
HDFS(Hadoop 分散ファイルシステム)が、分散コンピューティングクラスタ全体で大量のデータを効率的に保存および検索することで、ビッグデータ処理にどのような革命をもたらすかをご紹介します。このガイドでは、HDFS の内部構造を明らかにし、ビッグデータ処理のための強力なアプリケーションを探求しながら、HDFS の詳細な概要を包括的に説明しています。HDFS の可能性を最大限に引き出し、よくある課題に取り組み、実装を成功させるための貴重なインサイトを得るために不可欠なベストプラクティスを学びましょう。
主なポイント
- HDFS は Hadoop の重要なコンポーネントであり、データの複製を通じて信頼性の高いストレージを提供する
- ETL ツールは、HDFS でのデータの処理および変換に不可欠である
- HDFS はビッグデータのフレームワークと統合し、バッチ処理に対応している
- HDFS は スケーラビリティ、フォールトトレランス(耐障害性)、費用対効果を保証する
- 読み書き操作は NameNode によって管理され、DataNode によって実行される
- データのレプリケーションで、フォールトトレランスと冗長性が得られる
- HDFS は、ビッグデータ処理におけるスケーラブルなストレージと効率的なデータ分析のために広く使用されている
はじめに
Hadoopのエコシステムと HDFS において、その関係を理解するのは重要です。Apache Hadoop は、データを保存、処理、分析するためのさまざまなコンポーネントを包含するオープンソースのフレームワークであり、HDFS は Hadoop のエコシステムのファイルシステムコンポーネントであり、データの保存と検索を担当します。もっと簡単に言えば、HDFS はより広範な Apache Hadoop のフレームワーク内のモジュールです。
Hadoop は当初、当時 Yahoo で働いていたダグ・カッティング氏とマイク・カファレラ氏によって作られました。そして Yahoo の関与と貢献により、HDFS はオープンソースでスケーラブルな分散ファイルシステムとして形作られ、それによって Apache Hadoop のフレームワークの重要な構成要素となっています。
ビッグデータ処理における HDFS の役割
HDFS は Hadoop のエコシステムの重要なコンポーネントであり、効率的なビッグデータ処理において重要な役割を果たしています。また、信頼性の高いストレージと管理を可能にし、並列処理と最適化されたデータストレージを保証することで、より高速なデータアクセスと分析が実現します。
ビッグデータ処理において、HDFS は大規模なデータセットにフォールトトレランスのあるストレージを提供することに優れており、これはデータレプリケーションによって実現します。また、HDFS はデータウェアハウス環境において、大量の構造化・非構造化データの保存や管理ができます。さらに、Apache Spark、Hive、Pig、Flinkなどの主要なビッグデータ処理のフレームワークとシームレスに統合することによって、スケーラブルで効率的なデータ処理を実現します。HDFS は Unix ベース(Linuxオペレーティングシステム)と互換性があるため、ビッグデータ処理に Linux ベースの環境を好む組織にとって理想的な選択肢となります。
また、HDFS によって、組織は膨大なデータ量を処理し、複雑なデータ分析を実行できるようになります。データサイエンティストやアナリスト、企業は HDFS を活用することで、価値あるインサイトを抽出してデータ駆動型の意思決定を行い、膨大なデータセット内の隠れたパターンを明らかにすることができます。ビッグデータの詳細についてはこちらをご覧ください(英語)。
HDFS によるビッグデータ処理における ETL(抽出、変換、格納)ツールの重要性
HDFS によるビッグデータ処理における ETL の重要性は以下の通りです:
- 様々なソースからデータを抽出し、それを変換して HDFS に格納するプロセスを効率化する
- ETL ツールで、データのクリーニング、エンリッチメント、データの一貫性と品質の確保が可能になる
