
データは新しい燃料です。ほぼすべての産業でデータ駆動化が進んでおり、その傾向は今後ますます強まるでしょう。多くの組織が意思決定のためにデータに依存するようになった今、データパイプラインを通じた情報への簡単なアクセスや分析が求められています。そこで本記事では、独自のデータパイプラインを構築する方法についてみていきましょう。
データパイプラインの概要
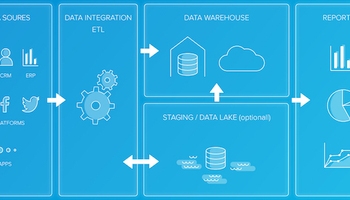
まずは、データパイプラインが何をするものであるかについて理解しましょう。多くの企業はパイプラインが必要だと考えていますが、それの何がいいのか、どこから構築すればよいのかさえわかっていません。パイプラインは、生の情報を分析や意思決定に役立つものに変えることを主な目的としており、すべての従業員が必要なときにアクセスできるように、会社の重要なデータを整理して保存することもできます。
組織ごとにニーズが異なるため、同じパイプラインは2つとありません。なのでこのガイドでは、可能な限りシンプルさを維持しながら、様々なユースケースをカバーすることを目指しています。本記事では、パイプラインをサッときちんと立ち上げるべくゼロからすべての問題に取り組むのではなく、パイプラインの簡単な作成のために特別に作られたツールを重点的に見ていきます。
データパイプラインの種類
パイプラインの種類に行く前に、『ストリーミング』と『バッチ』の2種類に大別されることを理解しておく必要があります。この2つのパイプラインは、データの出どころ、つまり、「リアルタイムのストリーム」か、「時間をかけて収集された大きな情報の塊(バッチ)」という点での違いがあります。
ストリーミングパイプライン
ストリーミング・パイプラインは、データをサッと分析し、その結果をリアルタイムで送信するのに最も有効です。数時間や数日遅れて受け取るのではなく、「今この瞬間」にしか得られないインサイトを提供できるため、モニタリング目的でよく利用されます。例えば、JavaScriptのスニペットを使ってウェブサイトの訪問者を追跡し、訪問者がサイト上の各ページに移動するたびに、その数値を解析プログラムに送信します。正しく実行されれば、ユーザーのセッションは、すべてあなたのドメインに入った直後に追跡されることになります。つまり、ユーザーがオンラインで何を行い、何人がそれを行っているかということに遅れが生じないのです。
バッチパイプライン
スピードよりも時間的な正確さを重視するのであれば、バッチパイプラインの方が適しているかもしれません。例えば、「顧客データをデータベースに保存しておいて、必要なときに簡単にアクセスできるようにすることができる」といったように、将来のために情報を保存しておきながら、必要なときに素早く分析したいという場合に理想的です。これにより、効率的な保管が可能になると同時に、各ユーザーが次にログオンするまで待つことなく、要求に応じて最新の情報を入手することができます。
データパイプラインが必要な理由
データ・パイプラインは、ビジネスに不可欠な情報を一箇所に集めるのに最適な方法であることから、企業にはデータパイプラインが必要です。例えば、【営業部門】、【マーケティング部門】、【財務部門】、【製造部門】がそれぞれ、継続的に連絡を取り合う相手の連絡先リストを別々に管理しているとしたらどうでしょう。その場合、個別のスプレッドシートが多数存在するため、共通の顧客やベンダーを見つけるのは大変です。すべてが一箇所に集まってなければ、従業員は、収益を上げるようなより緊急性の高い案件に集中するよりも、必要なものを見つけるために何十冊ものファイルを探すのに貴重な時間を奪われてしまう他ないのです。
全体の計画の一部として達成したい「特定の目標」に関連付けられたレポートを作成する場合も、同じ概念が当てはまります。もし、必要なデータが別々の場所にあれば、現状を正確に把握することはできませんが、データパイプラインは、すべての関連情報を一箇所に集め、必要なときにいつでも簡単にアクセスできるようにすることで、この問題を解決します。
データベースや分析プラットフォームにデータを抽出、変換、格納するETL計画を作成しよう
