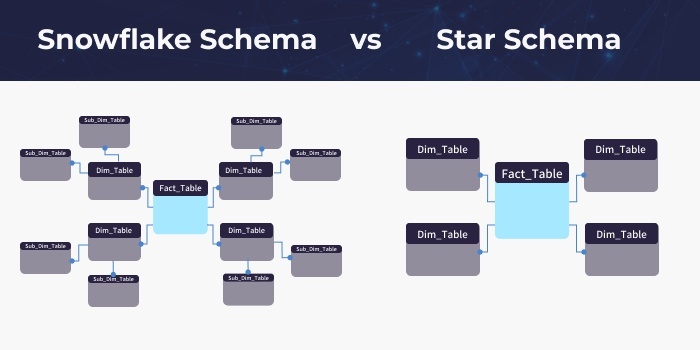

技術主導の世界で企業が情報にますます依存するようになり、データを適切に移動、保存、処理する方法を理解することが年を追うごとに重要になってきています。もしあなたの組織が、会社のデータを整理して処理するためのより良い方法を探しているなら、スノーフレークスキーマ、スタースキーマ、およびこれら2種類のデータウェアハウススキーマの間の関係構成について学ぶ必要があります。
基本的に、スタースキーマは、データウェアハウス内のデータや情報をより効率的に整理する方法を提供します。一方、スノーフレークスキーマはスタースキーマのバリエーションであり、データ処理の効率化を図ることができる。この2つのプロセスは非常によく似ていますが、ユーザーも知っておくべき重要な違いがあります。
スタースキーマとスノーフレークスキーマの比較と、2種類のデータウェアハウススキーマが、企業データの移動、保存、処理、および複雑な分析の完了において、組織の効率をどのように向上させるかについて、このページで詳しく説明しいきます。
Star SchemaとSnowflake Schemaの比較:5つの決定的な違い
- スタースキーマのディメンションテーブルは正規化されていなくても、スノーフレークスキーマのディメンションテーブルは正規化されている点。
- スノーフレークスキーマは、ディメンションテーブルを格納するためのスペースは少なくなるがより複雑。
- スタースキーマは、ファクトテーブルとディメンションテーブルを結合するだけなので、SQLクエリがより単純化され、高速。
- スノーフレークスキーマには冗長データがないため、保守が容易。
- スノーフレークスキーマはデータウェアハウスに適しており、スタースキーマは単純なリレーションシップを持つデータマートに適している点。
基本的に、スタースキーマは、データウェアハウス内のデータと情報を整理する、より効率的な方法をユーザーに提供します。これに対して、スノーフレークスキーマはスタースキーマのバリエーションであり、データ処理に関してより効率的な方法をユーザーに提供します。この2つのプロセスはよく似ていますが、ユーザーが知っておくべき重要な違いもあります。この記事では、まずスタースキーマについて掘り下げ、次にスノーフレークスキーマに移行してそれぞれのニュアンスと比較の利点に光を当てます。
スタースキーマとスノーフレークスキーマの比較について詳しく学び、2つのタイプのデータウェアハウススキーマが、企業データの移動、保存、処理、複雑な分析の完了に関して、組織の効率改善にどのように役立つかを発見するために読み進めてください。
スタースキーマとスノーフレークスキーマについての概要
スタースキーマとスノーフレークスキーマに関しては、その基本的な定義を覚えておくことが不可欠です:
- スター・スキーマ: 単一のファクト・テーブルが複数のディメンジョン・テーブルを参照し、星のようなパターンを形成するデータベース・スキーマの一種。スタースキーマは、データウェアハウスで情報を整理する効率的な方法を提供します。
- スノーフレークスキーマ: ディメンジョン・テーブルが正規化され、複数の関連テーブルが雪の結晶のようなパターンを形成します。スノーフレークスキーマはスタースキーマのバリエーションであり、より効率的なデータ処理を可能にする。
- 正規化: データの冗長性を減らし、データの整合性を向上させるデータベース設計技法。
以上の説明を踏まえて、これらのスキーマの詳細を掘り下げてみよう。
|
スノーフレーク・スキーマ |
スター・スキーマ |
|
|
構造 |
階層的に複数のディメンジョン・テーブルに接続された一元化されたファクト・テーブルで構成されます。 |
スター型構造でディメンジョン・テーブルに接続された一元化されたファクト・テーブルで構成される。 |
|
正規化 |
高度に正規化された設計 |
部分的に非正規化された設計 |
|
クエリ・パフォーマンス |
複雑なクエリおよび集計に最適 |
単純なクエリや集計に優れている |
|
ストレージ効率 |
データの保存効率が高い |
非正規化による効率の低下 |
|
スケーラビリティ |
データの分離により高いスケーラビリティを実現 |
非正規化による拡張性の制限 |
|
データの完全性 |
高いデータ整合性を確保 |
非正規化によるデータ整合性の低下 |
|
複雑性 |
設計と保守がより複雑 |
設計と保守が簡単 |
|
柔軟性 |
データモデルの変更に対して柔軟性が高い |
データモデルの変更に対する柔軟性が低い |
|
用途 |
大規模で複雑なデータウェアハウスに適している |
中小規模のデータ・ウェアハウスに適している |
|
ストレージ・オーバーヘッド |
必要なストレージ容量が少ない |
より多くのストレージスペースが必要 |
