
昨今、企業は例えばデータベース、Web サイト、SaaS(サービスとしてのソフトウェア)アプリケーション、分析ツールなど、これまで以上に多くのデータソースと形式にアクセスできます。
ただ残念ながら、企業がこのデータを保存する方法によっては、その中に隠された貴重なインサイトを抽出するのは、特に、よりスマートなデータ主導のビジネス上の意思決定に必要な場合は大変になります。
Google Analytics や Mixpanel のような標準的なレポーティングソリューションは使えますが、データ分析のニーズが容量を超える時が来ます。
その時点で、データ統合レイヤーを基盤とするカスタム BI(ビジネスインテリジェンス)ソリューションの構築を検討することになるでしょう。
1970年代に登場した ETL は、現在でも企業のデータ統合に最も広く利用 されている手法です。でも ETL とは一体何であり、どのように機能するのでしょうか。
そこで本記事では、ETLとは何なのか、そして組織はにどのような恩恵をもたらすことができるのかについて掘り下げていきます。
ETL とは
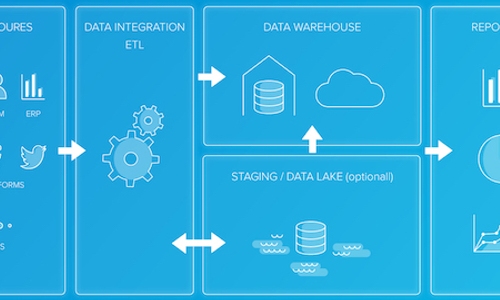
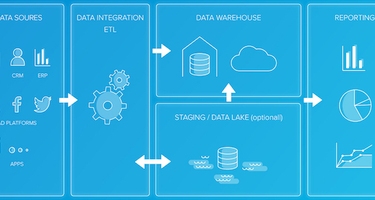
ETLとは、抽出(Extract)、変換(Transform)、格納(Load)の頭文字をとった、この3つのステップを指し、ETL が、さまざまなソースからデータを集めて単一のデータストア(データウェアハウスやデータレイクなど)に処理することで、分析がよりしやすくなります。
このセクションでは、抽出、変換、格納の各プロセスを詳しく見ていきましょう。
抽出(Extract)
データの抽出とは、1つ以上のデータソースからデータを取り出すことです。
このフェーズでは、以下のような様々なデータソースを扱う可能性があります:
-
リレーショナルデータベースおよび非リレーショナル データベース
-
XML、JSON、CSV、Microsoft Excel スプレッドシートなどのフラットファイル
-
CRM(顧客関係管理)や ERP(企業資源計画)システムなどの SaaS アプリケーション
-
API(アプリケーション プログラミング インターフェイス)
-
Web サイト
-
分析および監視ツール
-
システム ログとメタデータ
ETL は、「バッチ ETL」と「リアルタイムETL(所謂「ストリーミングETL」)」の2つに分類されます。
バッチ ETL は、指定された時間間隔でのみデータを抽出し、ストリーミング ETL では、データは抽出可能になり次第、ETL パイプラインを通過します。
変換(Transform)
例えば以下のようなことをするのに、抽出されたデータが既に必要な形式になっていることはめったにありません:
-
非構造化データを構造化形式に再配置する。
-
抽出したデータをいくつかのフィールドに制限する。
-
列がすべて特定の順序になるようにデータを並べ替える。
-
複数のテーブルを結合する。
-
重複したレコードや古いレコードを削除するためにデータをクリーンアップする。
このような変更とそれ以上のことは、すべて ETL の「変換フェーズ」で行われます。データのクレンジングや集計からフィルタリングや検証に至るまで、実行可能なデータの変換には多くの種類があります。
格納(Load)
最後に、データの変換、並べ替え、クリーニング、検証、準備が完了したら、それをデータストレージに格納しなければなりません。その際、最も一般的なデータベースは、BI や分析システムと連携するように設計された一元化されたレポジトリであるデータウェアハウスです。
Google BigQuery と Amazon Redshift は、最もよく使われているクラウドデータウェアハウスソリューションの2つに過ぎませんが、オンプレミスでデータウェアハウスをホストすることもできます。
もう1つの一般的な対象システムには、まだクリーニング、構造化、変換処理を行っていない「未精製」のデータを保存するためのレポジトリである「データレイク」があります。
関連記事:ETL vs ELT: 5つの重要な違い
データ ウェアハウスでの ETL の実装
データをデータウェアハウスに移動するのに ETL プロセスが使われる場合、各フェーズは以下のように個別のレイヤーで表されます。:
ミラー/ローレイヤ
ロジックやエンリッチメントのないソースファイルやテーブルのコピーであり、このプロセスでは、ソースデータを対象のミラーテーブルにコピーして追加し、変換準備が整った過去の生データを保持します。
ステージングレイヤ
