


ビッグデータ市場は2030年までに4740億ドル規模になると専門家は予測しており、それであらゆるタイプの企業にとってデータが非常に価値のあるものであるということがわかります。ただし、適切なデータを集めてそれを解釈し、インサイトに基づいて行動する企業の能力で、データプロジェクトの成功が左右されるでしょう。
企業がアクセスできるデータ量は増加し、利用可能なデータの種類も増えています。ビジネスデータは、厳密に形成されたリレーショナルデータベースから SNS への投稿まで、多種多様な形式で提供されており、そのデータは、その形式を問わず「構造化データ」と「非構造化データ」の2つに大きく分けることができます。
構造化データと非構造化データの主な違い
- 構造化データとは、標準化されて明確に定められ、検索ができるようになっているデータのことで、非構造化データは通常、本来の形式で保存されている。
- 構造化データは定量的であり、非構造化データは定性的である。
- 構造化データはデータウェアハウスに、非構造化データはデータレイクに保存されることが多い。
- 構造化データは検索や分析をしやすい、非構造化データは処理や理解に手間がかかる。
- 構造化データはあらかじめ定められたフォーマットで存在し、非構造化データはさまざまなフォーマットで存在する。
構造化データは扱うのが非常に簡単ですが、非構造化データはより複雑で、整理や抽出が構造化データより難しいです。そこで本記事では、このデータタイプとその違いについて詳しく見ていきます。
構造化データとは
構造化データとは、ファイルやレコード内の固定フィールドに存在するデータを指します。大体リレーショナル・データベース(RDBMS)に格納され、数値やテキストで構成されています。また、ソーシングは、RDBMS の構造内にある限りは自動でも手動でも可能です。それはどのようなデータモデルを作成するかによって異なることから、それでどのようなタイプのデータを含めるかや、そのデータをどのように保存および処理するかが確定します。
構造化データに使われるプログラミング言語は SQL(Structured Query Language)です。 SQL は1974年に IBM によって開発されたものであり、リレーショナル・データベースを扱い、高度なコーディング・スキルを必要としません。そして 構造化データの典型的な例には、名前、住所、クレジットカード番号、数値データ、Microsoft Excelファイル、テキストファイルなどがあります。
非構造化データとは
非構造化データとは、多かれ少なかれ、構造化されていないデータ全てを言います。非構造化データにはネイティブな内部構造があるかもしれませんが、あらかじめ定められた方法で構造化されているわけではありません。また、データモデルは存在せず、データは本来の形式で保存されます。
非構造化データの典型的な例としては、リッチメディア、ショートメール、SNS活動、ビデオファイル、オーディオファイル、監視画像、その他様々なファイル形式があります。
非構造化データの量は、構造化データよりもはるかに多く、非構造化データは企業データ全体の実に8割以上を占め、その割合は増え続けています。つまり、非構造化データを考慮していない企業は、多くの貴重な BI(ビジネス・インテリジェンス)を逃していることになります。
半構造化データとは
半構造化データは、上記の2つの間に位置する第3のカテゴリーです。構造化データの一種で、リレーショナル・データベースの正式な構造には当てはまりませんが、構造化データの説明には完全に合致しないものの、タグ付けシステムやその他の識別可能なマーカーを採用し、さまざまな要素を分離して検索をできるようにしています。また、非構造化データは、自己記述構造を持つデータとして知られることもあります。
スマートフォンの写真は、半構造化データの典型的な例です。スマートフォンで撮影された写真には、全てタグ付けされた時間、場所、その他の識別可能な(構造化された)情報だけでなく、非構造化画像コンテンツが含まれています。また、半構造化データフォーマットには、JSON、CSV、XML のファイルの種類が含まれます。
構造化データ と 非構造化データ を並べて比較
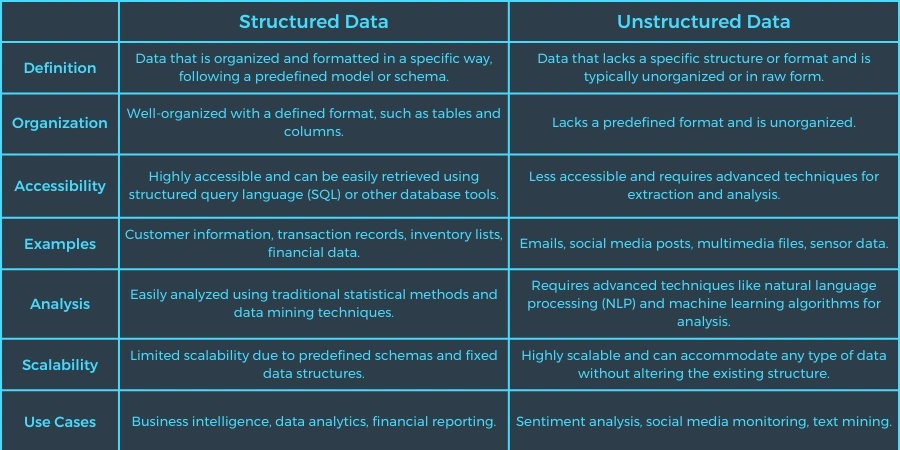
構造化データ と 非構造化データ: 5つの主な違い
構造化データと非構造化データの主な違いを5つ見てみましょう:
1.定義済みデータ と 未定義データ
構造化データとは、明確に定められた構造のデータです。非構造化データは、通常そのままの形式で保存されますが、構造化データは行と列の中に存在し、あらかじめ定められたフィールドにマッピングすることができます。
また、リレーショナル・データベースで整理してアクセスできる構造化データとは違い、非構造化データには事前に定められたデータモデルがなく、未定義です。