- ワークフローのオーケストレーション機能を提供し、複雑なデータパイプラインを効率的に管理する
- データガバナンス機能を提供することで、コンプライアンス、セキュリティ、データリネージの追跡を保証する
- ETL ツールと HDFS を活用することによって、組織は大規模データを効率的に処理および分析することができる
- ETL ツールと HDFS を組み合わせることで、洞察力に富んだデータ分析を通じて情報に基づいた意思決定ができるようになる
HDFS(Hadoop分散ファイルシステム)とは
HDFS(Hadoop 分散ファイルシステム)は、Hadoop のクラスタ内の複数のマシンにまたがる大規模なデータセットを管理するために設計された分散ストレージシステムであり、データへの高速アクセスを提供し、Apache Hadoop のエコシステムで大規模なデータセットを処理するのに有用です。
HDFS は標準的なハードウェアと分散コンピューティングを使用することで、コスト効率の高いストレージソリューションを提供します。企業は HDFS を使うことで、高額な費用を負担することなくストレージ容量を拡張することができることから、HDFS は大量のデータを管理するための手頃な選択肢となります。
さらに、HDFS は様々なクラウドプロバイダと統合して柔軟な価格オプションを提供しており、それによって、組織はそれぞれの要件に基づいてストレージコストを最適化することができます。例えば、AWS(Amazon Web Services)はAmazon EMR を通じてサービスとして HDFS を提供しており、ユーザーは AWS のクラウドインフラストラクチャ上でデータの保存と処理に HDFS を活用することができます。
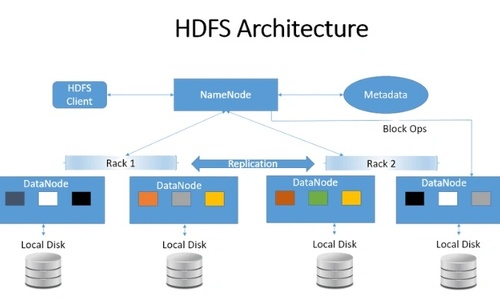
HDFS アーキテクチャ
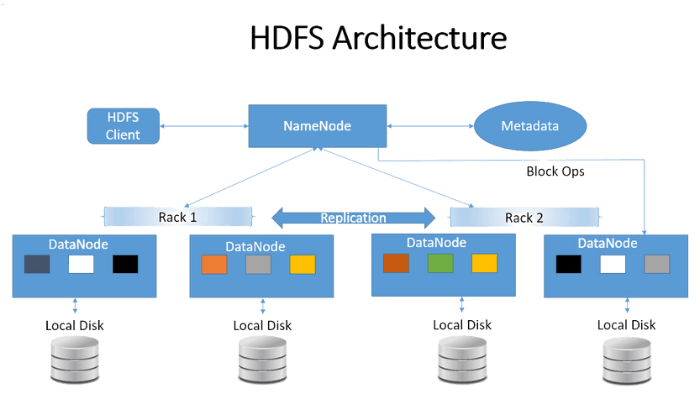
HDFS は 主に Java で書かれており、それによって Java のプログラミング言語は HDFS のアーキテクチャと機能の不可欠な部分となっています。Java は NameNode、DataNode など様々なクライアントのインターフェースといった HDFS のコアコンポーネントの基盤を提供しますが、PySpark のようなライブラリやフレームワークを通じて、Python を HDFS とともに利用することもできます。PySpark は HDFS と対話するための Python API を提供し、ユーザーは Python を使って HDFS データに対してデータ処理、分析、機械学習タスクを実行することができます。
HDFS は、いくつかの重要な要素からなるマスター・スレーブのアーキテクチャに従っています。以下の要素を見てみましょう:
1.NameNode:HDFS の中央メタデータ管理ノードとして機能し、ファイルシステムのディレクトリ構造、ファイル名、属性に関する重要な情報を保存する。また、NameNode は DataNode 間のデータブロックの位置を追跡し、読み込み、書き込み、レプリケーションなどのファイル操作をオーケストレーションする。
そして、NameNode コンポーネント内には以下の2種類のファイルがあります:
a. FsImage ファイル:ストレージシステムとして機能し、ファイルシステムの構造の包括的かつ組織的な表現を含んでおり、HDFS 内の階層レイアウトの完全なスナップショットをキャプチャする。
b. EditLogs ファイル:ファイルシステムのファイルに加えられた変更を全て追跡する。これはログとして機能し、時間の経過とともに行われた変更と更新を記録する。
HDFS のコンテクストでは、ZooKeeper は Hadoop のクラスタの状態とメタデータ情報を維持する上で重要な役割を果たしており、信頼性の高い分散調整サービスを提供することで、HDFS の NameNode や DataNode のような重要なコンポーネントの高可用性と一貫性を保証します。