どちらのスキーマも、読み取りクエリーや複雑なデータ分析のスピードとシンプルさを向上させます。
スター型スキーマとスノーフレーク型スキーマは類似していますが、データサイエンティストやデータエンジニアが理解しなければならない重要な違いがあります。スノーフレーク・スキーマとスター・スキーマの違いを説明するために、まずスター・スキーマについて詳しく説明します。その後、スノーフレーク・スキーマに移り、その特徴を探っていきましょう。
関連記事:データトランスフォーメーションの解説
スタースキーマとは?
スタースキーマは、データウェアハウスにデータを整理するための最もシンプルな構造を提供します。スタースキーマの中心は、一連の「ディメンションテーブル」のインデックスを作成する1つまたは複数の「ファクトテーブル」で構成されています。スタースキーマ、およびスノーフレークスキーマを理解するには、ファクトテーブルとディメンションテーブルを詳しく見ることが重要です。
スタースキーマの目的は、ビジネスに関する数値的な「ファクト」データを抽出し、記述的な「ディメンション」データから分離することである。ファクトデータには、価格、重量、速度、数量などの情報、つまり数値形式のデータが含まれる。次元データには、色、機種名、所在地、従業員名、販売員名など、数値情報だけでなく、数え切れないほどの情報が含まれる。
ファクトデータはファクトテーブル、ディメンションデータはディメンションテーブルに整理される。ファクトテーブルは、データウェアハウス内のスタースキーマの中心にある統合ポイントです。これにより、機械学習ツールがデータを1つの単位として分析できるようになり、他のビジネスシステムも一緒にデータにアクセスできるようになります。ディメンションテーブルは、データウェアハウスを構成するファクトテーブルを通じて集約された数値データおよび非数値データを保持・管理します。
より技術的な観点からは、ファクト・テーブルは、さまざまなイベントに関連する数値情報を追跡します。例えば、ディメンジョン・テーブルの追加情報 (記述的で数値以外の情報) に対応する外部キーとともに、数値が含まれる場合があります。さらに専門的な話になりますが、ファクト・テーブルは低レベルの粒度 (または "詳細") を維持します。このため、時間の経過とともに、ファクト・テーブル内に多数のレコードが蓄積される可能性があります。
ファクトテーブルの種類
ファクトテーブルには、大きく分けて3つの種類がある。
- トランザクション・ファクト・テーブル:商品の売上など、イベントに関連する情報を記録する。
- スナップショット・ファクト・テーブル:期末の勘定科目など、特定の時点に適用される情報を記録する。
- 累積スナップショット・テーブル:特定の商品または商品カテゴリの年間売上高のように、データの実行集計に関連する情報を記録する。
ディメンションテーブルの種類
しかし、ディメンション・テーブルのレコードには、数値データだけでなく、記述的な属性も含まれます。ディメンジョン・テーブルは、情報システムによってさまざまな種類があります。以下にその例を示す。
- 時間ディメンション・テーブル:異なるイベントが発生した正確な日時、月、年を特定するための情報。
- 地理ディメンジョン・テーブル(Geography dimension tables):住所/位置情報。
- Employeeディメンション・テーブル:住所、電話番号、氏名、社員番号、電子メールアドレスなど、社員や販売員に関する情報。
- Merchandise(商品)ディメンション・テーブル。商品の説明や商品番号など。
- 顧客ディメンション・テーブル:顧客の名前、番号、連絡先、住所など。
- レンジディメンションテーブル:時間、価格、その他の数量の値の範囲に関する情報。
ファクトテーブルとディメンションテーブルの連動性
ディメンション・テーブルには、通常、自然キーに関連する属性に対応する代理の主キー(つまり、1列の整数からなるデータ型)が列挙される。異なる店舗に関連する情報を持つディメンジョン・テーブルがあるとします。「Dim_Store」とします (以下の Star Schema の図を参照)。各店舗にIDナンバーを割り当て、店舗名、サイズ、場所、従業員数、カテゴリなどといった数値以外の関連情報の行を割り当てることができます。これにより、ファクトテーブル (Fact_Sales) のどこに店舗IDナンバーを記載しても、それは 「Dim_Store」ディメンジョンテーブルの店舗データのその特定の行にマッピングされます。
もちろん、スター・スキーマはこれだけにとどまりません。ファクト・テーブルにリンクする情報を持つポイント(またはディメンジョン・テーブル)がさらに存在するからです。例として、2019年8月という時間軸で次のようなことを知りたいとします。
- 何個の製品が購入されたか?