ミラーテーブルからの生データが変換処理されると、変換は全てステージングテーブルに集約され、そのテーブルには、進行中の ETL サイクルの増分部分のデータの最終形式が保持されます。
スキーマレイヤ
スキーマレイヤは、クレンジング、エンリッチメント、変換後の最終フォームのすべてのデータを含むデスティネーションテーブルです。
集計レイヤ
場合によっては、完全なデータセットから日または店舗レベルにデータを集約するのが便利であり、これによって、レポートのパフォーマンスが上がり、ビジネスロジックを追加して指標を計算できるようになり、レポート開発者がデータを理解しやすくなります。
ETL が必要な理由
ETL により、データの抽出と準備にかかる時間が大幅に短縮され、その時間をビジネスの評価に有効活用できるようになります。また、ETL の実践は健全なデータ管理ワークフローの一部でもあることから、高いデータ品質、可用性、信頼性が保証されます。
ETL の 3つの各主要コンポーネントで、専用のデータフローで1回だけ実行されれば、時間と開発の労力の節約になります。
抽出
「鎖の強さは最も弱い部分で決まる」という言葉を思い出してください。ETL では、最初のリンクで鎖の強さが決まります。抽出ステージでは、使われるデータソース、各ソースの更新レート(速度)、およびその間の優先順位(抽出順序)が決まり、これらはすべて、インサイトを得るまでの時間に大きく影響します。
変換
抽出の後、変換プロセスで最初のデータスワンプに明瞭さと秩序がもたらされます。日付と時刻は単一のフォーマットに統合され、文字列はその根本にある実際の意味まで解析されます。また、位置データは、座標、郵便番号、または都市/国に変換されます。変換ステップでは、合計、丸め、平均化も行われ、無駄なデータやエラーは削除されるか、後の検査のために破棄されます。そして GDPR(EU一般データ保護規則)や CCPA(カリフォルニア州消費者プライバシー法)、その他のプライバシー要件に準拠するために、PII(個人を特定できる情報)をマスクすることもできます。
格納
最終フェーズでは、最初のフェーズと同様に、ETL でターゲットと更新レートが決まります。格納フェーズでは、格納が段階的に行われるか、または新しいデータバッチに対して「upsert」(既存のデータを更新して新しいデータを挿入する)が必要かどうかも決まります。
最新の ETL でビジネスが得られるもの
「ビッグデータ」は、その規模や量だけでなく、その影響、解釈の可能性、使用例においても、まさにその名の通りのものです。
現代の組織の各部門では、大量のデータから独自のインサイトを得る必要があり、例えば以下が挙げられます:
-
営業チームには、見込み客に関する正確で質の高い情報が必要。
-
マーケティングチームは、キャンペーンのコンバージョン率を評価し、今後の戦略を立てる必要がある。
-
カスタマー サクセス チームは、問題に対処し、顧客サービスを向上させるために、詳細に調査したいと考えている。
従業員に必要なデータを抽出して準備することによって、ETL でこのような問題やその他の問題を解決することができるようになります。また、ETL で、企業データに対するレポート作成や分析ワークフローの実行が、劇的にシンプル、迅速、かつ効率的になります。
こうした多様な要求を満たすことにより、ETL でデータガバナンスとデータ デモクラシーを維持する環境の構築ができるようになります。データガバナンスとは、企業のデータの可用性や使いやすさ、整合性、セキュリティなど、企業データの全体的な管理です。
また、データデモクラシーにより、高度なデータ分析が求められ る社内の全員がデータにアクセスできるようになります。それで習得がしやすくなり、適切な質問をしやすくなり、得られる回答が明確になります。
ETL の仕組み
このセクションでは、ETLプロセスの3つのステップついて、それぞれもう少し深く掘り下げて見ていきましょう。
ETL の実装には、(カスタム DIY コードなどの)スクリプトを使うことも、専用の ETLツール を使うこともできます。そして ETL システムは、以下のような重要な機能を実行します:
解析/クレンジング
アプリケーションによって生成されるデータは、JSON、XML、CSV などさまざまな形式になる場合があります。解析の段階では、データをヘッダ、列、行を持つ表形式にマッピングし、指定されたフィールドを抽出します。
データエンリッチメント
アナリティクス用にデータを準備するには通常、専門家の知識の注入、矛盾の解決、バグの修正など、一定のデータエンリッチメントステップが必要です。
ベロシティの設定