2.DataNode:ファイルの実際のデータ ブロックを保存する。 これらは、NameNode から読み取りおよび書き込み操作の命令を受け取り、 データ複製を通じてフォールトトレランスを確保する。定期的に3 秒ごとにハートビート メッセージを NameNode に送信し、その動作ステータスを示す。 DataNode が動作不能になると、NameNode はレプリケーションを開始し、データの冗長性とフォールト トレランスのためにブロックを他の DataNode に割り当てる。
3.HDFS のファイル ブロック:HDFS では、データは保存と検索を最適化するためにブロックに分割される。デフォルトでは、各ブロックのサイズは 128MB だが、これは必要に応じて調整できる。例えば、サイズが 550 MB のファイルがある場合、5つのブロックに分割され、最初の4つのブロックはそれぞれ 128 MBで、5番目のブロックは38 MBになる。
ファイルブロック

ブロックのサイズとそれがファイルのストレージシステムに与える影響がわかれば、データ処理を最適化することができます。
4.Secondary NameNode:HDFS の Secondary NameNode は、ネームスペースの定期的なチェックポイントを実行するヘルパーノードであり、HDFS の変更を含むログファイルのサイズを制限内に保ち、障害が発生した場合の NameNode の速やかな復旧を支援する。
5.メタデータ管理:HDFS では、NameNode は起動時にブロック情報をメモリに読み込み、編集ログデータでメタデータを更新し、チェックポイントを作成する。メタデータのサイズは NameNode の RAM によって制限される。
従来のファイル システムとの比較
従来のファイルシステムと比較して、HDFS には以下のようなビッグデータ処理における利点があります:
-
スケーラビリティ(拡張性):クラスタ内の複数のマシンにデータを分散することでスケーラビリティを得られる
- フォールトトレランス:フォールトトレランスはデータのレプリケーションによって達成される
- データ処理:ビッグデータ処理に最適化され、MapReduce のようなバッチ処理フレームワークに対応し、並列処理と効率的なリソース利用を実現する
- 費用対効果:コモディティ・ハードウェア上で動作し、クラスタの分散特性を活用して高いスループットとパフォーマンスを実現する、コスト効率の高いソリューション
- データサイエンスの探索:大規模データセットの効率的なストレージと処理を提供することで、データサイエンスのワークフローを実現し、それによってデータサイエンティストは分散型コンピューティングクラスタ上でデータの前処理、特徴抽出、機械学習アルゴリズムのトレーニングを実行できるようになる
HDFS の仕組み
HDFS は、その分散型のフォールトトレランスの設計により、データのスケーラブルな保存、検索、処理を実現します。また、読み取りと書き込み操作の最適化、データの冗長性の確保、効率的なデータ管理のためのアルゴリズムの組み込みをしており、データをクラスタに分散させることで、ビッグデータ分析を後押しします。以下は、HDFS の主な機能です:
HDFS の読み書き操作
HDFS は分散データノードとメタデータ管理を通じて、シームレスでスケーラブルな読み取り/書き込み操作を実現します。
書き操作
HDFS にファイルを書き込むとき、クライアントはメタデータのためにNameNodeと通信します。クライアントは受け取ったメタデータに基づいてDataNode と直接やり取りします。例えば、[ブロックX]を書き込む場合、それは[DataNode A] に送信され、別のデータセンターにある[DataNode B]と[DataNode A]と同じラックにある[DataNode C]にレプリケートされます。DataNode は NameNode に書き込み確認を送信し、それによってデータの信頼性とフォールトトレランスが保証されます。
読み操作
HDFS から読み取るために、クライアントは DataNode の場所を提供する NameNode からメタデータを取得し、クライアントはこの DataNode と対話し、並行してデータを読み込みます。