- どのような商品が購入されたのか?
- どの店舗で購入されたのか?
- 購入された製品の名称と住所は?
- 購入された製品はどのようなブランド名で製造されたのか?
- 購入された商品は何曜日に作られたのか?
このようなクエリを実行するには、すべてのディメンション・テーブル(Dim_Date、Dim_Store、およびDim_Product)に含まれるデータにアクセスする必要があります。これらは別々のデータベースですが、統合ポイントとして機能するファクト・テーブルを通じて、1つのテーブルにあるのと同様に、すべてのデータを照会することができます。これが、スタースキーマデータウェアハウスの仕組みです。
スタースキーマの図
次の図は、単純なスタースキーマの様子を示しています。

*画像:SqlPac(英語版ウィキペディア)、CC BY-SA 3.0
ここでは、ファクト・テーブルであるFact_Salesが図の中央に表示されています。そのスキーマには、ID番号のカラムとして、以下のものがあります。Date_Id、Store_Id、Product_Id、Units_Soldです。ファクト・テーブルは統合ポイントとして、ディメンジョン・テーブルの多様な情報を統合します。Dim_Product、Dim_Store、Dim_Dateというディメンション・テーブルの多様な情報を統合します。
このように、スタースキーマは、中心となるファクトテーブル「コア」とディメンションテーブル「ポイント」を持つことから、その名前が付けられました。スタースキーマに多くのディメンションテーブルがある場合、データエンジニアはそれをムカデスキーマと呼ぶことがあります。
スタースキーマにおけるデータの非正規化
スタースキーマの目的は、ソーススキーマが異なる多様なデータベースに含まれる膨大なデータの読み取りクエリや分析を高速化することである。スタースキーマは、ディメンションテーブルのネットワーク内でデータを「非正規化」することで、この目標を達成します。
従来、データベース管理者は、同じデータの重複を排除すること、つまり重複した情報を1つのコピーに正規化することでデータの「正規化」を目指していました。これによって、更新が必要なデータは1つのコピーだけとなり、書き込みコマンドが高速化されました。
しかし、データシステムが複数の次元テーブルに拡張されると、複数のソースからデータにアクセスするため、読み取りクエリや分析が遅くなってしまいます。そこでスタースキーマでは、従来のデータベース正規化のルールを緩和し、データを「非正規化」することで、スピードアップを図ります。
スタースキーマは、ディメンションテーブルからファクトデータ(またはID番号の主キー)を取り出し、この情報を複製してファクトテーブルに格納します。このように、ファクト・テーブルは、すべての情報ソースを結びつけます。これにより、読み取りクエリや分析が限りなく高速化されます。しかし、書き込みコマンドの速度は犠牲になってしまいます。書き込みコマンドが遅くなるのは、更新のたびに「非正規化」されたデータのすべての相手側コピーを更新する必要があるためです。
スタースキーマのメリット
スタースキーマには、次のようなメリットがあります。:
- クエリの簡素化:すべてのデータがファクトテーブルを介して接続されるため、複数のディメンションテーブルが1つの大きな情報テーブルとして扱われ、クエリがよりシンプルで簡単に実行できるようになりました。
- ビジネスインサイトのレポート作成が容易になる点:スタースキーマは、as-of-asレポートや期間別レポートなどのビジネスレポートを作成するプロセスを簡素化します。