「ベロシティ」とは、新しいデータの挿入や既存のデータの更新など、データの格納頻度のことを指します。
データの検証
場合によっては、データが空であったり、破損していたり、重要な要素が欠けていたりすることがあります。データ検証中に ETL はこのような現象を発見し、プロセス全体を停止するか、データをスキップするか、あるいは人による検査のためにデータを脇に置くかが決まります。
データ抽出
データ抽出には次の4つのステップが含まれます。
1.抽出するデータの特定
データ抽出の最初のステップは、データウェアハウスに組み込むデータソースをの特定です。そのソースは、MySQL のようなリレーショナル SQL データベースや、MongoDB や Cassandra のような非リレーショナル NoSQL データベースからである可能性があり、Salesforce のような SaaS プラットフォームやその他のアプリケーションからの情報である場合もあります。そしてデータソースを特定したら、抽出したい特定のデータフィールドの決定が必要になります。
2.データ抽出のサイズの見積もり
抽出するデータは50メガバイトか、50ギガバイトか、それとも50ペタバイトか、データ抽出のサイズは重要であり、大量のデータを捌くのであれば、さまざまな ETL 戦略が必要になります。例えば、大きなデータセットを「日」レベルではなく「月」レベルに集計することで管理がしやすくなって抽出のサイズが小さくなったり、あるいはより大きなデータセットを処理できるようにハードウェアをアップグレードすることもできます。
3.抽出方法の選択
データウェアハウスは、最も正確なレポートの作成のために継続的な更新が必要であるため、データ抽出は継続的なプロセスであり、分単位で行う必要があります。そして情報の抽出には、主に以下の3つの方法があります:
-
更新通知: 推奨される抽出方法に、更新通知を使用するというのがある。ソースシステムは、レコードの1つが変更されると通知を送信し、それでデータウェアハウスは新しい情報のみでの更新となる。
-
インクリメンタル抽出:更新通知が不可能な場合に使える増分抽出。この方法では、変更されたレコードを識別し、そのレコードのみを抽出するが、潜在的な欠点として、増分抽出では削除されたレコードを常に識別できるとは限らないという点がある。
-
完全抽出: 先の2つの方法がうまくいかない場合、完全抽出によって全データの完全な更新が必要になる。この方法は、小規模なデータセットでのみ実行可能である可能性が高いことに注意が必要。
4.SaaS プラットフォームの評価
企業は以前、会計やその他の記録管理を社内のアプリケーションに依存しており、そのアプリケーションでは、オンサイトのサーバーで管理する OLTP トランザクションデータベースが使われていました。今日では、Google Analytics、HubSpot、Salesforce などの SaaS プラットフォームを利用する企業が増えており、そのプラットフォームからデータを引き出すには、プラットフォーム独自の API と統合するソリューションが必要です。ちなみに、Integrate.io そのようなソリューションの一つとなっています。
このようなクラウドベースの ETL ソリューションは、以下のような方法で一般的な SaaS API からデータを抽出します。:
-
最もよく使われている SaaS アプリケーションのための、すぐに使える API 統合のエンジニアリング。Integrate.io は、すぐに使える API 統合が100以上ある。
-
複雑な REST API をナビゲートし、SOAP を REST に自動変換することもできる。
-
さまざまな SaaS API にあるカスタムリソースとフィールド、および多数の組み込みのリソースエンドポイントを処理するための戦略を作成する。
-
データ接続に失敗した場合、常に更新と修正を提供する。例えば、Salesforce ではユーザーに通知されることなく API が更新される可能性があり、その結果、ソリューションを見つけるのに大混乱が生じる可能性がある。Integrate.io のような ETL プラットフォームだと、SaaS デベロッパーとの関係が構築され、このようなアップデートの事前通知を受け取ることで、予期せぬサプライズを防ぐことができる。
データ変換
従来の ETL 戦略では、ステージングエリア(抽出後)で行われるデータ変換は 「多段階データ変換」ですが、ELT では、データをデータウェアハウスに格納した後に行われるデータ変換は、「ウェアハウス内データ変換 」になります。
ETL と ELT のどちらを選択しても、以下のようなデータ変換が必要になる場合があります:
-
重複排除(正規化): 重複する情報を特定して削除する。
-
キーの再構築: あるテーブルから別のテーブルへのキー接続を描画する。
-
クレンジング: 古いデータ、不完全なデータ、重複したデータを削除し、データの正確性を最大化する。その際、おそらく構文エラー、タイプミス、レコードの断片を削除するための解析が行われる。
-
フォーマットの改訂: 日付/時刻、男性/女性、測定単位など、さまざまなデータセットに含まれるフォーマットを、一貫性のある単一のフォーマットに変換する。
-
導出: 例えば、事業収益の数値から特定のコストや税負担を差し引いてから分析する必要がある場合など、データに適用する変換ルールを作成する。
-
集計: 要約レポート形式で提示できるように、データを収集および検索する。
-
統合: 各要素に標準の名前と定義が与えられるように、データウェアハウス全体で同じデータ要素に適用されるさまざまな名前/値を調整する。
-
フィルタリング: データセット内の特定の列、行、フィールドを選択する。
-
分割: 1つのカラムを複数のカラムに分割する。
-
結合: 複数の SaaS プラットフォームに支出情報を追加するなど、2つ以上のソースからデータをリンクさせる。
-
要約:例えば、特定の営業担当者が行った売上をすべて足して特定の期間の総売上メトリクスを作成するなど、 値の合計を計算することで、さまざまなビジネス指標を作成する。
-
検証: さまざまな状況で従う自動化されたルールを設定する。例えば、行の最初の5つのフィールドが NULL の場合、その行に調査フラグを立てたり、残りの情報と一緒に処理されないようにすることができる。
データ格納
データ格納(ロード)とは、抽出した情報を対象のデータレポジトリに格納するプロセスです。これは継続的なプロセスであり、「フルロード(初めてデータをウェアハウスに格納するとき)」または「増分ロード(新しい情報でデータウェアハウスを更新するとき)」によって行われます。
増分ロードは最も複雑なので、このセクションでは増分ロードに焦点を当てていきましょう。
増分ロードの種類:
増分ロードは、前回の増分ロード以降に現れた情報を抽出して格納しますが、それには以下の2つの方法があります:
1.バッチ増分ロード
データウェアハウスは情報をパケットまたはバッチで取り込みます。大規模なバッチであれば、システムのスピードが落ちるのを防ぐために、日次、週次、月次などのオフピーク時にバッチ格納を実行するのがベストですが、最新のデータウェアハウスでは、Integrate.io のような ETL プラットフォームを使って、分単位で小バッチの情報を取り込むこともできます。これにより、エンドユーザーにとっては、ほぼリアルタイムの更新が可能になります。
2.ストリーミング増分ロード
データウェアハウスは新しいデータをリアルタイムで取り込みます。この方法は、エンドユーザーに(例えば、分刻みの意思決定のためなど)リアルタイムの更新が必要な場合に特に有用ですが、とはいっても、ストリーミング増分ロードはごく少量のデータの更新の場合でしかできず、ほとんどの場合、分単位のバッチ更新は、リアルタイムのストリーミングよりも強固なソリューションを提供します。
増分ロードの課題:
増分ロードは、システムのパフォーマンスを乱し、以下のような多くの問題を引き起こす可能性があります:
データ構造の変化
データソースやデータウェアハウスのデータフォーマットは、情報システムのニーズに応じて進化が必要かもしれませんが、システムの一部分を変更すると、非互換性が生じ、格納プロセスに支障をきたす可能性があります。なので一貫性のないデータ、破損したデータ、不整合なデータに関する問題を防ぐには、適切な調整を行う前に、わずかな変更がエコシステム全体にどのような影響を及ぼすか、拡大して確認することが重要です。
誤った順序でのデータ処理
データ パイプラインは複雑な軌跡をたどることがあり、その結果、データウェアハウスで情報が間違った順序で処理、更新、または削除される可能性があります。それで情報が破損したり不正確になったりする可能性があることから、データ処理の順序の監視や監査が重要になります。
問題検出の失敗
例えば、API がダウンした場合や、API アクセス認証情報が古い場合、システムの速度低下によって API からのデータフローが中断された場合や、対象のデータウェアハウスがダウンした場合など、ETL ワークフローの問題を迅速に検出することは非常に重要であり、問題の検出が早いほど、より早い修正ができ、その問題が原因で生じる不正確または破損したデータを修正しやすくなります。