そして、データは DataNode からクライアントに直接流れ、それによって効率的で同時並行的なデータ検索が実現します。
ブロックをすべて受信したら、クライアントはさらなる処理のためにそれらを結合します。
注:Hbase は 、HDFS 内のデータへのランダムなリアルタイムの読み書きのアクセスを提供する Hadoop のエコシステムの一部であり、データを HDFS に直接格納することも、HBase を通して格納することもできます。データ消費者は、HBase を使って HDFS のデータをランダムに読み書きし、HBase は HDFS の上に置かれ、読み書きのアクセスを提供します。
データレプリケーション と フォールトトレランス
HDFS はレプリケーションによってデータの信頼性を保証します。データのブロックは複数の DataNode に複製され、それによってフォールトトレランスと可用性が上がります。
HDFS のレプリケーション管理: フォールトトレランスとデータの冗長性の確保
データのレプリケーションは、フォールトトレランスとアクセシビリティを保証します。例えば、ブロックのレプリケーション係数が3の場合、3つのコピーが別々の DataNode に保存され、そのうち1つの DataNode に障害が発生しても、残りの2つのレプリカからデータにアクセスできます。この冗長性により、データ保護、可用性、信頼性が強化されます。このレプリケーションメカニズムを実装することで、HDFS はデータへの継続的なアクセスの保証、データの整合性の強化、Hadoop のエコシステム内のフォールトトレランスの向上を実現し、それによって、組織は大規模なデータの保存と処理に対応できるようになります。
HDFS におけるフォールトトレランスの強化:レプリケーションと Erasure Coding
HDFS はデータの可用性と信頼性を保証する強固なフォールトトレランス機能で知られており、レプリカの作成と Erasure Coding によってフォールトトレランスを実現しています。ユーザーデータのレプリカは様々なマシンに作成され、それによってマシンが故障してもデータにアクセスできるようになっています。
Hadoop 3 は、Erasure Coding を導入したことでフォールトトレランスを維持しながらストレージ効率を上げました。そして HDFS は、レプリケーションと Erasure Coding の組み合わせによって、大規模データの保存と処理に高いフォールトトレランスと信頼性を発揮します。
HDFS の NameNode と DataNode の関数
HDFS は NameNode と DataNode という2つの重要なコンポーネントを持つ 分散型の HDFS アーキテクチャを採用しており、それぞれが HDFS のクラスタ内のデータの管理と保存において明確な役割を果たします。
NameNode
HDFS の NameNode には重要な役割があります:
- ファイルシステムの名前空間管理:ファイルシステムの名前空間とファイルとディレクトリのメタデータを管理し、ファイルのパーミッション、タイムスタンプ、ブロックの位置などの属性を追跡する。
- ブロック管理:ファイルとデータブロックのマッピングを管理し、どの DataNode がデータブロックを格納するかを追跡して、レプリケーションによってデータの信頼性を確保する。
- クライアント・コーディネーション:クライアントと DataNode の仲介役を務め、読み込み、書き込み、削除などのファイル操作に対するクライアントの要求を処理する。NameNode はメタデータを処理し、必要なデータにアクセスするために関連する DataNode にクライアントを誘導する。
DataNode
DataNode は HDFS 内のデータの保存と管理を担当します。主な機能は以下の通りです:
-
ブロックストレージ:ファイルのデータブロックをローカルストレージに保存する。
-
ブロックレプリケーション: フォールトトレランスを保証するためにデータブロックを複製する。
- ハートビートとブロックレポート:ハートビート信号とブロックレポートを定期的に NameNode に送信する。