- クエリのパフォーマンス向上:高度に正規化されたスキーマのボトルネックを取り除くことで、クエリの速度が向上し、読み取り専用コマンドのパフォーマンスが改善されます。
- OLAPシステムへデータを提供できる点:OLAP (Online Analytical Processing) システムは、スタースキーマを使用して OLAP キューブを構築することができます。
スタースキーマの課題
前述したように、スタースキーマにおける読み取りクエリや解析の改善には、いくつかの課題がある可能性があります。
- データ整合性の低下:データ整合性の低下: データ構造が非正規化されているため、スタースキーマはデータの整合性をあまり強化しません。スタースキーマでは、異常の発生を防ぐための対策がとられていますが、単純な挿入や更新コマンドによって、データの不整合が発生する可能性があります。
- 多様で複雑なクエリに対応不可能:データベース設計者は、特定の分析ニーズに合わせてスタースキーマを構築し、最適化する。非正規化されたデータセットであるスタースキーマは、比較的狭い範囲の単純なクエリにしか対応できません。正規化されたスキーマは、より複雑な分析クエリに幅広く対応できます。
- 非多対多リレーション:スタースキーマはシンプルなディメンションスキーマであるため、「多対多のデータリレーション」には適していません。
スノーフレークスキーマとは?
スタースキーマの仕組みがわかったところで、次は雪の結晶の形をしたスノーフレークスキーマについて考えてみましょう。スノーフレークスキーマの目的は、スタースキーマで非正規化されたデータを正規化することです。これにより、書き込みコマンドの速度低下など、「スタースキーマ」にありがちな問題を解決することができます。
スノーフレークスキーマは 「多次元 」構造です。その核となるのはファクトテーブルで、ディメンションテーブルの情報を結びつけ、スタースキーマのように外側に放射状に広がっていく。ただし、スノーフレークスキーマのディメンションテーブルは、それ自体が複数のテーブルに分割されています。それが雪の結晶のパターンを作り出しているのです。
この「スノーフレーク」手法により、スノーフレークスキーマは、(1)「低カーディナリティ」属性(親テーブルで複数回出現)を取り除き、(2)ディメンションテーブルを複数のテーブルに分割し、ディメンションテーブルが完全に正規化されるまで接続先ディメンションテーブルを正規化します。
自然界の雪片模様のように、スノーフレークのデータベースは非常に複雑になります。スキーマは、子テーブルが複数の親テーブルを持つような、精巧なデータ関係を作り出すことが可能です。
Vertabeloは、スノーフレークスキーマとスタースキーマにおける優れた比較をしました。
「スタースキーマとは異なり、スノーフレークスキーマのディメンションテーブルは独自のカテゴリを持つことができる。スノーフレークスキーマの基本的な考え方は、ディメンションテーブルが完全に正規化されていることです。各次元表は、1つ以上のルックアップテーブルによって記述される。各ルックアップテーブルは、1つまたは複数の追加のルックアップテーブルによって記述することができます。これをモデルが完全に正規化されるまで繰り返す。スタースキーマのディメンジョン・テーブルを正規化するプロセスは、スノーフレーキングと呼ばれます。
スノーフレーク・スキーマの図
スノーフレークの概念を深く理解する前に、スノーフレークスキーマの図解を見ておきましょう。
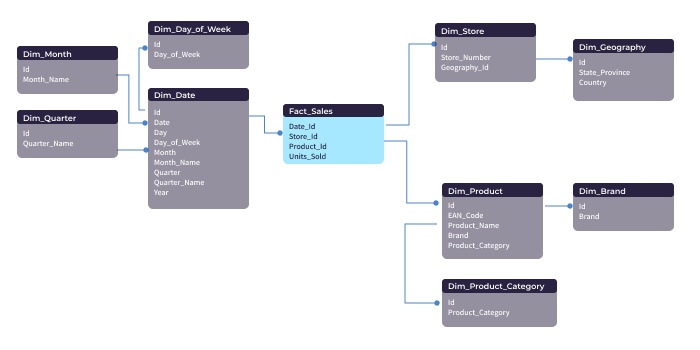
画像出典:SqlPac at English Wikipedia, CC BY-SA 3.0.