ETL計画は、すべてをスムーズに実行するのに必要なさまざまなタスクを文書化するため、ETL計画で、より信頼性の高いデータパイプラインを作成しやすくなります。また、各ステップを確実に評価することで、ミスをなくし、納期が迫っているときにコストのかかる遅延を引き起こしたり、信頼性の低い結果で顧客やパートナーからの評判を損ねることがないようにします。
『抽出』のステップでは、ソースからデータを取り出し、ステージングエリアに読み込みます。『変換』ステップでは、情報をクレンジングし、最終目的地にすべてを『格納』する前に、後で問題を引き起こす可能性のあるエラーや欠落が確実にないようにします。これは、スプレッドシート、データベース、Hadoop cluster、その他の分析プラットフォームのいずれであっても同じことです。
『変換』のステップは、多くの情報を含む大規模なデータセットでは時間がかかることがあります。これでは、収集した全データから機械学習アルゴリズムを使って隠れたパターンを発見する際に、信頼性の低い結果を招くことになるため、このステップは確実に毎回徹底的に行うようにしましょう。それでも、質の悪いデータや不正確なデータを分析プラットフォームに『格納』することはできないので、この作業は不可欠な部分です。
『格納』のステップは、レポート作成や機械学習モデルのトレーニングを開始するために、すべてをプラットフォーム内に取り込むところです。処理する情報の量にもよりますが、複雑なパイプラインの場合、このステップにかなりの時間がかかる可能性があります。
効率的に処理したいデータ量に対応できるツールを選択しよう
現在、ほとんどの種類のデータを扱うことができる多くの選択肢が市場に出回っています。しかし、丸い穴に四角い釘をはめ込もうとするのではなく、ニーズに合ったものを選ぶことが肝心です。つまり、将来的に大きな変更を必要とせずに成長できるような柔軟性のあるものを見つけること、そして物事をより複雑にするような追加機能を選択する前に、すべての内蔵機能を活用するということです。また、多くのツールには初心者向けのトレーニングプログラムも用意されており、実例をもとにした現実的なベンチマークやタイムラインなど、初日から成功するためにどうすればよいかを関係者全員が理解できるようになっています。
Integrate.ioは、費用のかかるIT専門家を雇ったり、不格好なソフトウェアをコンピュータにインストールする必要はなく、あらゆる種類の情報を扱うことができるデータ管理ツールです。また、使い方が簡単なので、初心者や、ダウンタイムのない、よりシームレスなプロセスを求める人にも最適です。
Integrate.io は、クラウドサーバー、Google Cloud Platformのアカウント、Amazon AWSのストレージコンテナ、FTP サーバー、MySQL などのJDBC 対応データベース など、ほぼどこからでもデータを読み込むことができます。生のウェブ解析、ウェブサイトのフォームやeコマースの注文、Twitterフィード、Facebookの更新/いいね、LinkedInメッセージなどのSNS活動、さらには電話やメールによるカスタマーサービスのやり取りまで、あらゆるものを追跡・分析できるため、ビジネスが顧客にどう受け止められているかを理解できるようになります。
初心者の方にも簡単にお使いいただけると同時に、経験豊富なユーザーにも十分な機能を提供していることから、柔軟なソリューションをお探しの場合に理想的な選択です。さらに、Integrate.ioは100以上の組み込みコネクタを使えるため、あなたのビジネスが必要とするあらゆるデータソースやデスティネーションと統合することができます。
Integrate.ioができること
まとめると、データパイプラインを構築するには、考慮すべき重要なステップがいくつかあるということです。このガイドが、データパイプラインの強固な基盤を作るのに必要なことをより良く理解するのにお役に立てれば幸いです。Integrate.io がどのようにデータの格納と分析をお手伝いするかについては、ぜひこちらまでお気軽にお問い合わせください。