NameNode と DataNode の間で責任を分担することで、HDFS のスケーラビリティ、フォールトトレランス、効率的なデータ管理ができるようになります。その際、NameNode はメタデータの調整に集中し、DataNode はデータの保存とレプリケーション操作を処理します。
ビッグデータ処理のための HDFS
信頼性の高いストレージと効率的なビッグデータ処理には、HDFS が非常に重要です。ここではその主要な側面を見てみましょう:
MapReduce のプログラミングモデルについて
MapReduce のプログラミングモデルは、Apache Hadoop フレームワークの主要コンポーネントです。これはコンピュータのクラスタ全体で大量のデータを並列処理するように設計されており、「map」と「reduce」という2つの主要なステージで構成されています。以下は、MapReduce のプログラミングモデルの概要です:
MapReduce のコンポーネント
- Map:このステージでは、入力データはチャンクに分割され、複数の map のタスクによって並列処理される。各 map のタスクは入力データの一部を受け取り、ユーザー定義のmap関数を適用して、中間出力としてキーと値のペアを生成する。
- シャッフルとソート:次に、map のタスクによって生成された中間的なキーと値のペアは、そのキーに基づいてソートされ、グループ化される。このステップは、同じキーに関連するすべての値が一緒にされることを保証する。
- reduce:この段階では、ソートされた中間的なキーと値のペアは、複数の reduce のタスクによって処理される。各 reduce のタスクは、同じキーを持つキーと値のペアのグループを受け取り、ユーザー定義の reduce関数を適用して最終的な出力を生成する。
- 出力: reduce のタスクの最終出力は収集され、HDFS または他の指定された出力場所に保存される。
MapReduce のプログラミングモデルは、分散データ処理のための高レベルな抽象化を提供し、デベロッパーは並列でスケーラブルなデータ処理ジョブを簡単に書くことができます。また、クラスタのリソースを効率的に利用することができ、データのパーティショニング、分散、フォールトトレランスといった様々な側面を扱うことができます。
ビッグデータ処理における HDFS 活用のベストプラクティス
ビッグデータ処理における HDFS のベストプラクティスは、ストレージの最適化、フォールトトレランスの確保、パフォーマンスの向上、他のテクノロジーとの統合の活用があります。
1.データの保存と整理:
- データを管理しやすい小さな塊に分解し、効率的に処理する
- 適切なファイルフォーマット、圧縮技術、データ分割戦略を活用する
- ワークロードの特性に基づいてブロックサイズとレプリケーション係数を最適化する
2.フォールトトレランスとデータリカバリ
- Namenode の HA(高可用性)を設定することで、高可用性を確保する
- メタデータの定期的なバックアップとセカンダリNamenode のメンテナンスをする
- データ複製とデータ耐久性確保のための戦略を実施する
3.データの局所性の最大化
- HDFS クラスタ内でデータと計算を近接させることの重要性
- データ配置を最適化し、ネットワーク転送とデータフローを削減する
- HDFS のブロック配置ポリシーを利用してデータの局所性を確保する
4.セキュリティとアクセスコントロール
- 認証や承認などの、強固なセキュリティ対策の導入
- 保存と転送時に、データ保護 のために HDFS の暗号化を活用する
- データへの不正アクセスを制限するためのアクセス制御ポリシーを確定する。
5.監視とメンテナンス
- Cloudera Manager などの強固な監視ツールを使って、HDFS のクラスタの健全性とパフォーマンスを監視する
- HDFS クラスタの健全性とパフォーマンスを定期的に監視して評価する
- ガベージコレクションやログローテーションなど、定期的なメンテナンスタスクを実行する
6.ビッグデータのエコシステムとの統合
