定するだけです。
In Integrate.io

スケジュールを作成することで、データが頻繁に更新されるようになります。Integrate.ioはShopifyからインクリメンタルにデータを取得するだけです。
Google Data Studio側の設定
Data Studioで、[Resource] > [Manage added data sources] > [Edit resource]に移動し、[Data freshness]を更新します。1時間に設定した場合、Data Studioは1時間ごとにデータベースをチェックし、それに応じてチャートを更新します。その場でデータを更新する必要がある場合は、ウィンドウ上部の共有ボタンの横にある更新矢印を使用して更新することができます。

まとめ
今回の記事では、以下の作業を完了しました。
- Shopifyストアのデータを視覚的に分析する仕組みを設定する。
- Integrate.ioでShopifyとDataの接続を一度だけ設定する。
- 様々なIntegrate.ioコンポーネントを使用して作成したパイプラインを経由して、Schedulesを使用してデータをインクリメンタルにロードする(最後にフェッチしたデータからの変更のみ)。
- Google Data Studioの視覚化ツールの助けを借りて、多くの日々の分析クエリに答える。
Integrate.ioとGoogle Data Studioでできることはまだまだたくさんありますが、それはまた別の記事で紹介することにします。
次のステップ
-
Google Data studioでCommunity visualizations を試してみてください。(注意:これらのアプリのほとんどが独自のサーバーにデータを保存するため、データが機密である場合、注意してください)。
-
データのブレンド: 商品、顧客、注文を1つのテーブルにまとめるのはどうでしょうか?Google Studioでブレンドを行うことができます。また、ストレージの非正規化されたテーブルによるデータ容量の非効率性が特に問題とならない場合は、Join Transformationを使用してIntegrate.ioパイプラインでデータを結合することができます。
- 抽出されたデータを使用して、機械学習と統計学を使用してインサイトを集め、予測を行い、異常を検知することができます。