2.定性的データ と 定量的データ
構造化データと非構造化データのもう 1 つの違いは、構造化データは多くの場合定量的なデータであることです。つまり、構造化データは通常、例えば、CRM(顧客関係管理システム)の製品情報など、具体的な数字や数えられるもので構成されます。分析の手法には、回帰(変数間の関係予測)、分類(確率の推定)、(さまざまな属性に基づく)データのクラスタリングなどがあります。そしてデータ・サイエンティストやその他のデータ・アナリストは、このような手法を使って、組織のビジネスインサイトを生み出すことができます。
一方、非構造化データは定性データに分類されることが多く、従来のツールや手法では処理や分析はできません。ビジネスのコンテクストでは、質的データは、例えば顧客調査、インタビュー、SNS とのやり取りなどから得られ、定性データからインサイトを引き出すには、データマイニングやデータスタッキングのような高度な分析技術が必要です。
3.データウェアハウスとデータレイクにおけるデータの保管
企業は多くの場合、構造化データはデータウェアハウスに、非構造化データはデータレイクに保存します。データウェアハウスは、ETL パイプラインを通るデータが最終的に行き着くところであり、対するデータレイクは、ほぼ無限のレポジトリのようなもので、データは元のフォーマットで、あるいは基本的な「クリーニング」プロセスを経た後に保存されます。
構造化データも非構造化データも、クラウド利用の可能性を秘めています。その際に構造化データはストレージ容量が少なくて済みますが、非構造化データにはより多くの容量が必要です。
そしてデータベースに関しては、構造化データは通常リレーショナル・データベースに格納されますが、非構造化データには、いわゆる非リレーショナル(NoSQL)データベースが最適です。
4.分析しやすさ
構造化データと非構造化データの最も大きな違いの1つに、構造化データがいかに分析に適しているかという点があります。構造化データは、データ分析の専門家にとってもアルゴリズムにとっても検索がしやすく、対する非構造化データは本質的に検索が難しく、理解できるようなデータにするのに処理が必要です。
構造化データ用の高度な分析ツールは豊富にありますが、非構造化データのマイニングや整理のための自然言語処理(NLP)や機械学習アルゴリズム(ML)など、ほとんどの分析ツールはまだ開発段階にあります。
5.定義済みフォーマット と 多様なフォーマット
構造化データの最も一般的なフォーマットは、テキストと数値であり、構造化データはあらかじめデータモデルで定義されています。
一方、非構造化データにはさまざまな形や大きさがあり、音声、ビデオ、画像からメールやセンサーデータまで、あらゆるもので構成されます。また、非構造化データにはデータモデルがなく、ネイティブに保存するか、変換を必要としないデータレイクに保存されます。
非構造化データを管理すべき理由
大抵の企業はデータのバックアップをとっていますが、現在の推計によると、ビジネス関連のデータは年々増加しており、データストレージが課題となっています。ビジネスデータはほとんど「クール」データ(30日間アクセスされていないデータ)であり、それで高価なハードディスクはぎゅうぎゅうになり、ストレージのコストが上がります。
企業の大多数は、特に非構造化データの管理で大変な思いをしています。非構造化データはインデックス付けが難しく、XML、キーバリュー、JSONデータベースはそのようなデータを分析するようにはデザインされていないからであり、非構造化データの抽出、分析、処理のプロセスは通常、セカンダリ・システムに委託されます。
データを移動させると、さらにストレージが必要になり、経済的に賢明ではないのです。
企業によっては非構造化データをまったく管理しないというのもあり、その代わりに、プライマリー・ストレージ・システムの容量を拡張します。ただし、この方法には問題があり、以下のようにコストがかかります:
- まず、非構造化データはプライマリストレージを消費する。プライマリストレージには通常、高価なフラッシュドライブが必要なため、それが最も高価になる可能性がある。
- 第二に、企業は3年から5年ごとにストレージ・インフラを更新しなければならず、このプロセスには、クールな(30日アクセスがない)非構造化データも全て含まれる。また、移行コストやバックアップに必要なセカンダリストレージについても考慮が必要。
- 第三に、グローバルなデータガバナンス法によって、企業が非構造化データの中に何が保持されているのか、そしてそれが個人を特定できる情報を含んでいるのかどうかを正確に把握することが求められる。
非構造化データを効率的に管理すれば、パフォーマンスの最適化や、コスト削減が実現し、クラウド、テープ、またはセカンダリストレージソリューションを選択することで、非構造化データの管理がしやすくなります。
まとめ