- HDFSと、MapReduce、YARN、Pig、Hiveといった他の Hadoop のエコシステムのコンポーネントとの統合を探る
- 高度なデータ処理のために Apache Spark や Apache Kafka のような補完的なツールを活用する
- 分散処理に適しており、HDFS に保存されているデータの規模と複雑さを効果的に処理できるデータマイニングアルゴリズムを選択する
- データの取り込みと外部システムとのデータ交換に対応する HDFS の役割を理解する
データ処理と変換のための ETL ツールとの統合
HDFS が ETL(抽出、変換、格納)ツールと統合されると、効率的なデータ処理と変換ワークフローができるようになります。ここでは、HDFS と ETL ツールの統合がビッグデータ環境におけるデータ処理と変換をどのように強化するかについて見ていきましょう:
-
データの保存とアクセシビリティ: ETL ツールは HDFS に保存されたデータにシームレスにアクセスできるため、データの移動やレプリケーションが不要になる。
-
分散処理: Hadoop の分散コンピューティング機能を活用してデータを並列処理し、パフォーマンスが上がり、より高速なデータ変換が実現する。
-
スケーラビリティ:HDFS を ETL ツールと組み合わせることで、組織は大規模なデータをスケーラブルに処理および変換することができる。
-
データの抽出と格納: 様々なソースからデータを抽出および変換し、HDFS や他のターゲットシステムに格納する。
-
データの変換とエンリッチメント: 価値あるインサイトとダウンストリーム分析のために、HDFS 内のデータに対して複雑な変換をできるようにする。
-
データ品質とガバナンス: HDFS と統合された ETL ツールは、データ品質とガバナンスのコンプライアンスを保証する。
- ワークフローオーケストレーション: データワークフロー内の Hadoop のタスクをシームレスにオーケストレーションする。
HDFS のよくある課題
HDFS はビッグデータ処理とストレージのための強力なツールですが、組織が対処しなければならない課題もいくつかあります。ここでは、HDFS に関連するよくある課題を3つご紹介します:
-
スケーラビリティとパフォーマンス:データ量が増えるにつれて、スケーラビリティと最適なパフォーマンスの確保が不可欠になる。数千のノードとペタバイトのデータを持つ大規模な HDFS クラスタを管理するには、慎重な設定、ロードバランシングや監視が求められ、非効率なデータ分散、ネットワークのボトルネック、ハードウェアの制限は、全体のパフォーマンスに影響を与える可能性がある。
-
セキュリティとアクセスコントロール:HDFS には元々強固なセキュリティメカニズムはなかったが、最近のバージョンでは暗号化、認証、認可などの機能が導入されている。しかし、アクセスコントロールの実装と管理、安全なデータ転送の確保、既存の認証フレームワークとの統合が難しいことがあり、組織は、機密データの保護のために、セキュリティ機能の慎重な設定および監視が必要。
- データの一貫性と信頼性:HDFS は複数のノードにデータを複製することでフォールトトレランスを提供するが、レプリカ間でデータの一貫性の確保や、データの書き込み、更新、読み込み中の同期の管理が難しい場合がある。分散環境では、ネットワークのパーティションやノード障害などの問題がデータの信頼性に影響を与える可能性があり、組織は、データの整合性の維持のために、適切な整合性モデルと監視メカニズムの実装が必要。
このような課題に対処するには、技術的な専門知識、適切な計画、継続的な監視の組み合わせが必要であり、組織は熟練の管理者、強固な監視ツール、HDFS 管理のベストプラクティスへの投資をすべきです。定期的なパフォーマンス調整、セキュリティ監査、データの整合性チェックは、このような課題を克服し、ビッグデータ処理とストレージのための HDFS の円滑な運用を確保するのに必要ですからね。
HDFS 実装の主な考慮事項
HDFS(Hadoop分散ファイルシステム)を導入する際には、導入を成功させるために以下の重要な考慮事項を頭に入れておくことが非常に重要です:
-