上の図は、スターテーブルの例で各ディメンジョンテーブルを外側に「雪だるま式」に配置しているのがお解りでしょうか?Dim_Productディメンジョン・テーブルを検証してみましょう。Dim_Productテーブルのさまざまな列が雪だるま式に外側に広がり、ルックアップ・テーブルになっていることがわかります。
スタースキーマの例では、Dim_Productにブランドの非数値名が含まれていました。現在では、Dim_Brand 検索テーブルを指す Brand_Id 番号が含まれているだけです。Dim_Productテーブルをこのように数値に変換することで、システムがクエリを処理する速度が向上します。さらに重要なことは、データの保存に必要な容量を削減できることです。Dim_Productテーブルには、ブランドのフルネーム(Brand_Idの数値と比較すると長いデータ列です)の複数のエントリが含まれなくなるためです。
要するに、数値は、記述された名前や定性的な記述値よりも、処理に必要なスペースと時間を劇的に削減することができるのです。したがって、ディメンション・テーブルをルックアップ・テーブルに分離することで、数百万行・数列のデータを処理する際のストレージ・コストを大幅に削減することができます。
大量のデータを扱っている場合、そのデータをどのように移動させ、どのように可視化するかという古くからの問題を解決しようとしているのではないでしょうか。Integrate.io の 14日間の無料トライアルを開始したら、当社のチームとのミーティングを予約して、当社の強力な ETL ツールを使用して、システム全体でデータを簡単にプッシュ/プルできる方法を学んでください。
スノーフレークスキーマのメリット
スノーフレークスキーマは、通常のスタースキーマと比較して、以下のようなメリットがあります
- 多くのOLAPデータベースモデリングツールと互換性がある:データサイエンティストがデータ分析やモデリングに使用する一部のOLAPデータベースツールは、スノーフレークデータスキーマに対応するよう特別に設計されています。
- データストレージを節約可能:スタースキーマでは通常非正規化されるデータを正規化することで、必要なディスクスペースを大幅に削減することができます。これは、非数値データの長い文字列(記述子や名前に関する情報)を、ストレージの観点で劇的に負荷の少ない数値キーに変換するためです。
スノーフレークスキーマの課題
スノーフレークスキーマに関する課題としては、以下の3つが考えられる。
- 複雑なデータスキーマ:ご想像のとおり、スノーフレークスキーマはスタースキーマの属性を正規化する一方で、 多くのレベルの複雑さを生み出します。この複雑さにより、ソースクエリの結合がより複雑になります。より効率的なデータ保存方法を提供するため、snowflake はこのような複雑な結合をブラウズしている間にパフォーマンスを低下させる可能性があります。しかし、処理技術の進歩により、近年ではスノーフレークスキーマのクエリ性能は向上しており、スノーフレークスキーマの人気が高まっている理由の一つになっています。
- キューブデータの処理速度が遅さ:スノーフレークスキーマでは、複雑な結合を行うため、キューブデータの処理速度が遅くなります。一般に、スタースキーマはキューブデータの処理に適しています。
- データ整合性レベルの低下:スノーフレークスキーマは、正規性が高く、UPDATE および INSERT コマンドの実行後にデータが破損するリスクは低いですが、従来の高度に正規化されたデータベース構造で得られるような、国境を越えた保証のレベルは提供されません。したがって、スノーフレークスキーマにデータをロードする場合は、ロード後の情報の品質を慎重に確認することが重要です。
関連記事:2024年版ビジネスインテリジェンスツールTOP17
Integrate.ioの活用方法
Integrate.io の自動 ETL (抽出、変換、ロード) ツールは、ほぼリアルタイムでデータウェアハウスにデータをシームレスにロードすることを支援します。当社のETLツールを使用すれば、複雑なETL機能を実行するための高度なスキルを持つデータチームが不要になります。これにより、データの損失や破損を防止しながら、データをデータウェアハウスに統合する際の時間と人件費を節約することができます。
Integrate.io とそのプラットフォームが提供する何百もの簡単ですぐに使えるデータ統合の詳細については、当社のホームページをご覧ください。また、無料デモについてはIntegrate.ioチームまで。