データには主に、構造化データと非構造化データの2つのカテゴリーがあり、(名前、住所、クレジットカード番号などの)構造化データは、あらかじめ定めれたモデルやフォーマットで保存され、(オーディオ、ビデオ、監視データなどの)非構造化データは、分析のために抽出されるまで、本来のフォーマットで保存されます。また、半構造化データというものもあり、これは、何らかのタグ付け構造がありますが、リレーショナルデータベースの正式な構造にはまだ当てはまらないデータを指します。
本記事では、構造化データと非構造化データの以下の5つの重要な違いについて見てきました:
- 定義済みデータと未定義データ
- 定性的データと定量的データ
- データハウス か データレイク での保存
- 分析の難易度
- 定義済みフォーマット vs 多様なフォーマット
構造化データはビッグデータ・プログラムにとって処理しやすいですが、非構造化データや半構造化データを忘れてはいけません。非構造化データの分析には、より大きな課題がありますが、全企業データの8割以上がこのカテゴリーに属しており、年間55~65%の割合で増加していることを考えると、このカテゴリーを省くことは大きな盲点を生むことになります。ただ幸いなことに、テクノロジーの進化に伴い、非構造化データに隠されたインサイトにアクセスしやすくなっています。
本記事では、構造化データと非構造化データの5つの重要な違いについて見てきましたが、要約すると、(名前、住所、クレジットカード番号などの)構造化データはあらかじめ定められたモデルやフォーマットで保存され、(音声、ビデオ、監視データなどの)非構造化データは分析のために抽出されるまで本来のフォーマットで保存されます。またその他にも、2つの中間に位置するカテゴリーとして、半構造化データもあり、これは、何らかのタグ付け構造がありますが、リレーショナルデータベースの正式な構造にはまだ当てはまらないデータを指します。
構造化データと非構造化データでIntegrate.io ができること
Integrate.io は、コーディングやデータエンジニアリングの経験に関係なく、誰もがデータを管理できるようになるべきだと考えています。このコード不要のデータパイプラインプラットフォームで、構造化、非構造化、半構造化データをデータウェアハウスやデータレイクのような中央レポジトリに、難しい作業をすることなく簡単に移動させることができます。
また、Integrate.io には、ETL、ELT、リバースETL、CDC パイプラインを構築するための完全なツールキットがあり、それによってデータのソース、正しいフォーマットへの変換、目的の場所への移動がしやすくなります。
さらに、Integrate.ioのワークフローエンジンを使うと、構造化および非構造化データをビジネス要件に基づいた場所に移動するデータパイプラインをオーケストレーションし、スケジュールすることができます。そして、豊富な表現言語により、複雑なデータ準備関数の実装や、他のデータレポジトリやアプリケーションとの統合が実現します。
Integrate.io にはその他にも以下のような利点があります:
- ワールドクラスのカスタマーサービス
- オンラインサポート
- REST API によるカスタムコネクタの構築
Integrate.io でどのように構造化データや非構造化データの管理と統合ができるか体験してみませんか?早速デモを予約して、高度なコードやデータエンジニアリングなしで、データソースからさまざまなデータタイプを移動しましょう。
Q&A
Q. 構造化データと非構造化データとは何ですか?
A. 構造化データは標準化され、検索可能で、多くの場合はリレーショナル・データベースに保存されます。対する非構造化データは、そのままの形式で保存されるため、処理と理解に手間がかかります。
Q. 構造化データと非構造化データは分析上どのように違いますか?
A. 構造化データは標準的な手法で検索や分析がしやすいですが、非構造化データを処理してインサイトを引き出すには高度な分析技術が求められます。
Q. 構造化データと非構造化データは通常どこに保存されるのでしょうか?
A. 構造化データは通常データウェアハウスに保存され、非構造化データはデータレイクに保存されます。
Q. 企業にとって非構造化データを管理する意義とは?
A. 非構造化データを管理することで、企業は膨大な量の情報からインサイトを得ることができ、それが十分な情報に基づいた意思決定や競争力の維持に欠かせないものとなります。
Q. Integrate.io は、構造化データと非構造化データのビジネスをどのように支援できるのでしょうか?
A. Integrate.io で、高度なコーディングスキルを必要とすることなく、データの管理と統合がシンプルになり、中央レポジトリに両方のタイプのデータを移動するためのノーコードプラットフォームが得られます。