ハードウェアとソフトウェアの要件: HDFS の設定前に、ストレージ容量、ネットワーク帯域幅、インメモリ、処理能力などのハードウェアインフラを慎重に評価します。さらに、シームレスな統合と最適なパフォーマンスを確保するために、適切な Hadoop の ディストリビューションと互換性のあるソフトウェアコンポーネントを選択しましょう。
-
キャパシティ・プランニングとデータ管理:予想されるデータ量と増加に対応するには、適切な容量計画が不可欠。必要なストレージ容量を決めるべく、データの取り込み率、更新頻度、データ保持期間を評価し、ストレージ効率を最適化してデータ検索をしやすくすべく、データ複製、パーティショニング、圧縮、アーカイブなどの要素を考慮しましょう。
- バックアップとディザスタリカバリ: データの完全性を保護し、ビジネスの継続性を確保することが優先されるべきであることから、二次的なストレージやリモートのロケーションに定期的にデータをバックアップし、強固なバックアップ戦略を確立します。バックアップ頻度、データ保持ポリシー、リカバリ手順を定め、災害やデータ損失から保護しましょう。
このような点を考慮することで、HDFS の導入をスムーズに成功させることができます。必ずハードウェアとソフトウェアの要件を評価し、容量とデータ管理を計画し、弾力的で効率的な HDFS 環境のために信頼できるバックアップとディザスタリカバリの戦略を確立しましょう。
まとめ
結論として、HDFS はビッグデータの処理とストレージにおいて重要な役割を果たし、それによってスケーラビリティ、フォールトトレランス、分散コンピューティング機能が提供されます。また、ETL ツールとの統合により、データ処理と変換ワークフローが強化され、組織はデータから価値あるインサイトを引き出すことができます。
また、デベロッパーはプログラムで HDFS とやりとりできる API も得られ、その API は、ファイルやディレクトリの作成、読み込み、書き込み、削除などのリアルタイム操作を実行するための関数やメソッドのセットを提供します。デベロッパーは HDFS の API を利用することで、リアルタイムのデータ処理とストレージ機能をアプリケーションに統合し、Apache Hadoop の分散性を活用して効率的でスケーラブルな処理を行うことができるのです。
そこで、Integrate.io のような ETL ツールと共に HDFS を導入することで、企業はスケーラビリティとパフォーマンスの課題を克服し、データの一貫性と信頼性を確保し、分散型コンピューティングのパワーを活用することができます。ハードウェアとソフトウェアの要件への対処、キャパシティ・プランニングの実行、バックアップとディザスタリカバリの戦略の確立をすることで、企業はデータ駆動型プロジェクトのために HDFS の可能性を最大限に活用することができるのです。
HDFS と ETL に足を踏み入れる際には、 Integrate.io の以下のような「データチームと事業部門ユーザーのためのコード不要のデータパイプラインプラットフォーム」の機能をぜひご検討ください。
- HDFS やその他のビッグデータ技術とのシームレスな統合
- データパイプラインを自動化し、さまざまなソース間でデータを複製するためのユーザーに優しいプラットフォームを提供する
- ドラッグ&ドロップのインターフェースが提供されていることによって、コーディングの必要性がない
- 幅広いアプリケーションとデータソースに対応している
- ビッグデータ処理をシンプルにし、企業がより良い意思決定を行えるよう支援している
- 追加のハードウェアやスタッフへの投資は不要
HDFS と Integrate.io を組み合わせたデータ駆動型プロジェクトの可能性は見逃せません。今すぐ14日間のトライアルで Integrate.io の機能とメリットをお試しいただき、データ処理とデータ変換を新たな高みへと上げましょう。また、具体的なニーズについてのご相談は、当社のエキスパートにぜひお問い合わせください。ビッグデータ時代を生き抜き、データ資産の価値を最大化するために必要なツールとテクノロジーで、組織を強化しましょう。



